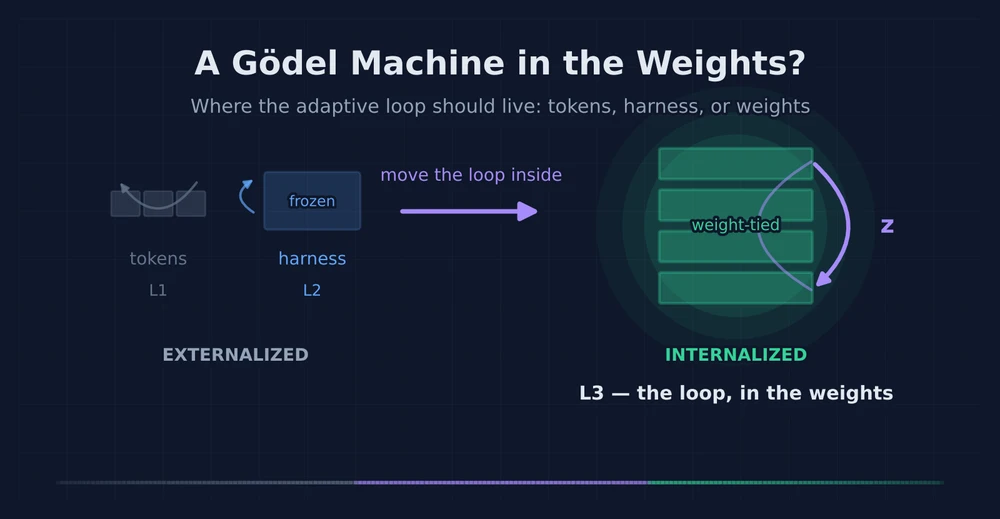
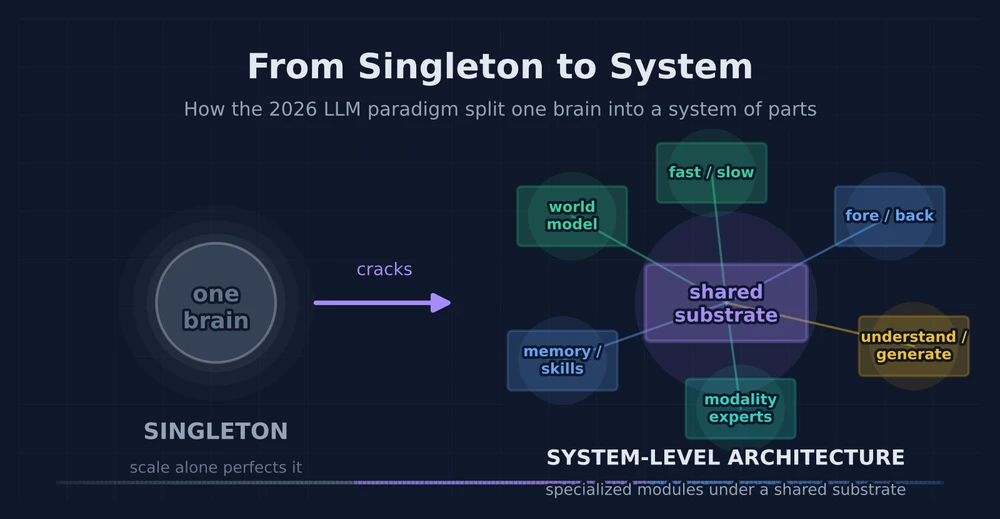
AGI Envision: from the monolithic Singleton to a System-level architecture. The open question of whether ARC-AGI-3 and starting a company require the shift.
