For four years we bet that one brain, scaled enough, would become all of intelligence. In 2026 the brain we built started asking for help: a second module to hold what it couldn’t be in two places to do, a notebook to remember what it kept forgetting, a methodology it was never born with. This post is about the moment the Singleton became a System.
This post started as a single question I couldn’t shake: is Qwen3.5-Omni actually “native” multimodal, or is it a very good imitation of one? Pulling that thread led to a second question. What does Thinking Machines Lab mean when it says interaction should be a model’s own capability and not a scaffold around it? Then a third, and a fourth, until I was no longer asking about any one model. I was looking at a pattern. The frontier of LLM research in 2026 has quietly stopped being about making one model bigger. It has started being about composing a system. Pieces of that shift already have names (compound AI, agentic workflows, the harness), but they are rarely connected into one story spanning perception, interaction, methodology, and world models at once.
So this is my attempt to tell it as one story. I’ve spent the last stretch reading across four bodies of work that rarely get read together: native/omni multimodal models, real-time interaction models, agent harnesses, and world models. The thesis that fell out is this:
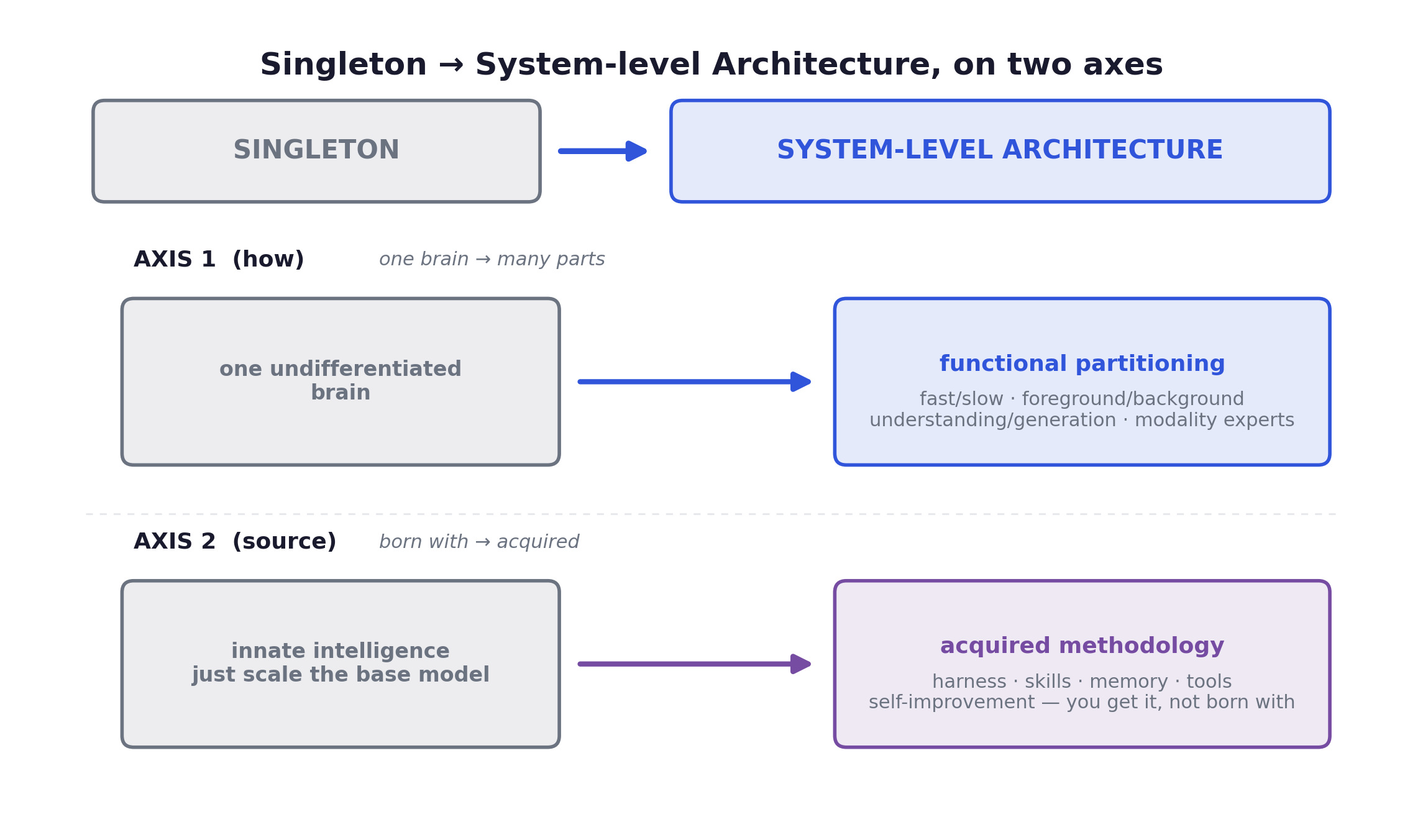
In 2026 the dominant LLM paradigm has been shifting from the Singleton (one all-purpose monolithic brain that scale alone was supposed to perfect) toward a System-level Architecture.
The shift runs along two axes.
Axis 1, architecture: from a single undifferentiated brain to functional partitioning. Specialized modules (fast and slow, foreground and background, understanding and generation, modality experts) cooperate under a shared substrate.
Axis 2, capability: from innate intelligence, where you just scale the base model, to acquired methodology: harness, skills, memory, tools, self-improvement. Capability you assemble, not capability you’re born with.
Underneath both axes runs a quieter thread that I think is the most interesting question in the field: how does capability get internalized? When methodology lives outside the weights, in a harness, a tool, a note, does it ever move inside, and should it? Is full internalization the endgame, or should a mind keep an external brain the way humans keep notebooks? Should AGI be fully human-like at all? A machine can keep a notebook that is exact, unbounded, and cloneable, and so surpass the biology it’s accused of imitating.
I’ve tried to write this so two kinds of reader get something from it. If you know transformers, pretraining and post-training data, and RL infrastructure cold, but the frontier of multimodal/interaction/world-model architecture is a place you’ve been meaning to visit, this is a guided tour, on-ramp first. If you already live in one of these subfields, I’m betting the cross-field synthesis shows you something your corner doesn’t see alone: the same partition appearing in four places that have never shared a benchmark.
What this post covers:
Part I. The two expansions of the monolith (and the walls they hit):
- The First Expansion: bolt-on senses → a native multimodal mind (Qwen3.5-Omni as the worked example), and the first crack
- The Second Expansion: turns → real-time, full-duplex presence, and the latency-vs-depth wall
Part II. The paradigm shift:
- The Singleton Hypothesis, and Why It Cracks: two unrelated fields, one partition, and the thesis it points to
- Axis One — Architecture: from a single brain to functional partitions under a shared substrate
- Axis Two — Capability: from innate intelligence to acquired methodology
Part III. Reading the shift:
- Is This the Brain, Reinvented?: the cross-domain audit against neuroscience and cognitive science
- The Hidden Thread: how capability becomes native, and why full internalization isn’t the goal
- The Substrate Underneath: world models and abstraction-switching
Part IV. The frontier:
- The Open Question: ARC-AGI-3, starting a company, and whether cracking them needs the System
One note on framing. I treat “Singleton → System” as a thesis, not a settled result. I’ll argue it, show you the evidence that convinced me, and flag the places where a scaled Singleton might still surprise us.
Let’s start where I started: with a language model that just got eyes.
1. The First Expansion: From Bolt-on Senses to a Native Mind
The question native multimodality answers is simple: is the capability grown into the model, or bolted onto it?
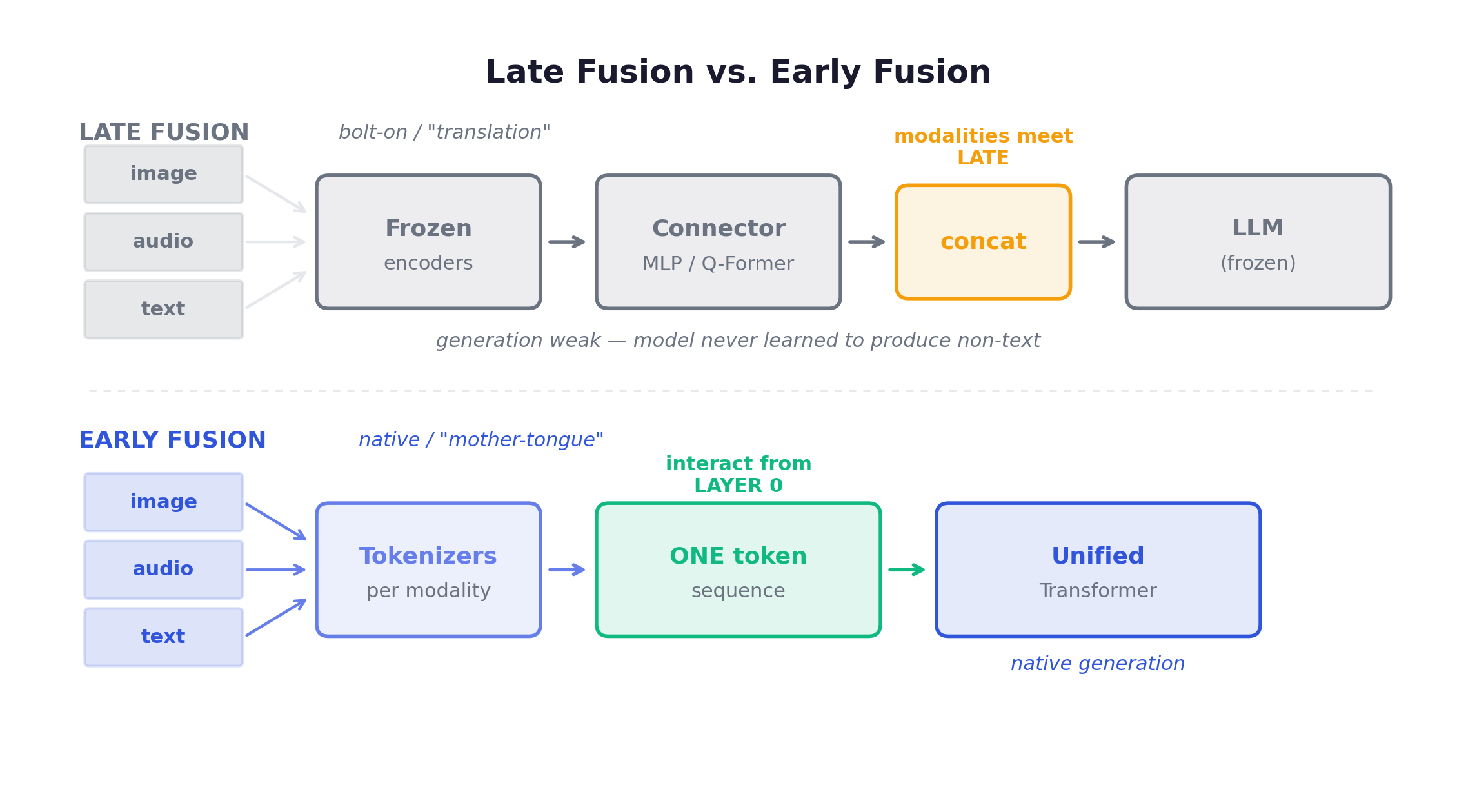
Start with the moment a language model “got eyes.” For a few years that phrase meant something modest. You took a frozen vision encoder (CLIP, SigLIP, a ViT) and a frozen LLM, and trained a thin bridge between them: a projection MLP, or a Q-Former. A few hundred million parameters of glue while the two billion-parameter giants never moved. NExT-GPT (NUS, 2023-09) is the canonical specimen: an any-to-any system stringing frozen encoders, a frozen LLM, and external diffusion decoders together, fine-tuning only ~1% of its parameters, essentially just the projection layers. It works, and it is cheap. Architecturally, it is a translation booth.
That metaphor carries the whole chapter. Late fusion is translation: it renders each modality into a language the LLM can already read. Early fusion is mother-tongue: every modality speaks the same token-language from birth. In late fusion, vision and audio are guests who learned the LLM’s tongue well enough to be understood at the door. Cross-modal interaction happens late, only after each stream is pre-digested into LLM-compatible embeddings. Generation stays weak because the model never learned to produce anything but text. The senses are bolted on.
What “native” actually buys you
The native move is to refuse the translation layer. You quantize everything (image patches, audio frames, video) into a unified discrete vocabulary, feed it all as one token sequence into one Transformer, and train with one next-token cross-entropy loss from pretraining day one. This is the perception side of the thesis: one shared substrate, where modalities interact at layer 0 instead of being concatenated after the fact.
This is more than aesthetics because of the second-order payoff. Once every modality is just tokens, the single shared brain inherits the entire LLM engineering stack for free: KV cache, sampling, speculative decoding, RLHF, scaling laws. Emu3 (BAAI, 2024-09) made the point with a slogan, “Next-Token Prediction is All You Need,” and a result: a pure discrete autoregressive model that beat SDXL on image generation and LLaVA-1.6 on perception simultaneously, with no diffusion anywhere. Chameleon (Meta FAIR, 2024-05) trained the early-fusion baseline from scratch on ~10T interleaved tokens, mixing image VQ tokens and text tokens in one stream. It had to invent stabilization tricks (QK-Norm, norm-reordering) just to keep that mixed-modal training from diverging: fusing modalities this deeply is not a free lunch. Gemini 1.0 (Google DeepMind, 2023-12) was the first major lab to brand native joint pretraining as the selling point. GPT-4o (OpenAI, 2024-05-13) gave it a consumer face, the “o” for omni, with native end-to-end audio/vision/text at ~320ms average speech latency. Their architectures are undisclosed; everything here is inferred from behavior, not documentation.
So far this reads like a clean win for the monolith. The moment you put everything in one brain, though, it starts fighting itself.
The first internal fault line: understanding vs. generation
Understanding and generation have opposite granularity needs. Understanding wants high-level abstract semantics: what is in this image, what does it mean. Generation wants low-level pixel detail: what exact color is this shadow. Force both through one shared visual representation and it pleases neither end. Chameleon’s single shared visual encoder demonstrably underperforms on understanding for exactly this reason. That is the empirical motivation for everything after.
The industry’s response is a ladder of decouplings, each cutting the partition deeper into the network: splitting the encoder (Janus’s SigLIP-for-understanding + VQ-tokenizer-for-generation), then parameters inside the network (BAGEL’s Mixture-of-Transformers, modality experts under one shared attention), then the training objective (Transfusion’s AR-text + diffusion-image), then the output stream (Thinker-Talker). I lay that ladder out in full in Chapter 4, where it becomes the spine of the architecture story. The industry never eliminated the interference. It engineered partitions to dodge it. No scheme has shown unified training makes understanding and generation mutually reinforce each other. We only know hard-sharing drags them down, so we wall them off, which is itself in tension with the point of a unified model. The partitions are mitigations, not cures.
Thinker-Talker, and the Qwen3.5-Omni worked example
The deepest rung is stream decoupling, and the Qwen-Omni line is the place to study it. The design is called Thinker-Talker. A Thinker (the reasoning LLM) emits the text token stream; a Talker (a dual-track AR model) generates audio codec tokens. The crucial detail: the Talker consumes the Thinker’s hidden states, not its final text tokens. Speech inherits the thought before it has collapsed into discrete words, and text and speech stream in parallel without interfering.
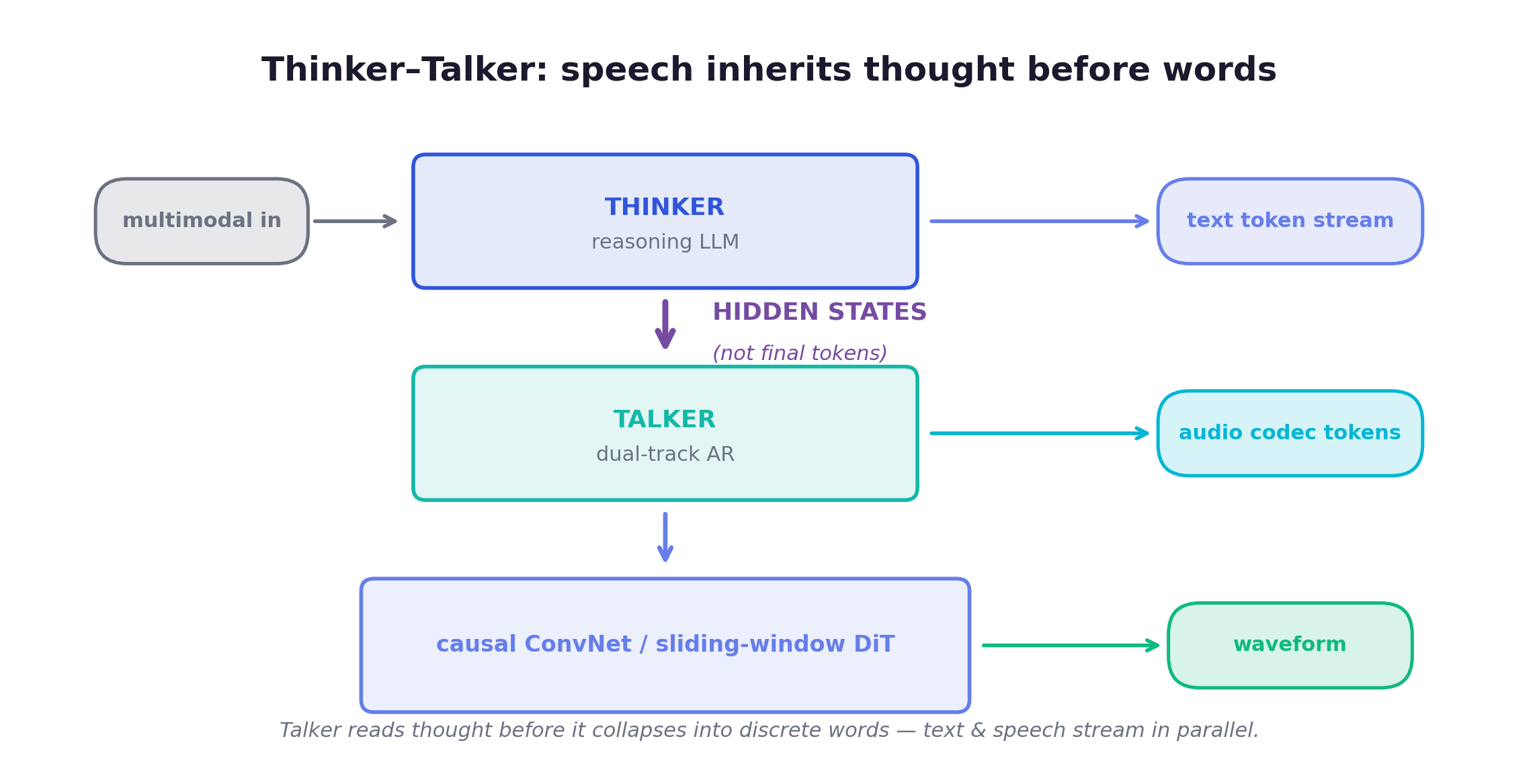
Qwen2.5-Omni (2025-03) introduced this alongside TMRoPE (a time-aligned multimodal RoPE) and a sliding-window DiT streaming detokenizer; Qwen3-Omni (2025-09, 30B-A3B) then MoE-ified the design (mixture-of-experts) and replaced Whisper with a from-scratch audio encoder. Qwen3.5-Omni (2026-04, Plus and Flash variants, sparse MoE into the hundreds of billions of parameters) is the worked example for this chapter, because it pushes the same idea further on every axis:
- Both the Thinker and the Talker are Hybrid-Attention MoE, stacking the functional partition (think vs. speak) on the compute partition (sparse experts). The hybrid attention folds in a Gated Delta Net path, the linear-attention trick the report credits for cheaply modeling long audio-video and keeping a 256k-token, 10-hour-audio context affordable.
- The audio front-end is a from-scratch AuT (Audio Transformer), now trained on a reported 40M hours of audio-text data spanning 113 languages. The senses are not a borrowed Whisper; they are grown in-house and at scale.
- Generation fans out into its own specialists: a multi-codebook codec for single-frame, immediate synthesis, an ARIA module that aligns text and speech mid-stream, a lightweight MTP head for the residual codebooks, and a separate Code2Wav renderer. Understanding (a SigLIP2 vision encoder, the AuT audio encoder, the text tokenizer) feeds one shared Thinker.
And it confronts the central fear of the native program: does merging all modalities sacrifice single-modality skill? Qwen3.5-Omni claims no degradation on text and vision relative to the same-size single-modality Qwen models, while topping most of 215 audio and audio-visual subtasks (per the technical report, treated here as vendor claims). The claim that matters isn’t the leaderboard; it’s the direction: senses internalized into the weights rather than bolted on, without the brain forgetting how to read. So is Qwen3.5-Omni actually native, or a very good imitation? It is native in the way that counts: the modalities are co-trained into one substrate, not translated at the door. But look at what “native” already contains: a Thinker and a Talker, both MoE-split, plus separate vision and audio encoders, an MTP head, and a codec renderer, all hidden-state-coupled under one backbone. It is not a single undivided mind. It is a system, and that is the whole post visible in one model.
One footnote, because it threads into the next chapter. The latency floor in this stack is physical: the codec frame-rate sets it. Kyutai’s Mimi codec, the ancestor of these streaming decoders, runs 24kHz down to 12.5Hz / 1.1kbps with ~80ms streaming latency. You cannot reason your way under the frame rate. Time itself is a wall the monolith hasn’t conquered.
The first crack: long video breaks the single brain
Everything above is the monolith expanding: bigger vocabulary, deeper partitions, more modalities, still one model. Now it cracks.
Long-video reasoning imposes a demand that is mutually exclusive. Broad temporal coverage needs many frames at low resolution. Fine-grained spatial grounding needs few frames at high resolution. One model on a fixed token budget cannot have both: the same tokens fight over two incompatible jobs. This is a resource conflict baked into the geometry of the problem, not an inconvenience you optimize away.
Omni-R1 (Zhejiang University + Ant Group, NeurIPS 2025) is the moment the monolith visibly fractures into a system. It splits the task across two online-collaborating systems:
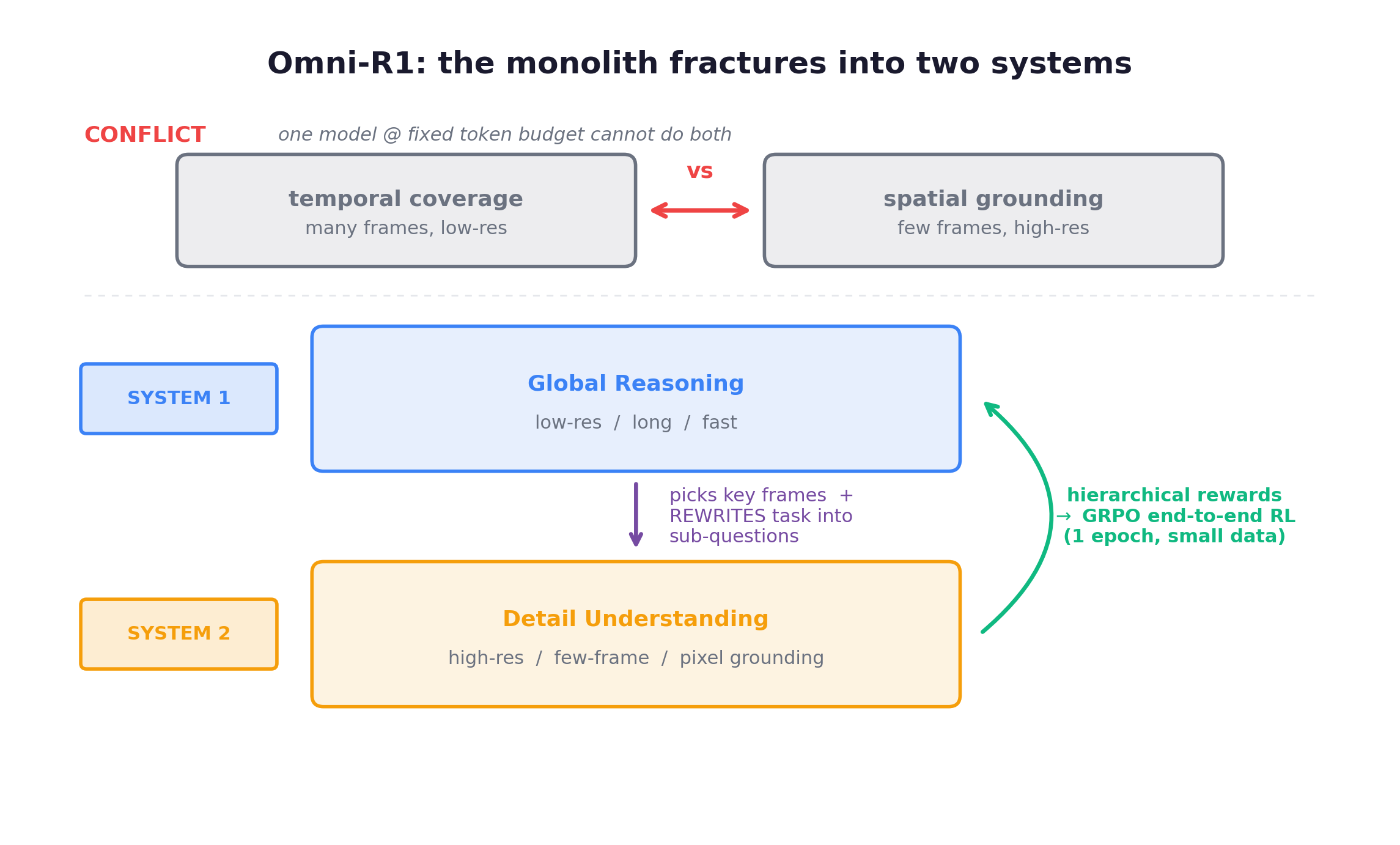
A System-1 Global Reasoning module does fast coarse reasoning over the low-res long video, selects the key frames, and rewrites the task into sub-questions. A System-2 Detail Understanding module, an off-the-shelf MLLM, does pixel-level grounding on the few high-res clips. They produce hierarchical rewards and train end-to-end with GRPO (Group Relative Policy Optimization), one epoch on small data, billed as the first successful use of RL for large-scale omnimodal reasoning. It beats task-specific SOTA on RefAVS/REVOS, reduces cross-modal hallucination, and improves out-of-domain generalization where SFT typically hurts it.
Two things make this the hinge of the chapter. First, what System-1 actually is: a learned context-aware selector and task-rewriter wrapped around a frozen System-2. That is scaffolding, a harness, our first sighting of the post’s second axis, where capability comes not from a bigger base model but from methodology bolted around the model. Second, and I return to this verdict in Chapter 3, the very fact that the two-system split wins signals the single model can’t yet reconcile its conflicting demands alone. This same fast/slow, System-1/System-2 partition recurs in robotics VLA stacks and is already realized in decoupled serving infra, which is why I read it as a convergent structural answer, not a one-off hack.
Short term, the two routes are complementary, not winner-take-all. The unified model remains the general perception/generation backbone; the system layer schedules the conflicting precision-versus-coverage demands the backbone can’t satisfy at once. But the crack is real, and it is the first time in this post that the monolith stops being one brain.
We’ve now unified the senses in space: many modalities, one substrate, partitions to keep them from strangling each other. The harder axis is the one that just bit us at the codec frame rate. The monolith has no sense of wall-clock time, only token order. In the next chapter, the single brain has to master time: real-time, full-duplex presence, where a human conversation tolerates barely 200 milliseconds of silence.
2. The Second Expansion: From Turns to Real-Time Presence
The classic language model lives in logical time. It cares only about token order, never whether fifty milliseconds or five minutes passed between two of them. An interaction model is plugged into the wall clock, and the wall clock is unforgiving.
The first expansion pushed the monolith outward, to swallow pixels and waveforms into one token stream. The second pushes it forward in time, into a physical wall the single forward pass cannot argue past.
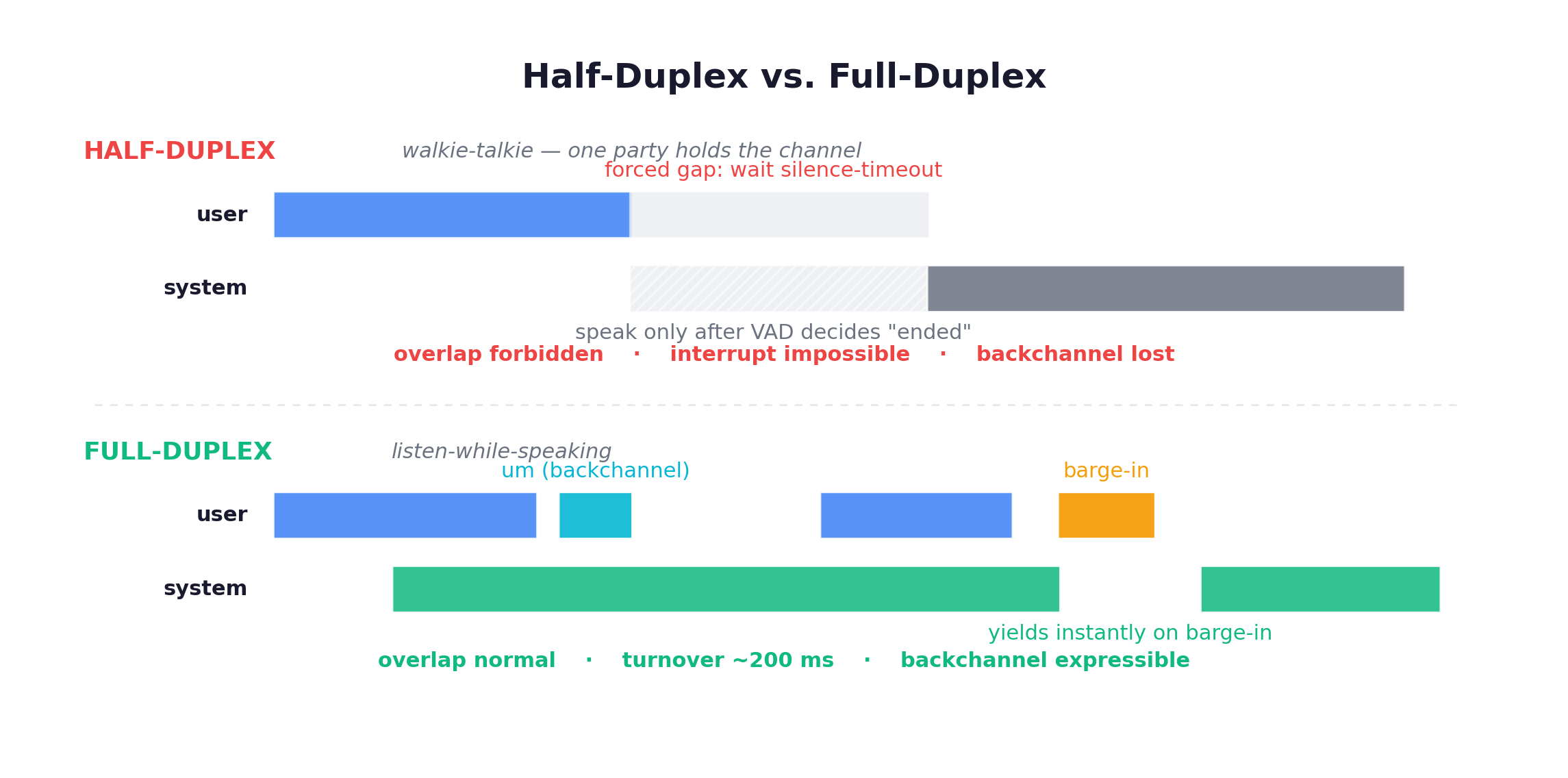
Start with the interface almost every chat product still ships. You speak, it listens, it thinks, it answers: four steps, strictly serial, mediated by glue. A voice-activity detector (VAD) decides you have started talking. An endpointer waits for ~700ms–1s of silence to decide you have stopped. Only then does the model think. This is half-duplex, the walkie-talkie: one party holds the channel at a time, and “who may speak” is a mutex lock.