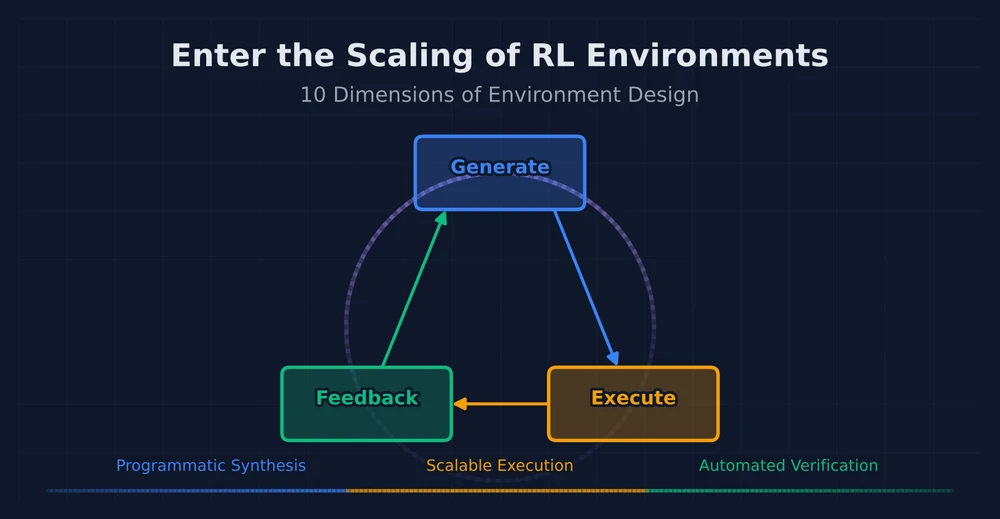
13 interactive puzzle games with 1,872 levels inspired by The Witness, compatible with ARC-AGI-3 SDK and RL-ready via OpenEnv — an open-source training ground for teaching machines fluid intelligence
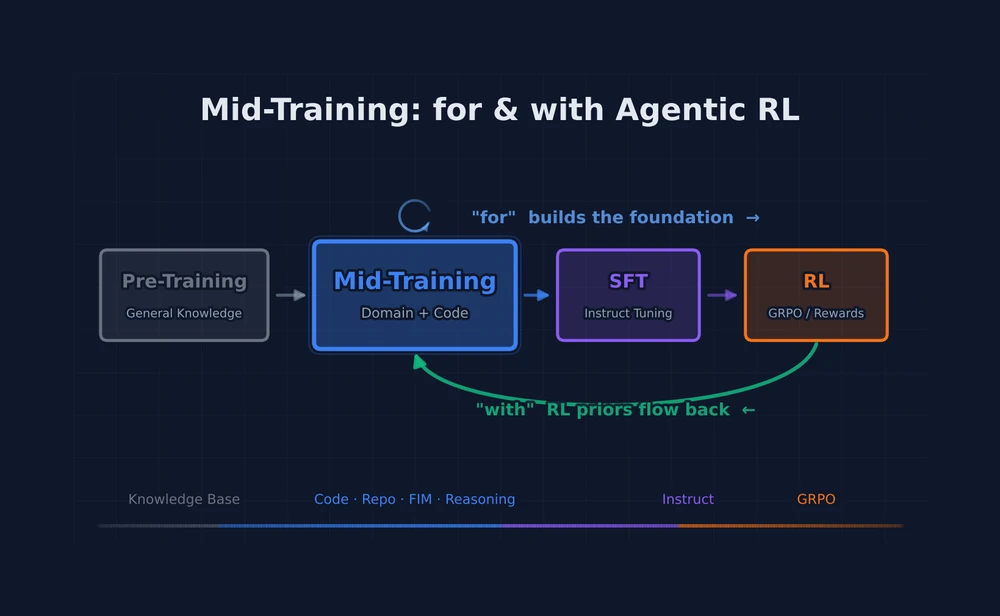
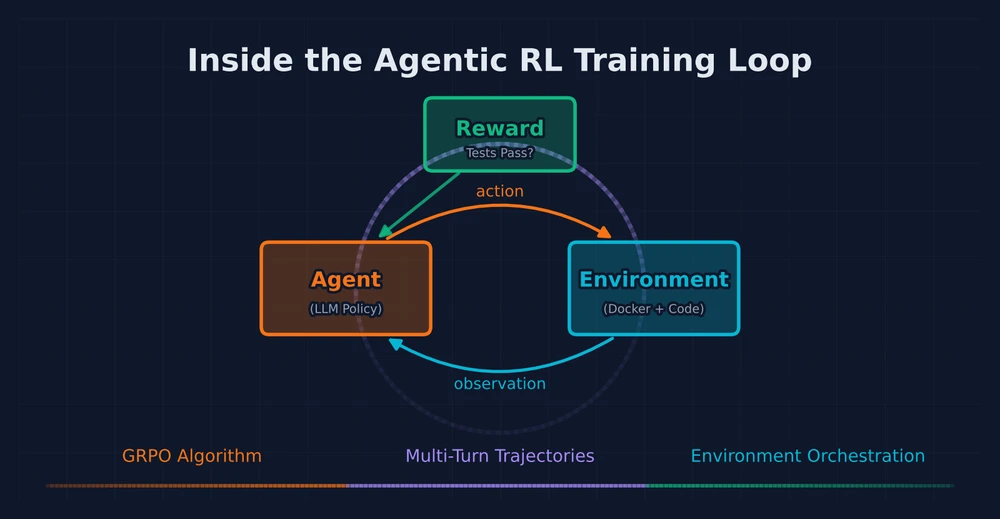