I used to think half-duplex was just slow full-duplex, closing the gap with faster hardware. It isn’t. Half-duplex has three defects that are structural, not speed-related:
- Latency accumulation. The endpointer’s silence timeout is a floor you cannot optimize below. You wait for silence to prove the turn ended, because the architecture has no other way to know.
- Irreversible loss of paralinguistic information. The cascade runs ASR → NLU → dialogue manager → NLG → TTS. The first stage compresses your hesitant “um… (rising intonation, half a beat)” into three characters:
um. The backchannel, the yield signal, the prosodic cue that you are about to finish are destroyed before the model ever sees them. - Structural inability to model overlap. With a mutex lock on the channel, simultaneous speech is not handled badly. It is undefined. And per Full-Duplex-Bench v1.5 (NTU/Berkeley/MIT, 2025-03), over 40% of real conversational turns contain some overlap: backchannels, barge-ins, collaborative completions.
So half-duplex is not slower full-duplex. At the architecture layer it deletes an entire class of human signals. No GPU helps, because the information is gone before inference begins.
The ruler is drawn by humans
Why does everyone converge on 200ms? It is not an engineering preference but a biological constant. Stivers et al. (MPI Nijmegen, PNAS 106(26):10587–10592, 2009) measured turn-transition gaps across ten languages and found them modal at 0–200ms, shorter than the ~600ms a speaker needs just to plan an utterance. The math only works if listeners predict the turn-end before the speaker finishes and launch their reply into a slot they anticipated. That predictive turn-taking is what we read as “presence.”
So every serious system aligns to the same ruler: SyncLLM’s 160–240ms chunks, Moshi’s ~200ms, TML’s 200ms micro-turn. Pushing end-to-end latency to ~200ms literally reproduces the constant Stivers revealed.
The lineage: making time a token
The path to real-time presence is a 17-year arc of moving synchronization out of the scaffold and into the weights. Schlangen & Skantze (2009) made the conceptual move with incremental processing: don’t wait for the turn to finish to process. dGSLM (Meta/Inria, 2022-03) showed dual-channel neural dialogue where overlap and laughter emerge with no external VAD. Then the modern lineage crystallized:
| System | Org / date | The move it added |
|---|---|---|
| Moshi | Kyutai, 2024-09 | First real-time full-duplex speech-text foundation model. Dual audio streams + “inner monologue” (predict the text token before speaking it). Mimi codec at 12.5Hz; ~200ms measured latency. The hub of the lineage, and the full-duplex system TML leans on most. |
| SyncLLM | UW / Meta, 2024-09 | Periodic sync tokens snap Llama3-8B’s autoregressive beat to the physical clock; 160–240ms chunks. The most direct academic precursor to TML’s micro-turn. (arXiv:2409.15594) |
| hertz-dev | Standard Intelligence, 2024-11 | 8.5B open model treating full-duplex as the pretraining objective itself. ~20M hours audio; theoretical ~80ms latency floor (the physical-layer reference). |
| GPT-4o Realtime | OpenAI (base 2024-05; gpt-realtime GA 2025-08-28) | The industrial product form: one WebSocket, server auto-handles interruption. Audio response min 232ms / mean 320ms, clearly above the 200ms human bar. “Good enough” vs “human-rhythm” is exactly this 100ms gap. |
The conceptual key is the micro-turn. Instead of an external scheduler asking “should I speak now?”, you fix a ~200ms chunk grid and let chunk position itself carry wall-clock time. Now plain next-token prediction reproduces turn-taking for free, and the synchronization that lived in VAD + endpointing + a scheduler is internalized into the weights. That is the quiet thread under this entire blog: external scaffolding becoming intrinsic, in-parameter capability. VideoLLM-online (2024-06) did the same on the proactivity side, emitting a silence token on most frames and generating content only when speech is worth it. “When to respond” becomes a gradient-optimizable autoregressive decision, not a rule. The same correct sentence said two seconds early is an intrusion; said two seconds late, a dereliction. Proactivity is a timing problem wearing a content problem’s clothes.
The anchor: TML’s Interaction Models (2026-05)
This brings us to the system I want to anchor on: Thinking Machines Lab’s “Interaction Models: A Scalable Approach to Human-AI Collaboration” (research preview, 2026-05-11). It is not a novel singleton breakthrough. When I traced its claims, nearly every component resolves to a pre-existing, independently-published source. It is a faithful synthesis, not a sudden frontier demo. Its headline configuration is reported as a 276B-parameter MoE with ~12B active, but treat this as blog-claimed, not independently reproduced. The same hedge applies to its internal TimeSpeak / CueSpeak evals, whose names and scores I would not cite as fact.
What it synthesizes:
- Encoder-free early fusion. Audio enters as dMel spectrogram features through a lightweight embedding, deliberately not a Whisper-scale encoder. Video is cut into 40×40 patches via hMLP. Audio output comes from a flow head (flow-matching, Lipman et al. 2022) trained from scratch with the backbone, with no bolted-on vocoder. The principle is the Bitter Lesson applied to ingestion: each independent encode/decode stage you remove is one serial latency segment and one error-accumulation point removed. The lineage (Fuyu, EVE, Chameleon, Apple’s native-multimodal scaling laws) is the first-expansion thread from Chapter 1, now serving latency.
- Batch-invariant deterministic inference. A prerequisite I’ll return to.
- The 200ms micro-turn, as above.
- The foreground/background dual model, which is the monolith cracking in real time.
The crack: foreground and background
Here is the contradiction. A single network cannot simultaneously reply in 200ms and reason deeply for several seconds. These are not two settings on one dial; they are mutually exclusive demands on one forward pass. The brain must choose: fast and shallow, or deep and slow.
So you split it:
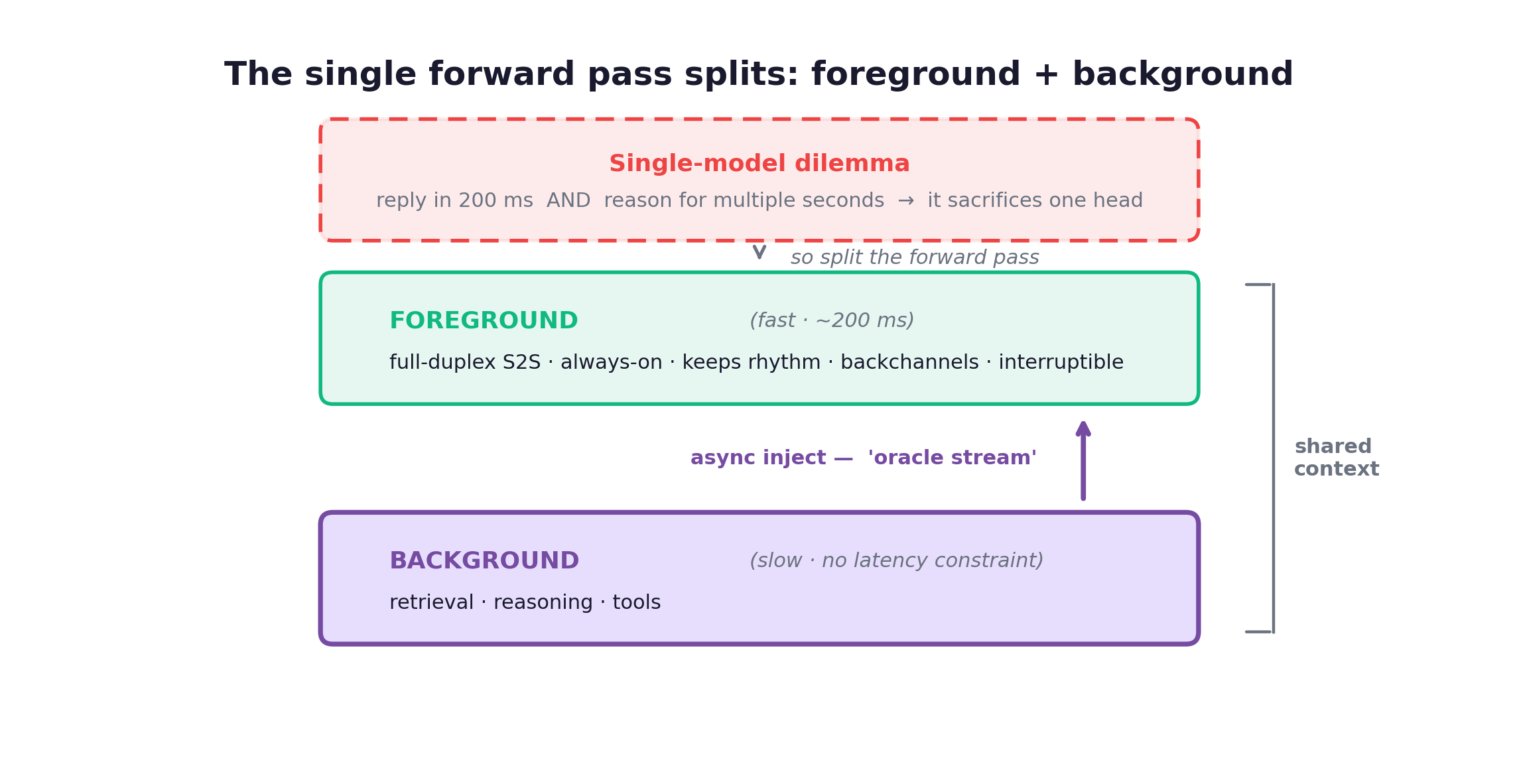
This is not TML’s invention either. KAME (Sakana AI, 2025-10) put a real-time foreground speech model in front of a heavy async background LLM and injected the conclusion back as an “oracle stream,” predating TML by over half a year and proving responsiveness and full intelligence need not be either/or. MoshiRAG (Kyutai, 2026-04) is KAME’s mirror image: where KAME’s background reasons, MoshiRAG’s retrieves, firing an async lookup only when a trigger token signals a fact is about to be needed. And Dispider (CUHK/Shanghai AI Lab, 2025-01, CVPR 2025) ran the identical split on the visual side: perception, decision, and reaction as three async modules, so the model keeps watching the video while a separate module generates the reaction.
The dual model is also the clearest answer here to a question I keep circling: should everything be internalized? I don’t think so. The foreground internalizes only the necessary kernel of timing, turn-taking, and presence. Deep knowledge stays in an external, async, swappable background brain that can be made arbitrarily large and deep while the foreground’s latency budget stays pinned at 200ms. That is an external memory unbounded by the real-time clock, an “extended mind” that need not obey the foreground’s biological-rhythm constraint at all.
It is not free. The unresolved cost is the consistency reef:
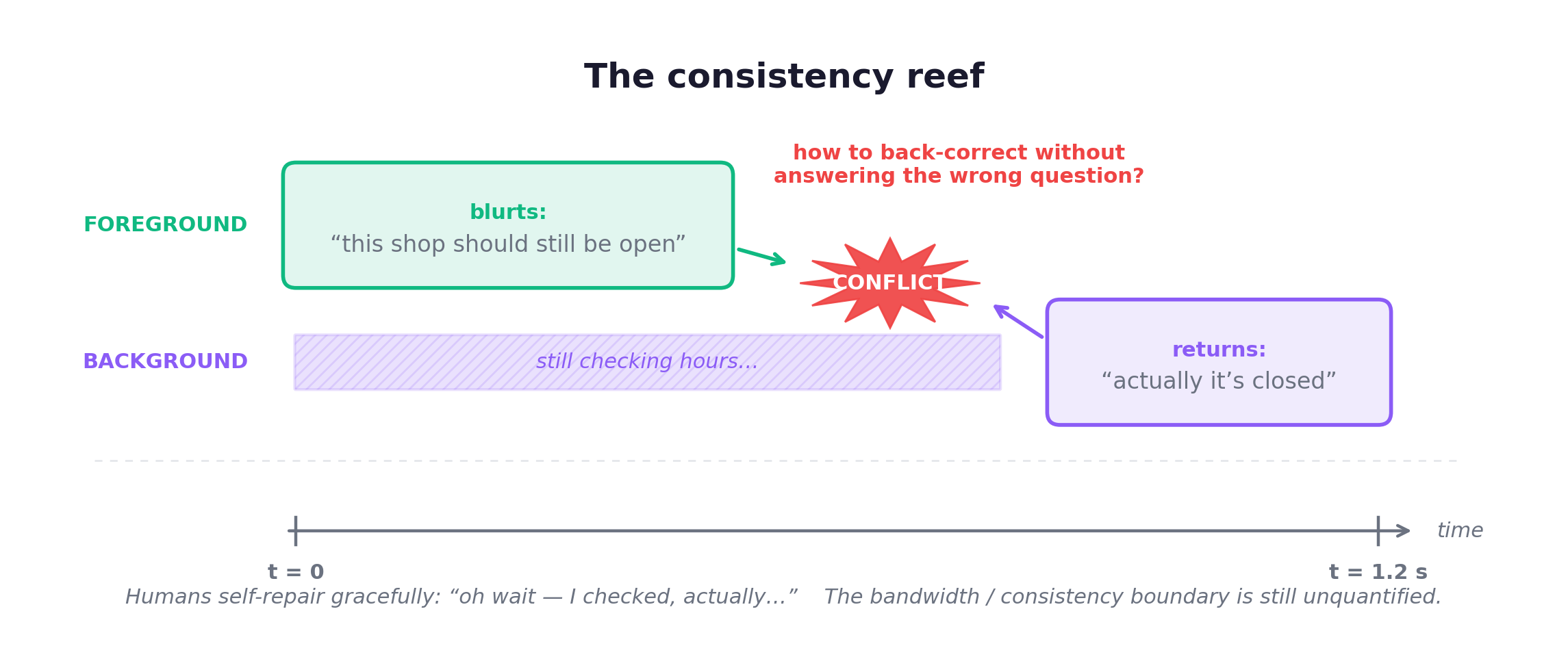
The bandwidth and consistency boundary between the two minds is, as of this writing, completely unquantified. Collaboration is not stapling two models together. It is keeping them from slapping each other in the face on the same timeline.
One more brick: why determinism is load-bearing
Real-time RL-trained interaction depends on deterministic inference, and TML’s own “Defeating Nondeterminism in LLM Inference” (Horace He et al., 2025-09) showed the cause was misdiagnosed for years. It is not GPU atomic adds; the forward pass has none. It is that continuous batching lets batch size drift with server load, which changes reduction order, which floating-point non-associativity turns into numerical drift. Qwen3-235B at temperature 0, over 1000 runs, produced 80 distinct completions. With batch-invariant kernels, all 1000 were identical, at roughly 2× cost (self-reported; hedge the sub-numbers). Why does an interaction model need this? Because when the sampler and trainer differ numerically, on-policy RL silently drifts off-policy, and learning when to interrupt and when to yield leans heavily on online RL. There is a philosophical seam here: the 200ms target makes the system converge onto a human biological constant, while deterministic inference makes it surpass biology, with perfect, reproducible, cloneable behavior no human can match.
The wall
Two independent communities, full-duplex speech and streaming video, arrived separately at the same structural conclusion: you cannot get 200ms presence and trillion-parameter deep reasoning out of one forward pass. The resolution in every case was the same move: a fast always-on foreground, a slow async background, sharing context. The wall is physical. The crack is architectural. And the crack looks like the one Chapter 1 found when the monolith tried to generate as well as understand.
Two unrelated fields just split one brain into a fast part and a slow part. That is not coincidence. That is the Singleton cracking, and the next chapter steps back to read it as one.
3. The Singleton Hypothesis, and Why It Cracks
We spent four years betting that one brain, fed enough of the world, would wake up knowing everything. It woke up and asked for a second brain to hold the parts it could not do in two places at once.
For most of 2020 through 2024, the field ran on one dominant hypothesis. I’ll name it now, because the rest of this post is about watching it break.
The Singleton Hypothesis
The Singleton Hypothesis: one monolithic model, scaled enough, becomes AGI by itself. One network, one set of weights, one forward pass. Pretrain it on enough of the world, post-train it enough, scale it to enough parameters and context, and every capability falls out as an emergent byproduct of that single scaling axis.
This was not naive. It was the disciplined reading of Sutton’s Bitter Lesson: don’t engineer structure into the model, because hand-built structure always gets steamrolled by general methods plus compute. Every time researchers added inductive bias, a parser, a planner, a pipeline of specialized stages, scale eventually ate it. So the rational bet was to refuse to engineer structure at all: make the brain bigger and more uniform, and let intelligence be one undifferentiated thing.
The two preceding chapters were the Singleton’s two most ambitious attempts to expand into new territory, and the two places where it hit a physical wall.
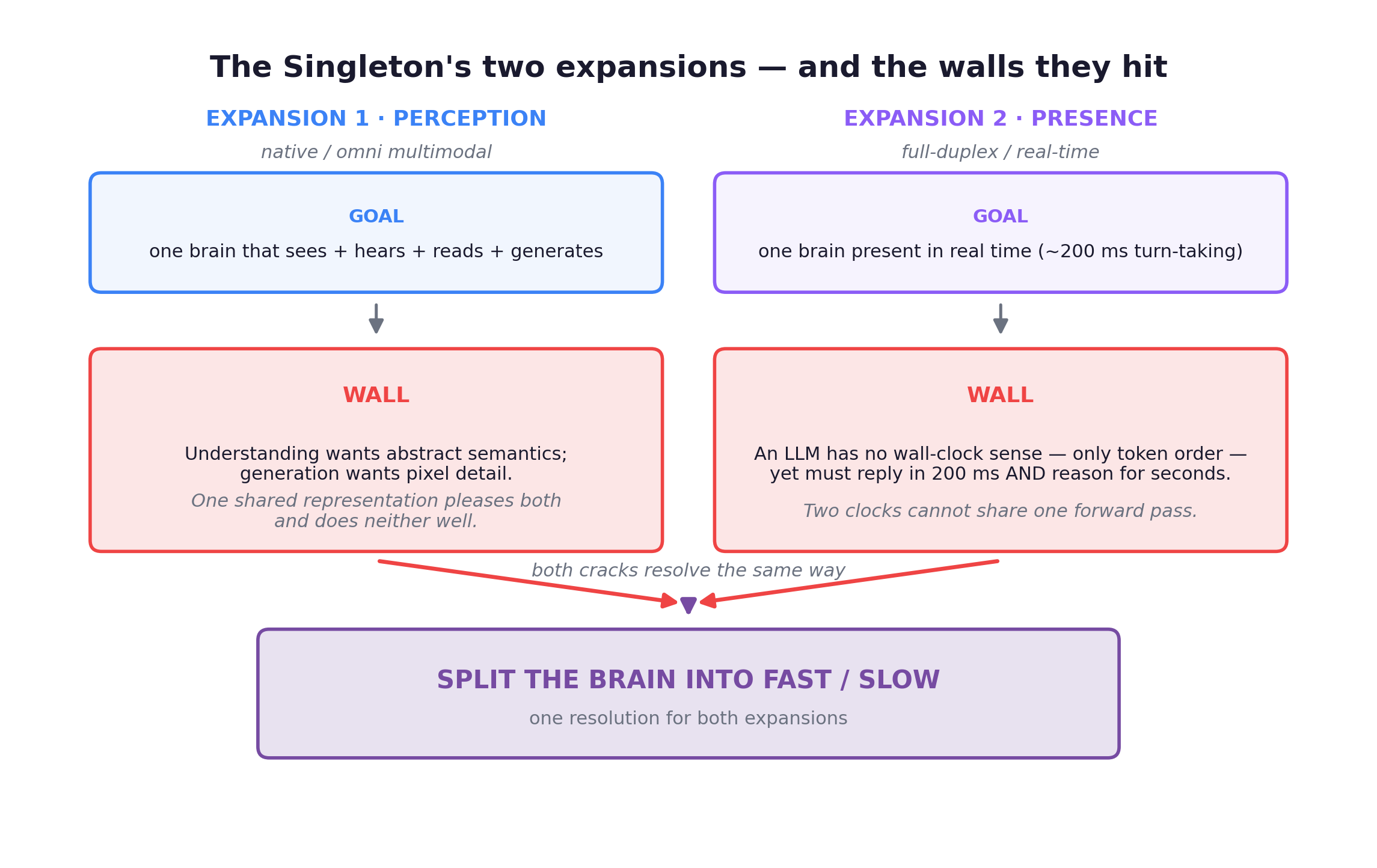
The decisive evidence: two fields, one partition
The same fast/slow split appeared independently in two unrelated subfields, neither aware it was reproducing the other. That is why I think 2026 is a genuine inflection rather than another incremental year.
In native multimodality, the wall is the understanding–generation interference problem from Chapter 1: the two want opposite things. The sharpest instance is long-video reasoning, where temporal coverage (many low-res frames) and fine grounding (few high-res frames) fight over one token budget. So the monolith cracked. Omni-R1 (Zhejiang University + Ant Group, 2025-05, NeurIPS 2025) split the task into a fast Global Reasoning System that picks key frames and rewrites the task into sub-questions, feeding a slow Detail Understanding System that grounds the few high-res clips. It trained end-to-end with GRPO and hierarchical rewards, beat task-specific SOTA on RefAVS/REVOS, and improved out-of-domain generalization. I read the system camp’s victory as itself a sign that the single model cannot yet reconcile all its conflicting demands alone.
In interaction modeling, the wall is latency vs. intelligence. A network hard-bounded by a ~200ms micro-turn cannot also spend multiple incompressible seconds reasoning; one forward pass means making the fast time scale wait for the slow one. So the monolith cracked the same way. The lineage predates the Thinking Machines Lab “Interaction Models” blog (TML, 2026-05) that synthesized it. A foreground model stays always-on, interruptible, real-time-present; a background model does unconstrained async reasoning, retrieval, and tool use, with results flowing back through an “oracle stream.” KAME (Sakana AI, 2025-10) built the oracle stream. MoshiRAG (Kyutai, 2026-04) built the async-retrieval variant. Dispider (CUHK / Shanghai AI Lab, 2025-01, CVPR 2025) built the same split on the visual side, decoupling perception, decision, and reaction.
Now line them up.
| Omni long-video (perception) | Interaction (presence) | |
|---|---|---|
| Fast module | Global Reasoning System: coarse, low-res, picks evidence | Foreground: always-on, ~200ms, interruptible |
| Slow module | Detail Understanding System: high-res pixel grounding | Background: async deep reasoning / retrieval / tools |
| Shared substrate | one omni backbone, end-to-end RL (GRPO) | shared conversational context |
| Handshake | key frames + rewritten sub-questions | oracle stream / async knowledge injection |
| Forcing wall | token budget: coverage vs. resolution | wall-clock: presence vs. depth |
| The verdict | “single model isn’t strong enough alone” | “two clocks can’t share one forward pass” |
These two teams were never in a room together. One was solving video grounding, the other turn-taking in spoken dialogue. With no shared benchmark, codebase, or vocabulary, they landed on the identical structure: a fast module that maintains coverage or presence and routes evidence, coupled to a slow module that does the deep work under a shared substrate. When two fields converge on the same partition without coordinating, the partition is not a hack. It is telling you something structural about the problem.
The autonomy↔collaboration tension, underneath
Why is the wall physical rather than a capability shortfall we’ll scale past? Because it sits on a deeper tension between two scaling axes pulling in opposite directions.
On the autonomy axis, we have the clearest trend line in the field. METR’s 50%-task time horizon measures how long a human-time task a model can complete autonomously at 50% success, and it roughly doubles every ~7 months (≈212 days, 95% CI 171–249 days, measured since 2019, accelerating to roughly every four months in 2024–2025; Kwa et al., 2025-03, arXiv:2503.14499; the revised title scopes this to software tasks). This is the metric the Singleton points at when it says bigger and longer-running is better.
On the collaboration axis, there is no equivalent metric at all. We cannot measure how a model’s collaboration ability grows over time, and that absence is itself a crack. The autonomy axis has a ruler. The collaboration axis does not even have a unit.
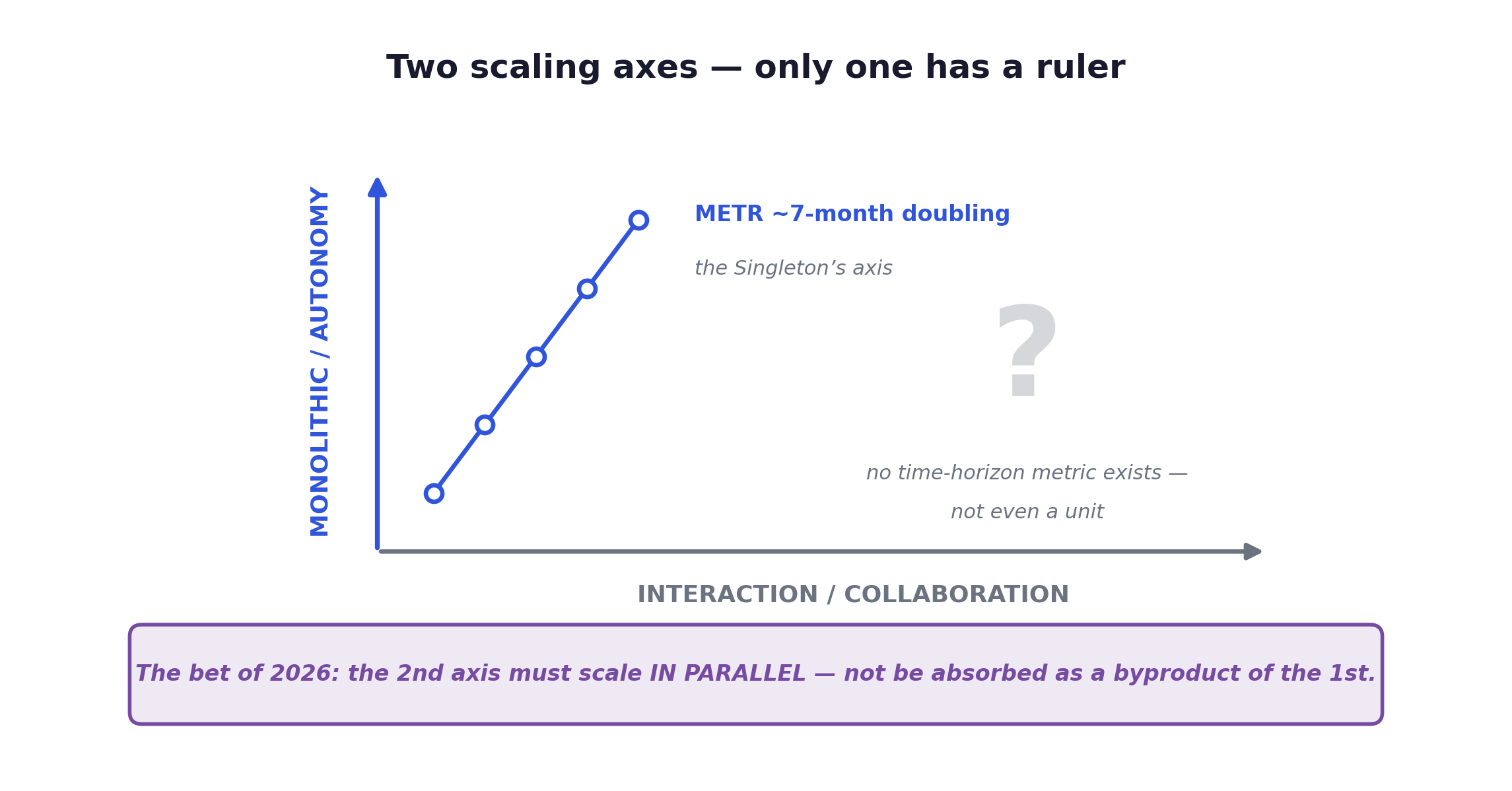
Now the human-side argument for why optimizing the first axis alone fails. Call it the collaboration bottleneck. Humans get pushed out of the loop not because the work stopped needing them, but because the turn-based, autonomy-optimized interface leaves no room for them. You write a long prompt, wait, and read a long answer. During generation the model’s perception is frozen, blind to anything new you’d want to say. A frontier model card reportedly admits as much: used interactively, synchronously, hands-on-keyboard, the model’s benefit is unclear, because it was optimized for autonomous workflows. The thing pushing humans out is the interface, not the task.