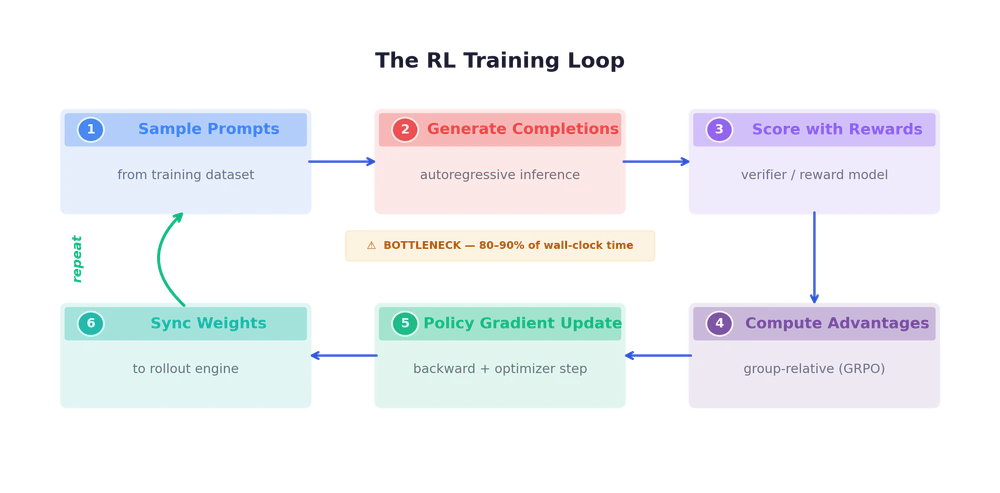
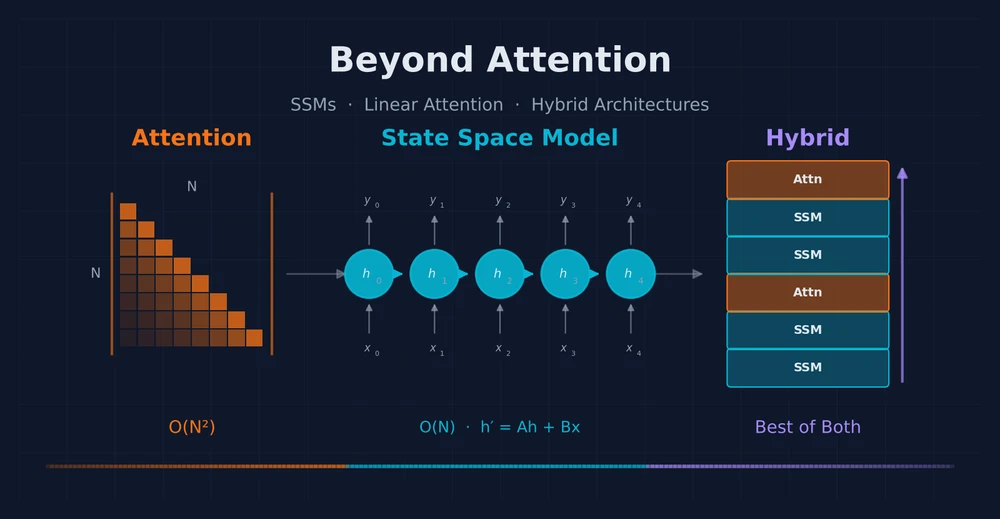
Re-examining mid-training as the strategic centerpiece of the LLM pipeline — how it builds the knowledge foundation for agentic RL, and how RL signals are now flowing backward to improve mid-training itself