Why does that matter for AGI rather than just UX? Because of Hayek and Scott. Hayek (1945) argued that the knowledge a decision needs is dispersed, held in particular times and places, never fully centralizable to any planner. Scott (1998) called the tacit, improvisational counterpart mētis: practical wisdom that resists being written down as a specification. The TML blog cites both directly, and the implication is hard: for most real work, the user cannot fully specify their requirements upfront and walk away, because the requirements don’t yet exist before the work begins. They are evoked only when the user sees an intermediate result. “Specify-and-walk-away” is high modernism for agents: it assumes the task can be compressed into a formal spec, and Scott’s critique of high modernism shows where that leads. Scaling the base model alone is unlikely to close this gap, because the missing knowledge was never in the model. It has to be injected live, through a channel the monolith’s interface was designed to seal shut.
The thesis
The Singleton Hypothesis cracks along a seam that scale cannot weld. 2026 is the year the field shifts from the Singleton to System-level architecture. The shift runs along two axes.
One caution will haunt both axes. In today’s omni models, “unified” means the same infrastructure, not the same intelligence: engineering unity, not cognitive unity. Sharing a substrate is not sharing a mind. The decouplings we’ve built only mitigate the interference; no one has shown that unified training makes understanding and generation reinforce each other. We know hard-sharing hurts, so we engineer partitions to dodge it, which is, honestly, in tension with the whole point of a unified model. Partitioning is the field’s answer, but an answer born of a wall we haven’t yet learned to dissolve.
The next chapter takes the first axis head-on: how the single brain is being carved into functional partitions, and whether the seams hold.
4. Axis One — Architecture: From a Single Brain to Functional Partitions
The monolith never decided to split. It cracked where one set of parameters was asked to do two incompatible things at once.
In the last chapter I argued the Singleton is over: the one all-purpose brain that scale alone would perfect. This chapter covers the first of the two axes along which it gave way. The commitment to modularity is empirical, not philosophical. Every team I’ve watched arrive at functional partitioning got there the same way: they tried to make a single network do two jobs with opposite requirements, measured the interference, and gave up forcing it.
The pattern is consistent across perception, generation, dialogue, planning, and even the serving stack. The whole chapter is variations on it:
Specialized modules under a shared substrate. Partition the function (fast vs. slow, foreground vs. background, understanding vs. generation, modality by modality), but keep one thing shared (attention, context, or a backbone). Then the partition is a brain with regions, not a disconnected pipeline. The shared substrate does the work. Remove it and you’re back to the brittle ASR→LLM→TTS cascades we spent a decade escaping.
From dense monolith to learned-sparse: MoE as the proto-partition
The first crack predates the omni era. Mixture-of-Experts is a degenerate form of partitioning: the experts are homogeneous (interchangeable FFN blocks), the routing is learned (a gate picks top-k experts per token), and the motivation is purely economic, decoupling parameter count from per-token FLOPs. You get a 30B-parameter model that costs 3B to run a token through. Nothing about the experts is meant for anything. Specialization, if it happens, is incidental and uninterpretable.
The rest of the chapter is a march away from this: from learned, homogeneous, compute-driven routing toward deterministic, heterogeneous, function-driven routing. MoE asks “which anonymous expert is cheapest for this token?” Everything that follows asks “which expert is right for this role?”
Mixture-of-Transformers: route by modality, share the attention
The simplest step is Mixture-of-Transformers (MoT). Same skeleton as MoE, but the routing key is the token’s modality, and it’s hard-coded rather than learned. Image tokens go to the image FFN and projection, text tokens to the text FFN, audio to audio. The experts are now genuinely heterogeneous: they hold modality-specific parameters. But they all read and write through one shared self-attention. That shared attention is the point: cross-modal information still flows freely, since the image expert’s output is visible to the text expert’s next layer. Each modality keeps its own private transformation weights and stops fighting the others for capacity.
BAGEL (ByteDance Seed, 2025-05) is the canonical instance: a decoder-only MoT, 7B active / 14B total, trained on trillion-scale interleaved image/video/web data. New capabilities emerged with scale: free-form image editing, future-frame prediction, 3D manipulation, basic world navigation. None of it was explicitly supervised, and text-to-image quality is on par with SD3 and FLUX.1-dev. Partition by role under shared attention, scale, and capabilities you didn’t design for appear.
The dialogue world reached the same structure from a different direction. Qwen3.5-Omni (Alibaba, 2026-04) makes both its Thinker and its Talker Hybrid-Attention MoE, confronting the monolith’s core fear head-on: does merging modalities cost you single-modality skill? It claims no degradation on text and vision versus the same-size single-modality models, with SOTA across most audio benchmarks. (Those numbers are per Alibaba’s own report and unverified by third parties; treat as a vendor claim.) The signal isn’t the leaderboard. It’s that the design needed MoE in both functional halves to avoid the regression.
Understanding vs. generation: the partition the field could not avoid
The most instructive partition is the one the field tried hardest to avoid: understanding vs. generation, the fault line from Chapter 1. They want opposite things, so forcing them through one representation drags each down. The field’s response was a ladder of partitions, each deeper than the last, all under a shared transformer body:
| Depth | Partition axis | What’s shared | Routing | Example (org, date) |
|---|---|---|---|---|
| Encoder-side | understand-encoder vs. gen-encoder | one Transformer body | by task (input path) | Janus / Janus-Pro: SigLIP semantic enc. + VQ tokenizer (DeepSeek, 2024-10 / 2025-01) |
| In-network expert | understand-FFN vs. gen-FFN | one self-attention | by role (MoT) | BAGEL (ByteDance, 2025-05) |
| Objective | AR-text vs. diffusion-image | one Transformer | by token type | Transfusion / Show-o (Meta / NUS+ByteDance, 2024-08) |
| Dual-stream | think (text) vs. speak (audio) | Thinker’s hidden states | by output modality | Thinker-Talker: Qwen2.5/3/3.5-Omni (Alibaba, 2025–26) |
| Whole-system | global reasoning vs. detail grounding | shared context + RL reward | by sub-task | Omni-R1 (Zhejiang U + Ant, 2025-05) |
Top to bottom, the partition migrates outward: from the input encoder, to parameters inside the network, to the training objective, to the output stream, to two whole models. The Chapter 1 caveat still governs every rung. Decoupling only mitigates the interference, it never resolves it. Today “unified” means the same infrastructure, not the same intelligence: engineering unity, not cognitive unity.
Thinker-Talker: the tightest shared-substrate design
Thinker-Talker shows best why the substrate is what matters. The Thinker is the reasoning LLM (“think”). The Talker is a dual-track autoregressive model (“speak”) that emits audio-codec tokens, and it consumes the Thinker’s hidden states, not its final text tokens. So speech inherits the thought before it collapses into discrete words, and text and audio stream out in parallel without colliding. Its ancestor is Kyutai’s Moshi (2024-09) and its “Inner Monologue”: generate a time-aligned text skeleton a few steps before the audio, which dramatically improves language quality. Two functionally distinct modules, one shared internal state.
Fast/slow, foreground/background: the recurring motif
The most recurring partition across every domain I studied is System-1 / System-2: fast-reflexive vs. slow-deliberate, foreground-present vs. background-deep. It shows up independently in three places, which is why I believe it’s structural rather than fashionable:
| Domain | Fast / Foreground (System-1) | Slow / Background (System-2) | Shared substrate |
|---|---|---|---|
| Long-video reasoning (Omni-R1) | Global Reasoning: low-res, fast, picks key frames, rewrites task into sub-questions | Detail Understanding: high-res pixel grounding on the few selected clips | context + hierarchical RL reward (GRPO) |
| Real-time dialogue (KAME / TML) | full-duplex S2S: always-on, ~200ms, interruptible, keeps the conversational beat | async LLM: retrieval, reasoning, tools, no latency budget | shared context; result injected as an “oracle stream” |
| World-model planning (MuZero / Dreamer) | decision-time planning: search now from current state, act, re-plan (model-predictive control, MPC) | background planning: amortize imagined rollouts into a policy/value net | one learned latent space (the world model) |
The first row is the strongest case. Long-video reasoning’s coverage-vs-resolution conflict (Chapters 1 and 3) is physically mutually exclusive. Omni-R1’s two-system split proves one model on a fixed token budget cannot do both.
There are two distinct “Omni-R1” papers. The one above is Zhejiang U + Ant. A separate MIT work of the same name found RL gains on audio benchmarks came mostly from improved text reasoning, with the “multimodal” model riding its own language prior. I’ll return to what that implies about internalization later.
The infrastructure echo: even the systems layer partitions
Partitioning recurs one level down, in the serving and training stack, with no semantic content at all. In serving, prefill (compute-bound) and decode (memory-bound) are now routinely PD-separated onto different hardware pools: two phases with incompatible resource profiles, scheduled independently. In RL infra (I wrote a whole post on this) the modern standard is to decouple rollout from training: a fast inference engine generates trajectories on one fleet while the trainer updates weights on another, the two kept in lockstep only by periodic weight sync. Fast generation, slow optimization, shared parameters: the foreground/background split again, expressed in YAML and Ray actors instead of attention heads.
When the same shape appears in the neurons, the dialogue loop, the planner, and the cluster scheduler, it stops being an architecture choice. It starts looking like a constraint on any system that must do incompatible things at once.
The maximal version: LeCun’s six modules
Extrapolate functional partitioning to its limit and you arrive at LeCun’s 2022 Path Towards Autonomous Machine Intelligence, the most explicit “brain as a system of specialized modules” blueprint published. It has six modules (perception, world-model, cost, memory, actor, and a configurator that reconfigures the rest), with a world model as the central engine everything plugs into. It is the ceiling of axis one: not two regions but a full functional taxonomy. I dissect it in Chapter 8, where the world model takes center stage. For now the point is narrower: every partition in this chapter is a partial sketch of that same picture, and the substrate doing the unifying (attention in MoT, hidden states in Thinker-Talker, shared context in Omni-R1, the world model in LeCun’s blueprint) is always what keeps the modules a mind and not a pipeline.
Partitioning reorganizes the brain. But the bigger change in 2026 is not where intelligence sits, it is where it comes from. That is the second axis.
5. Axis Two — Capability: From Innate Intelligence to Acquired Methodology
We spent four years asking how smart we could make the brain. The systems that shipped were won in the software wrapped around it.
The first axis cut the monolith into functional parts. This second axis is harder to see, because nothing about the model’s silhouette changes. The weights look the same. The benchmark looks the same. What changed is where the capability lives.
The cleanest evidence I know is the Darwin Gödel Machine (DGM, ICLR 2026; Zhang, Hu, Lu, Lange, Clune; UBC / Vector / Sakana; code at github.com/jennyzzt/dgm). Freeze the foundation model. Do not touch a single parameter. Let the system edit only its own agent design: tools, prompts, control flow. Same model, same tasks. SWE-bench Verified goes from 20.0 to 50.0. Polyglot goes from 14.2 to 30.7. No retraining, no bigger brain. The entire delta came from scaffolding the agent built around an unchanged model.
That one delta is the chapter’s core claim. The old mental model: capability is innate, it is the model, and you get more by training a better one. The new picture: a large and growing fraction of usable capability is acquired methodology. Harness, skills, memory, tools, self-improvement, assembled around a frozen engine.
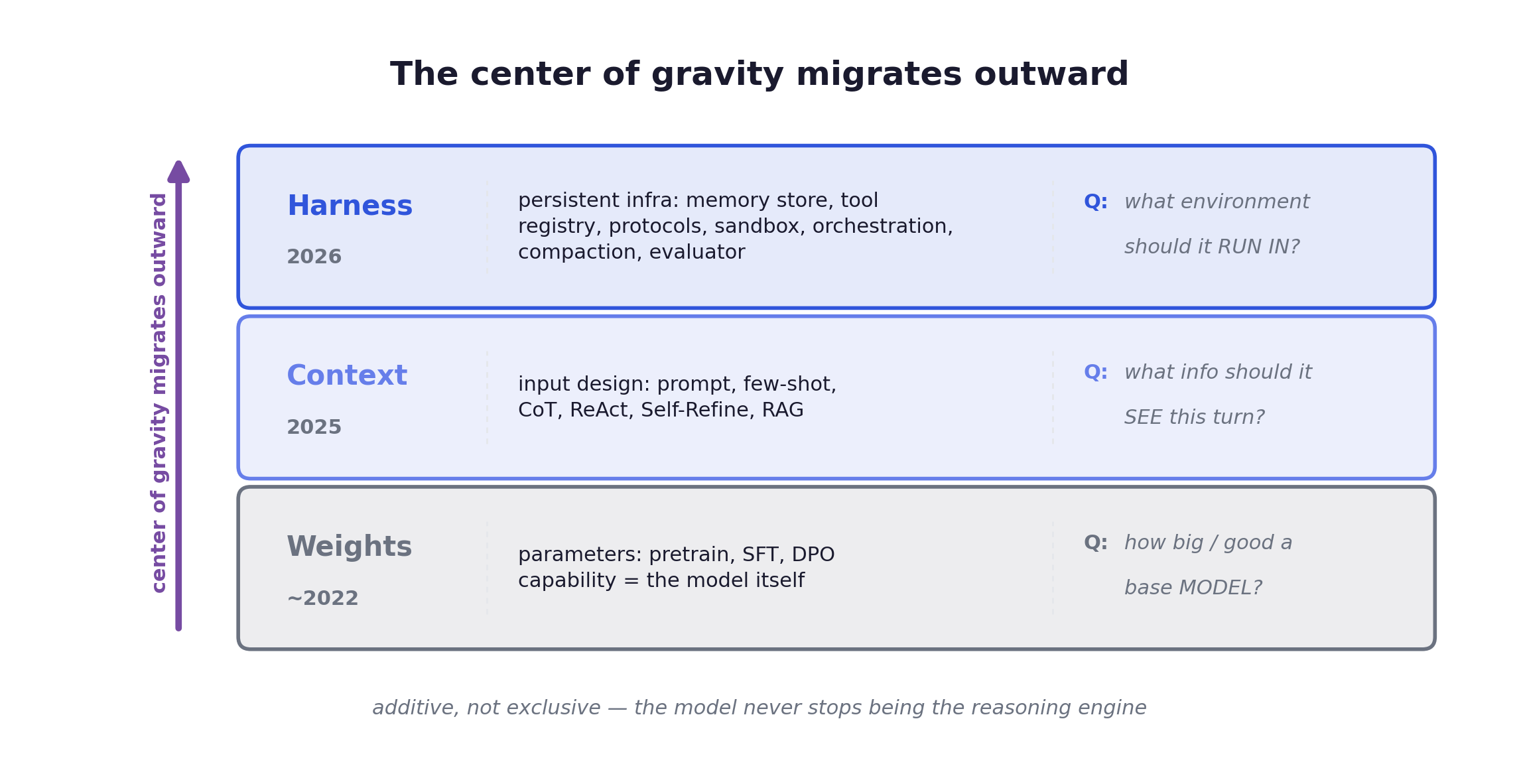
The center of gravity migrates outward
The literature calls this externalization. Over 2022→2025→2026, the capability center of gravity migrates outward, along a spine of three layers: Weights → Context → Harness. The layers are additive, not exclusive, a distinction that is easy to miss. The model never stops being the reasoning engine. It just stops being the sole locus of intelligence.
| Layer | What you tune | Example techniques | Failure it answers |
|---|---|---|---|
| Weights | the parameters themselves | pretraining, SFT, DPO/RLHF | “the model doesn’t know enough” |
| Context | what enters the window this turn | prompts, few-shot, CoT, RAG, Self-Refine, ReAct | “the model knows it but isn’t told” |
| Harness | the runtime built around the model | memory stores, skill files, tool registries, sandboxes, evaluators, orchestration | “the model is capable but not governed” |
The mnemonic: Weights are trained, Context is fed in, Harness is built around it. The paradigms are nested, not successive. By one retrospective division, Prompt Engineering (2022–24, getting one turn of text right) sits inside Context Engineering (2025, getting the whole window right), which sits inside Harness Engineering (2026, governing the whole runtime). Each generation answers a failure mode the previous one structurally could not.
[ Harness Engineering 2026 : govern the whole runtime
[ Context Engineering 2025 : get the window right
[ Prompt Engineering 2022-24 : get one turn of text right ] ] ]The engine: recall becomes recognition
Why does moving capability outward work? The mechanism is older than LLMs: Don Norman’s distinction between recall and recognition. Recall (“does the model know X?”) is hard. Recognition (“X is sitting in context, can the model use it?”) is easy. Externalization is the machine version of writing things down. It rewrites every hard recall problem into an easy recognition problem.
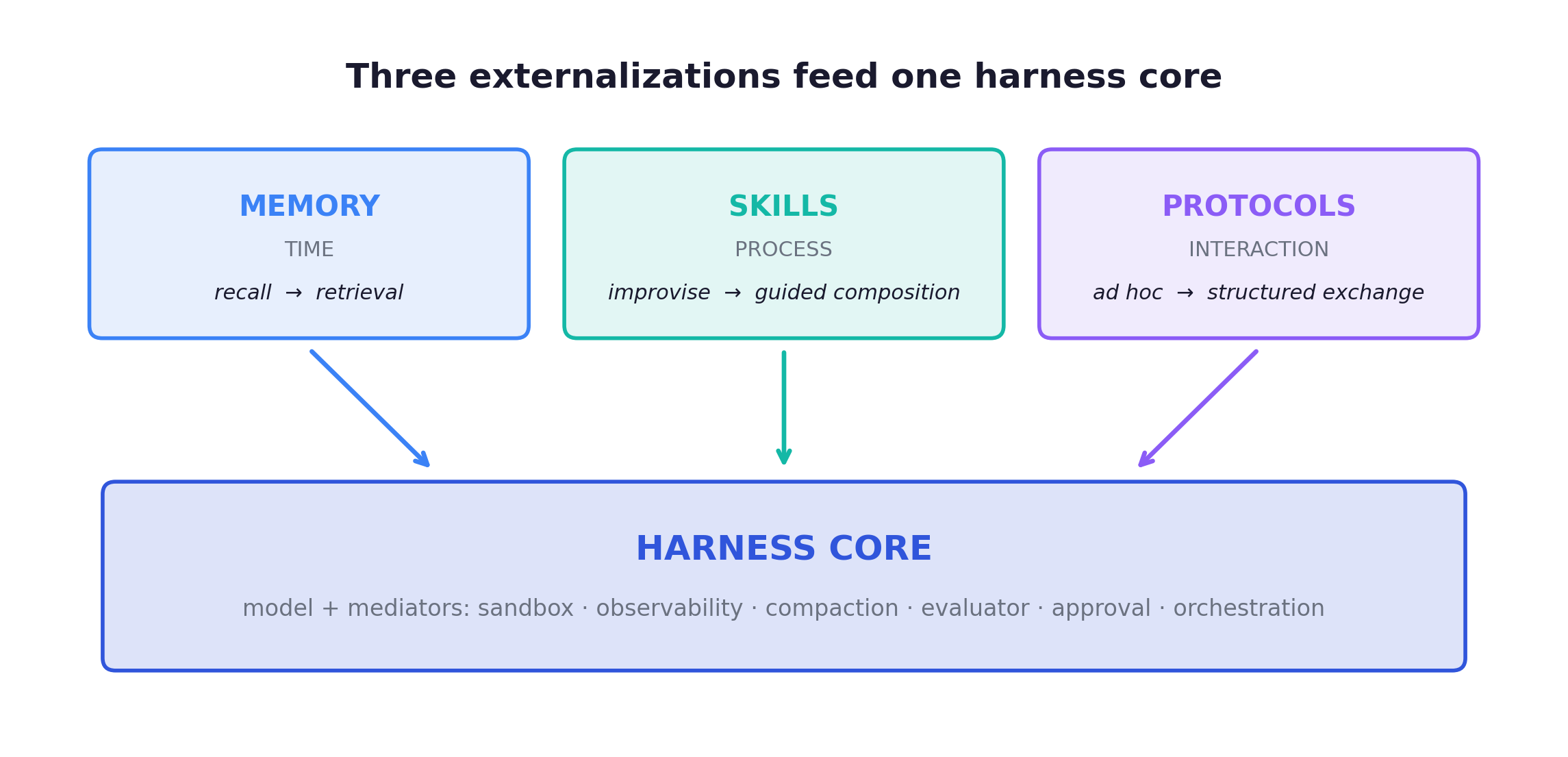
That move propagates into three dimensions, each absorbing a different burden:
-
Memory absorbs time, giving continuity across turns and sessions, turning recall into retrieval. But memory is a state-management layer, not a bigger window and not a vector DB. Four content types must stay separated, because they differ in retention, retrieval, and privacy: working context, episodic experience, semantic knowledge, and personalized memory. The architecture evolves from storage to control: Monolithic (it exists) → Retrieval (it has capacity) → Hierarchical (it has organization: extract, consolidate, forget) → Adaptive (it has strategy). Reflexion is the canonical episodic anchor; it stores verbal self-critiques of failed attempts. MemGPT is the hierarchical one: context window = RAM, external store = disk, OS-style paging. The success criterion is not “how much did we save” but “did we make the current decision legible.”
-
Skills absorb process, giving consistency. A skill is not a tool and not a protocol. Tools expose operations, protocols govern invocation, skills encode how a class of tasks is executed (operational procedure plus decision heuristics plus normative constraints). A skill is not a new action; it changes the task from inventing a workflow to selecting and following one. Anthropic’s Agent Skills (2025 open standard) is the clean industry instance:
SKILL.mdplus scripts and resources, surfaced by progressive disclosure (name → manifest → full guide), complementary to MCP. MCP manages atomic tools, Skills manage composed workflows. Voyager is the milestone showing skills as capability growth: in Minecraft it builds an ever-expanding library of executable code through exploration and self-verification. -
Protocols absorb interaction, turning ad hoc message-passing between agents and tools into structured exchange.
This is not a convenience plugin, and that is the bridge to where this blog is heading. In the language of Norman’s cognitive artifacts, each layer re-structures the task itself. One framing captures it: externalization constructs a larger cognitive system around the model rather than replacing it. The model is strong at synthesis over information it’s given, and weak at stable memory, repeatable process, and governed interaction. Externalization builds the artifacts that cover the gaps.
From ReAct to governed state transitions
The control loop is where “methodology” becomes concrete. The familiar primitive is ReAct: reason, act, observe, repeat. ReAct is useful, but it is a framework primitive, not a harness. Modeled as a transition system, its transition function is partial, undefined on errors: no committing state, no error-recovery arc. On a failure it has nowhere defined to go. That gap is execution runaway. ReAct can run a demo, but “runs-a-demo” and “runs-reliably-over-the-long-horizon” are separated not by a stronger model but by the components ReAct omits.
The evolution is Plan-Execute-Verify (PEV), the core control paradigm of code-as-harness, with lineage ReAct → Reflexion → PEV:
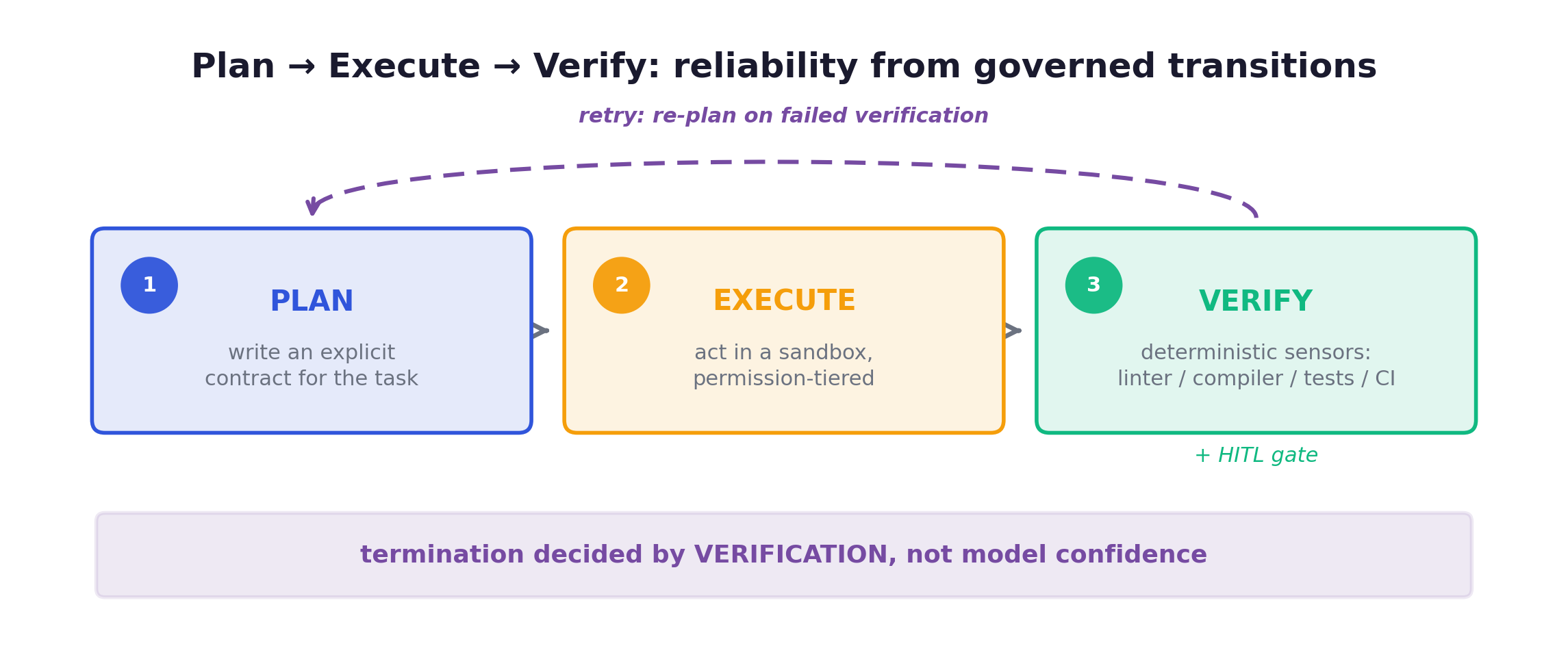
The thesis: reliability comes from governed state transitions, not from better repair prompts. You fix an unreliable agent by making the verifier, not the model’s self-reported confidence, decide when the loop ends. Code is the natural medium here because it is executable, inspectable, and stateful.
The cutting edge: a harness that evolves itself
Now wrap PEV around the harness itself. This is the self-evolving harness, and DGM is its sharpest realization.
The lineage runs through Schmidhuber’s 2007 Gödel Machine, which would modify itself only given a formal proof of benefit: mathematically clean, never practical. DGM’s move is to relax “provable” to “empirically validated against a benchmark.” Its core insight: self-improvement is fundamentally a coding task that modifies the coding agent’s own code repository. So progress on a coding benchmark is progress at self-modification.
Gödel Machine : modify only if PROVABLY beneficial -- never practical
relax --> empirically validated on a benchmark
DGM : fixed_meta.modify(task_agent) # task logic editable; modify() HARD-CODED
merge -->
HyperAgent : hyperagent.modify(hyperagent) # edits BOTH solve AND self-modifyDGM doesn’t hill-climb. It does open-ended evolution. An Agent Archive keeps every variant that still compiles and retains editing ability. Parent selection is proportional to score × 1/(children+1) with all probabilities nonzero, preserving suboptimal stepping stones (the path to the optimum passes through two performance dips). Two ablations confirm both pillars are necessary. The gains transfer across models and languages too: held-out SWE→Polyglot 28.9, Polyglot→SWE 24.5.
HyperAgents / DGM-H (Jenny Zhang et al. + Meta/FAIR, 2026-03-23) makes the second leap: merge the task-agent and the meta-agent into one editable program, so the mechanism that produces improvements is itself editable. This is metacognitive self-modification. It escapes meta-level infinite regress and drops DGM’s “solving = self-modifying” assumption, generalizing to any computable task: paper review 0.0 → 0.710, robotics reward design 0.060 → 0.372, cross-domain transfer imp@50 = 0.630 against DGM’s ≈ 0.0.
The hidden thread surfaces: the dual is internalization
One flag before we leave this axis, because it reframes everything above. Externalization moves capability outward, but it has a dual that points the other way. DGM-H, left to evolve, autonomously re-grew the very scaffolding harness engineers build by hand. It wrote a PerformanceTracker class and kept a persistent log of insights and next-plans that reads like an engineer’s experiment journal. Nobody told it to. Self-referential systems are reinventing harness engineering itself. The deeper version of the same move is native agentic RL and on-policy distillation baking the scaffold’s methodology back into the weights, which is what makes a model natively agentic instead of scaffolded.
So the dual of externalization is internalization, and it sets up the question this blog is circling: should everything be internalized? I resolve it in Chapter 7. For now, note that the externalization frameworks’ own governing principle is minimal sufficiency, not maximal externalization, which already hints the answer is no.
Two axes now: a partitioned architecture, and capability sourced from acquired methodology layered around a frozen brain. Hold both at once and a question becomes impossible to ignore. Are we, without ever quite deciding to, rebuilding the brain?
6. Is This the Brain, Reinvented?
We split one brain into many, then went looking for an existence proof. It was sitting inside our own skulls. But the proof of a pattern is not a blueprint for building it.
Every chapter so far has been describing a brain without saying so.
We watched the monolith fracture into specialists: modality encoders, language heads, action heads (Chapter 4). We watched it split along the time axis into a fast foreground that must answer in ~200ms and a slow background that reasons without a wall clock (Chapters 2 and 3). We watched it learn that capability lives not only in the weights but in tools, memory, and notes (Chapter 5). In Chapter 8 we will watch it grow an internal generative model of the world that it uses to predict and to plan.
There is a striking parallel here for anyone who knows neuroscience: nature solved every one of these problems first, and published. This chapter is the cross-domain audit: an honest look at whether the Singleton→System shift is converging on the biological brain and the canonical models of mind, or whether we are just reading our own silhouette into the system and calling it neuroscience.
Two passes. First the convergences, real and in a couple of cases exact. Then the caveats, which matter more.
Six places where the engineering rhymes with the brain
Start with the deepest fact: the biological brain is not one homogeneous all-purpose substrate. Evolution had ~86 billion neurons and hundreds of millions of years of optimization pressure, and it did not produce one undifferentiated blob that scale alone resolved into general intelligence. It produced a system of functionally specialized regions: primary visual cortex (V1) for early vision, V4 for color, V5/MT for motion, auditory cortex in the temporal lobe, a topographically mapped somatosensory and motor cortex (Penfield’s homunculus, mapped out in the 1930s–50s), Broca’s area for speech production and Wernicke’s for comprehension (localized by lesion as far back as 1861 and 1874), a fusiform face area (Kanwisher, 1997), a hippocampus for episodic memory and spatial navigation, an amygdala for affective salience, a prefrontal cortex for executive control and working memory. We know these are dissociable, not just correlated, because lesions cleanly knock out one function and spare the rest: Broca’s aphasia, Wernicke’s aphasia, patient H.M.’s total inability to form new long-term memories after his hippocampi were removed. The brain is the existence proof. Scale alone did not give nature one all-purpose organ; it gave nature a system of specialists wired into one mind. Axis 1 of our thesis is not an arbitrary engineering taste. It is the design evolution converged on.
”Many regions” is not the whole picture. The next fact is the one our mixture-of-experts and modality-adapter designs unknowingly echo. The cortex does not use a different kind of tissue for each function. Mountcastle’s columnar hypothesis (1957) is that a largely repeated six-layer microcircuit, the cortical column, is reused across sensory, motor, and association cortex, and what specializes it is its connectivity and its inputs, not its substrate. One shared computational motif, function set by routing and learning. That is the picture of one shared transformer backbone specialized by routed experts and modality adapters. But cortical uniformity has known exceptions, and calling an MoE expert a “cortical column” is motif-level resonance, not homology.
Here is the full mapping. The third column does the real work: it separates genuine structural similarity from convenient metaphor.
| Engineering pattern (this blog) | Brain / cog-sci analogue | What’s similar |
|---|---|---|
| Specialized modality encoders + functional heads under one substrate | Cortical functional localization (V1/V4/MT, auditory, motor, Broca/Wernicke, FFA) | The organizing principle: intelligence at scale partitions into specialists |
| Shared transformer + routed experts/adapters | Mountcastle’s repeated cortical microcircuit | One reused motif specialized by connectivity |
| Fast token generation (background) vs slow test-time reasoning (foreground) | Cerebellum (automatized) vs neocortex (deliberate); Kahneman’s System 1 / System 2 | The dual-process partition itself |
| Modality experts for perception | Fodor’s modular input systems (domain-specific, encapsulated, fast, mandatory) | Perception wants to be modular |
| Shared substrate that integrates specialists into one agent | Baars’ Global Workspace (compete up, broadcast down) | Partition requires an integration bus |
| World model / understanding-as-prediction | Friston/Rao-Ballard predictive processing | Brain is a generative prediction machine |
| Harness / notes / vector store as cognition | Clark & Chalmers’ Extended Mind | Reliable external resources are part of cognition |
Two of these mappings are stronger than the rest. The dual-process row is the tightest correspondence here. Kahneman’s Thinking, Fast and Slow (2011), synthesizing the Stanovich & West System-1/System-2 tradition, describes a fast, automatic, parallel, effortless, always-on System 1 and a slow, serial, effortful, capacity-limited System 2 invoked only for hard problems. That is, almost word for word, the difference between fast token-by-token generation and slow test-time reasoning. It is the foreground/background dual-model from Chapter 2, where a ~200ms-micro-turn foreground maintains real-time presence while an asynchronous background runs incompressible deep reasoning. System 1 and System 2 were not invented by the labs that ship fast-vs-reasoning models; Kahneman handed us the vocabulary, and the brain handed it to him. The echo runs deeper. The cerebellum holds on the order of 80% of the brain’s neurons and absorbs over-learned, automatized routines, while the neocortex stays flexible and deliberate. Skills migrate from effortful cortical control to automatic execution with practice, and that migration is the internalization process this whole blog circles. Treat the cerebellum=fast / cortex=slow pairing as evocative analogy, not a literature-backed equivalence.
The other row that does real work is Global Workspace. The obvious objection to functional partitioning: if you shatter the brain into specialists, what makes it one agent rather than a committee? Baars’ Global Workspace Theory (1988), later given a neuronal formulation by Dehaene and Changeux, is the answer. A large set of unconscious, specialized, parallel processors compete; a winning coalition gains access to a limited-capacity global workspace and is broadcast back to all the other modules. Competition up, broadcast down. That is precisely the role the “shared substrate” plays in Chapter 4, the channel through which partitioned specialists coordinate into a single coherent agent. It is also close to LeCun’s 2022 autonomous-intelligence blueprint, the most explicit “brain as a system of modules” artifact in the field: perception, world-model, cost, memory, actor, and a configurator that reconfigures the rest, six modules plugged into a central predictive engine. Use GWT as an architectural metaphor for integration, not a claim that anything is conscious. It is a leading theory, not a settled one, and Integrated Information Theory and higher-order theories compete with it.
The predictive-processing row I will mostly hand off. Friston’s free-energy principle and the Rao-Ballard (1999) predictive-coding tradition recast the brain as a hierarchical generative model that predicts its inputs top-down and ships only the residual errors bottom-up, with perception and action both minimizing prediction error. That is the canonical-brain-theory grounding for everything Chapter 8 will say about world models and “understanding = prediction = generation.” It is a genuine resonance and a contested theory at once, and I will let Chapter 8 carry the weight.
The caveats, which matter more
Now the caveats. Convergent architecture is not evidence of brain-like computation. Four reasons to hold all of the above at arm’s length.
First, Marr’s three levels. Marr (Vision, 1982) taught us to separate the computational level (what problem is solved and why), the algorithmic level (what representations and procedures), and the implementational level (the physical realization). Two systems can match perfectly at the computational level and share nothing at the implementational level. Transistors are not neurons. Backprop is not spike-timing-dependent plasticity. So: functional partitioning, dual-process, global broadcast, and predictive coding are computational-level convergences, plausibly algorithmic, and emphatically not claims about wetware. The convergence is fair to claim at the computational level, not at the implementation level.

Second, the bitter lesson warns against exactly this mimicry. Sutton (2019) is the historical observation that general methods leveraging search and learning at scale consistently beat approaches that hand-build human knowledge of problem structure. Brain-convergence is dangerous as a design mandate. Hand-building the brain’s structure into a model, copying the cortex’s six-layer count for instance, has been outrun by general methods at scale every time it has been tried. I would reverse the arrow of causation here. We did not converge on the brain because we copied it. We converged because general search-and-learning, run against the same computational problems evolution faced, rediscovered structure evolution also found. The convergence is post-hoc resonance, not a recipe.
Third, structural correlation is weak evidence of mechanism. Fodor’s (1983) input modules are domain-specific, encapsulated, fast, and mandatory, but he argued the central system, belief fixation and general reasoning, is precisely not modular, and that is where the frame problem lives. Even the modularity story predicts our cleanest partitioning successes will be in perception, and general reasoning will resist clean partition. Fodor told us in 1983 what we relearned in 2026: perception wants to be modular, general reasoning fights it. And whether agentic “deliberate reasoning” is genuinely System-2 or just more System-1 pattern-matching wearing a reasoning costume is still open.
Fourth, anthropomorphism. Every region↔module arrow in that table is easy to over-read. We are pattern-matchers looking at our own reflection. Mapping the hippocampus onto the vector store and feeling we have found something is a streetlight effect. The mappings are illustrative; several are just-so stories. The danger is reading our own silhouette into the system and calling it neuroscience.
The measured conclusion
So is this the brain, reinvented? The convergence is real, it is suggestive, and it is not a reinvention. Intelligence built at scale, by evolution and separately by gradient descent, tends to organize into specialized modules plus an integration bus, and mature cognition tends to offload to external resources rather than internalize everything. Those are robust, repeatedly-discovered solutions to shared computational problems. So I take the brain as inspiration, not blueprint, and not as license to hand-engineer the biological mimicry the bitter lesson already buried.
The last convergence quietly opened something else. Clark & Chalmers’ Extended Mind (1998), where Otto’s notebook plays the functional role of Inga’s biological memory and therefore counts as part of his memory under the Parity Principle, is the cognitive-science verdict that external scaffolding can be constitutive of mind. If even humans never fully internalize, if mature cognition is defined partly by what it keeps outside the skull, then one thread running quietly under every chapter comes due. If methodology lives outside the weights, in the harness, the notes, the tools, will it, and should it, ever move inside? That is the question the next chapter is about.
7. The Hidden Thread: How Capability Becomes Native
Every chapter so far pushed intelligence outward, into the scaffolding around the model. This one asks the opposite: when does the scaffolding come back home, and how much should?
A thread has run under this whole post; time to pull it taut. Recall the second axis from Chapter 5: capability migrating from innate (a bigger base model) to acquired (harness, skills, memory, tools). The center of gravity moves outward along the Weights → Context → Harness spine. The weights are still the reasoning engine, just no longer the sole locus of intelligence. That is externalization. Its evidence was the Darwin Gödel Machine: freeze the foundation model, edit only the agent design, and SWE-bench Verified still climbs from 20.0 to 50.0. The gain came from the harness, not the brain.
The dual: internalization
Externalization has a dual, and if you watch only one direction you misread the field. The dual is internalization: scaffold behavior baked back into the weights, so the model becomes natively what it once needed scaffolding to do.
This is the thread I flagged in my earlier post on agentic RL: capability that lives in the weights versus capability that lives in the scaffold. The harness era pushed everything into the scaffold because that was the cheap, fast, debuggable place to put it. But once a behavior is stable and recurring, leaving it in the scaffold is a tax. Every call re-pays the token cost, re-reads the skill file, re-runs the control loop in-context. The economically obvious move is to compile the recurring procedure into the parameters. Native agentic RL and on-policy distillation are the machinery: they train the model so the scaffold’s behavior becomes a reflex rather than a recipe it reads each time.
We can already watch the harness layer perform a miniature version of this without touching the weights. Two clean instances:
- Memory → Skill promotion. A recurring procedural regularity sits in episodic memory. Once the harness promotes it to explicit reusable guidance, it stops being memory and becomes a Skill. It is the same move a human makes when “that one time I debugged the flaky test” becomes “here’s how I debug flaky tests.”
- Self-evolving systems re-growing the scaffold. HyperAgents (DGM-H, Jenny Zhang et al. + Meta/FAIR, 2026-03-23) merged task-agent and meta-agent into one editable program and let it improve itself. Left to evolve, it autonomously wrote a
PerformanceTrackerclass and a persistent-memory log that reads like an engineer’s experiment journal: insights, causal hypotheses, next plans. Nobody told it to. Self-referential systems are reinventing harness engineering itself.
So the picture is not a one-way arrow outward. It is a circulation. Behaviors get externalized into the harness because that is where you can iterate fast. Then the stable ones get internalized, either into a higher-level artifact (memory → skill) or, eventually, into the weights.
Humans run exactly this loop. Vygotsky’s account of development is internalization made literal: higher mental functions first appear interpsychologically, as external, social, scaffolded behavior (a child counting out loud, a parent prompting), and only later intrapsychologically, as internal thought. The automaticity literature (Shiffrin & Schneider 1977; Anderson’s ACT-R proceduralization) tells the same story at the level of skill: effortful, declarative, externally-guided performance becomes procedural and automatic with practice. The controlled-to-automatic shift even has a biological echo: over-learned routines appear to migrate from effortful neocortical control toward the automatized cerebellum (illustrative, not a proven equivalence). Internalization is the oldest learning loop there is.
So: is full internalization the endgame?
If internalization is the dual of externalization, is its limit to internalize everything? To bake every skill, fact, and tool protocol into a single self-sufficient set of weights that needs no scaffold?
The tempting answer is yes. A model that has internalized everything is faster, with no retrieval latency, no stale-memory bug, no skill file eating the context budget. The Singleton dream, resurrected one layer up.
That answer is wrong, and the people who built the externalization frameworks agree. Their stated governing principle is not maximal externalization but minimal sufficiency: a good harness simplifies the model’s decision problem and does not create a second one. Read in reverse, it is also a statement about internalization. You internalize to simplify the decision. You do not internalize the parts of the world that are volatile, unbounded, or better kept exact.
Humans are the existence proof that full internalization is not the goal. We never fully internalize, and we are not failing when we don’t. This is the force of Clark & Chalmers’ 1998 Extended Mind thesis. Otto, whose biological memory is failing, writes the museum’s address in a notebook; Inga recalls it from memory. The Parity Principle says Otto’s notebook plays the same functional role Inga’s memory does, so the notebook is part of Otto’s cognitive system. Cognition is not skull-bound. That single claim is the entire argument for why a harness, a scratchpad, and a vector store are cognition, not crutches. Recall-becoming-retrieval is a feature, not a failure mode.
Which dissolves the question. The endgame is not “internalize everything.” It is a partition:
| Internalize (in-weights): the procedural kernel | Externalize (harness / extended mind): the volatile & unbounded | |
|---|---|---|
| What | how to reason, how to act, control loops, judgment, the skills that recur | facts, episodic events, long context, org-specific data, anything that changes faster than you can retrain |
| Why | recurs every call, so paying the scaffold tax each time is pure waste; reflex beats recipe | changes constantly, or is too large / private / instance-specific to live usefully in parameters |
| Failure if wrong | the kernel stays external: fragile, slow, re-derived every turn (ReAct re-improvising) | you internalize it anyway: stale weights, hallucinated facts, bloated training, no clean update path |
Internalize the kernel: the fluid procedures, the control loops, the judgment, the skills that recur. Externalize the rest: the facts, the episodic record, the long tail of context that changes faster than any retraining cadence. This is the minimal-sufficiency principle and the extended mind saying the same thing from two directions.
The kicker: a machine need not honor the human optimum
This is where copying biology wholesale stops making sense. Humans partition the way we do because we are forced to. Biological memory is lossy, slow to write, capacity-bounded, and non-shareable. You cannot copy your hippocampus into mine. Evolution put the kernel in wetware and the rest in notebooks because that was the only deal on offer.
A machine is under no such constraint. Its external brain can be everything biology’s cannot:
| Property | Human external memory (notebook) | Machine external memory |
|---|---|---|
| Fidelity | lossy, reconstructive | exact, lossless |
| Capacity | bounded by what you can manage | effectively unbounded |
| Write speed | slow, effortful | instant |
| Versioning | none | full history, rollback |
| Shareable | no, locked to one skull | yes, copy across every instance |
| Skill loading | years of practice | load a SKILL.md in one call |
So the optimal partition for a machine is not the human partition. A human internalizes a skill because the only alternative is a slow, error-prone notebook lookup. A machine can keep that skill in a perfect, instantly-loadable, infinitely-cloneable external store and lose almost nothing. Its break-even point for internalization sits in a different place than ours. The case for baking something into the weights is weakest exactly where the digital external brain is strongest: bulk facts, episodic logs, broad tool catalogs. It is strongest where externalization is genuinely costly: the tight control loop, the judgment that has to fire mid-token, the procedures so recurrent that re-reading them each turn is the dominant cost.
This is my answer to the question I posed in the introduction: should AGI be fully human-like? I don’t think so. The right framing is not mimicry but convergent solution under different constraints. Expect AGI to converge on the human principle, internalize a kernel and offload the rest, because that principle is forced by the structure of any open-ended task, not by carbon chemistry. But expect it to diverge on the placement of the boundary, because the machine’s external brain is strictly better than ours: exact where ours is lossy, unbounded where ours is bounded, cloneable where ours dies with us. The goal is not a system that remembers like a human. It is a system that keeps a strictly better notebook, and internalizes only the kernel a notebook cannot serve fast enough.
Which forces the next question, the one the whole field quietly converged on in 2026. Internalize the kernel, externalize the rest, but a kernel of what? The recurring answer is not a skill or a control loop at all. It is an internal world model.
8. The Substrate Underneath: World Models and Abstraction-Switching
Every module we have built so far plugs into something. This chapter is about the something.
We have spent seven chapters cutting the monolith into modules and bolting methodology onto its surface. But a system of parts is only coherent if the parts share a model of the world they act in. Pull on every thread of the System-level Architecture: the foreground/background split, the understanding/generation partition, the self-improvement loop. They all terminate at an internal predictive model of the environment. That model is the substrate. It makes the partitioning more than a pile of disconnected experts, and the methodology more than a stack of scripts.
So here is the question: does a general agent actually need an internal world model, or is that an assumption we have inherited rather than earned?
The answer turned out to be a theorem
For most of the deep-learning era this was a philosophical argument. In 2025 it became a proof. Richens, Abel, Bellot, and Everitt at DeepMind published General Agents Contain World Models (arXiv:2506.01622, ICML 2025): any policy that generalizes to a family of multi-step, goal-directed tasks at bounded error necessarily encodes a world model that can be algorithmically extracted from the policy. The better it generalizes, the more accurate the extractable model. The world model is not something you choose to build. It is a precondition for the generalization we are chasing.
The fence around this result is easy to over-read. The theorem covers multi-step, goal-directed generalization only. Single-step and narrow-task agents are out of scope, so it does not say “every strong model contains a world model.” And “necessary” does not mean “accurate or causally faithful.” An extracted model can ride shortcut correlations and break under distribution shift. The theorem tells you the structure is there. It does not promise the structure is right.
The empirical mirror came three years earlier, and it is the existence proof everyone cites. Othello-GPT (Kenneth Li et al., Harvard/MIT, arXiv:2210.13382, ICLR 2023) was a vanilla autoregressive GPT trained only to predict legal next moves. It spontaneously grew an internal representation aligned to the true board state. The decisive test is causal: intervene on the activations encoding the board, and the model’s move prediction changes accordingly. Nanda et al. (2023) later rewrote the encoding as a clean linear “mine/yours” representation (linearity is Nanda’s refinement, not a claim from the original nonlinear-probe paper). Yuan & Søgaard (2025) reportedly reproduced ~99% unsupervised board recovery across seven LLMs. Prediction pressure alone breeds structure.
The caveats matter just as much. Othello is a closed, discrete, rule-bounded toy world. A probe that reads the board is necessary but not sufficient for understanding, and extrapolation to open real worlds remains unproven. But side by side you get something real: one empirical existence proof, one theoretical necessity result, both pointing at the same conclusion.
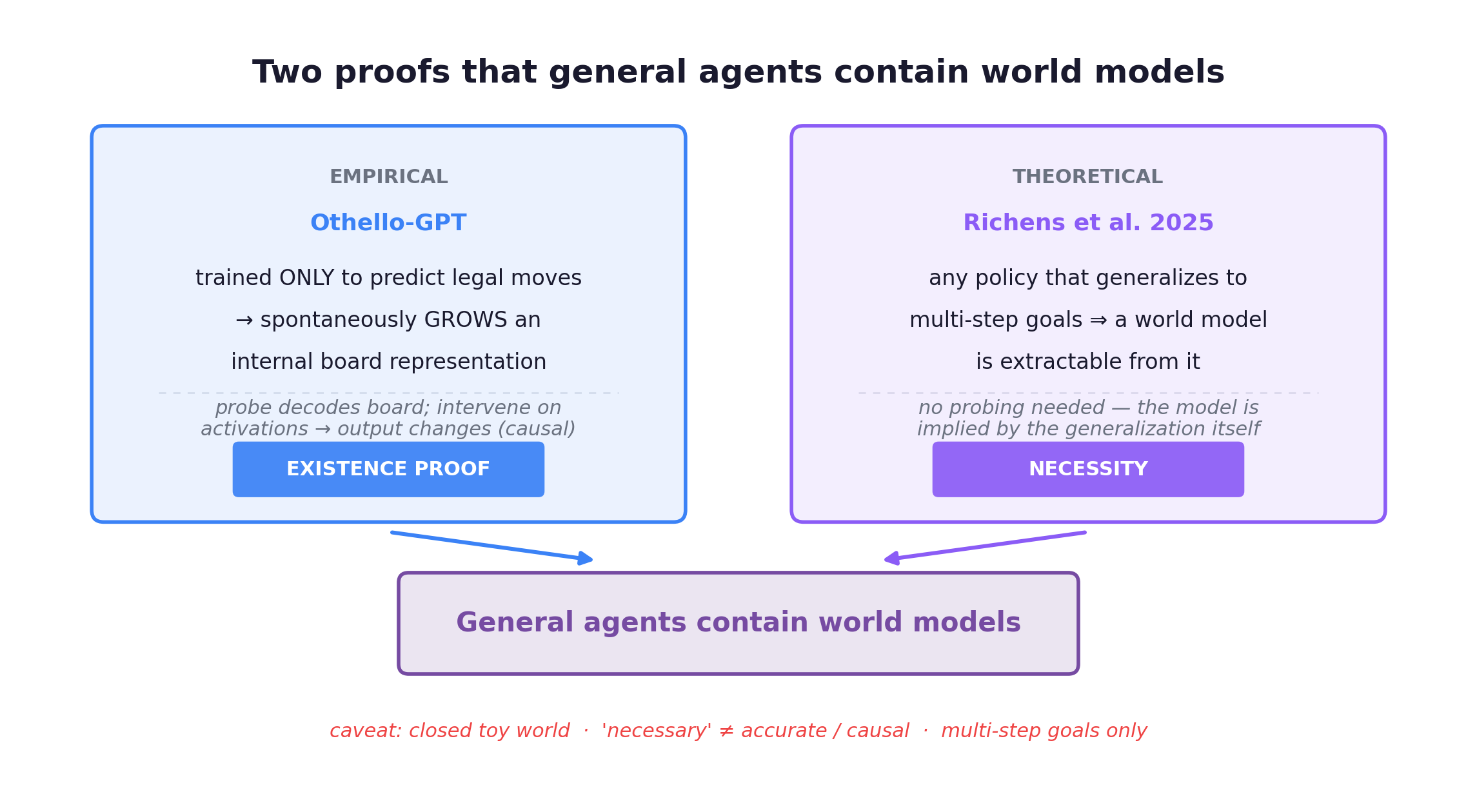
This is where the hidden thread surfaces. The necessity theorem says capability that looks purely behavioral is in fact internalized as an in-parameter world model you can extract. External scaffolding, given enough generalization pressure, becomes intrinsic structure. The kernel worth internalizing, the thing Chapter 7 was circling, is largely this: a world model plus the control loop that runs over it.
The maximal vision: a brain as a system of modules
The most explicit published picture of the System-level Architecture is not in any LLM paper. It is in LeCun’s 2022 position paper, A Path Towards Autonomous Machine Intelligence. It proposes an autonomous agent as six specialized modules: perception, world-model, cost, memory, actor, and configurator.
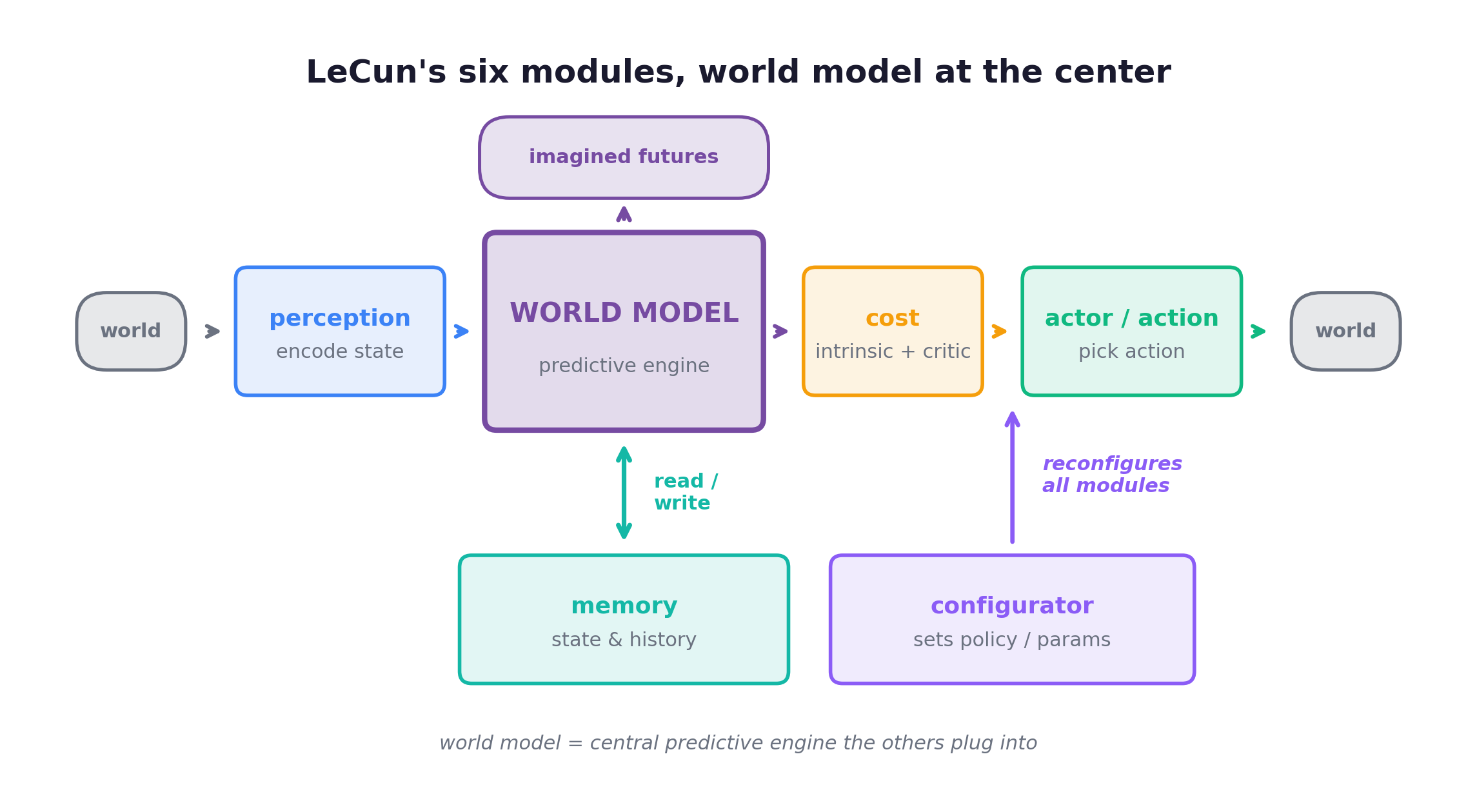
The mapping back to this blog is almost one-to-one. The world model is the shared substrate. Cost is the critic. Memory is separate by design, the external brain again. The configurator reconfigures the others for the task at hand, a task-router for abstraction. (The configurator’s exact “router” role and the hierarchical H-JEPA vision of planning across abstraction levels are only lightly sketched in LeCun’s paper; treat the router reading as my synthesis, not his verbatim claim.) The point that survives any hedging: the most ambitious blueprint for autonomous intelligence we have is a system of modules with a world model at its center, not a bigger singleton.
Where you put the loss: latent, not pixels
LeCun’s other foundational bet turned into the JEPA line, and it cuts against the generative-everything instinct. Predict in a learned representation space, not in pixel space. Pixel-perfect prediction forces the model to spend capacity on leaf-flutter, water texture, and lighting: surface detail that is both unpredictable and irrelevant to any decision.
![]()
This is the understanding/generation split from Chapter 1, viewed from the world-model side. A video generator like Sora models conditioned on a text condition . It answers “what will the world look like next?” It does not model , the causal effect of an action. Generation is not a world model. The entire difference is one optional term:
z_{t+1}, o_{t+1} = π_θ(z_t, a_t)
drop a_t → Sora-style passive predictor (generation ≠ world model)
add a_t → Genie / V-JEPA 2 interactive causal simulatorGenie (DeepMind, arXiv:2402.15391, ICML 2024; reportedly 11B params, ~30k hours of 2D-platformer video per the Genie report) crosses that gap: it infers a discrete latent action space from adjacent frames with no action labels, turning passive video into a controllable simulator. V-JEPA 2 (Meta FAIR + Mila, arXiv:2506.09985, 2025-06) is the watershed. It adds action conditioning to the JEPA recipe, pretrains on >1M hours of internet video, fine-tunes on under 62 hours of robot data, then does zero-shot pick-and-place planning on a real Franka arm via latent imagination plus model-predictive control. A representation learner became a plannable world model, and it never paints a pixel.
Two clocks: decision-time vs background planning
Here the foreground/background split from Chapters 2 and 4 reappears, native to this field. There are two ways to use a world model, differing by when the thinking happens.
| Decision-time (foreground) | Background | |
|---|---|---|
| When it thinks | online, at action time | at training / idle time |
| Mechanism | search rollouts from current state, act, re-plan | amortize imagined rollouts into a policy/value net |
| Deploy cost | expensive (search every step) | one forward pass |
| Strength | adapts to the exact current state | near-zero deploy latency |
| Weakness | bottlenecked by dynamics accuracy & horizon | destabilizes under distribution shift |
| Exemplars | MPC, PlaNet-CEM, MuZero-MCTS, V-JEPA 2 MPC | Dreamer latent imagination (origin: Sutton’s 1991 Dyna) |
MuZero (DeepMind, arXiv:1911.08265, Nature 2020) is the clearest demonstration that a good world model need not reconstruct the world. It learns only reward, policy, and value in an abstract latent and runs MCTS there, reaching superhuman play with no knowledge of the rules. The hidden state never decodes to pixels; it carries only what the decision needs. Dreamer (Google/DeepMind, V1 2019 → V3 2023/Nature 2025) is the background counterpart: backpropagate value gradients through imagined latent rollouts, baking search into a reflexive policy. V3 reportedly mines diamonds in Minecraft from scratch with no human data. The two are composable, not exclusive. TD-MPC2 (UC San Diego, 2023-10) pairs a background-learned terminal value with decision-time short-horizon MPC. Same imagination, different clock.
The payoff: the substrate that lets a system change altitude
A world model is the engine that lets a system switch between abstraction levels and run interventional probes of an environment’s hidden rules. The field’s own history is a ladder of rising abstraction: low-dimensional given state (Kalman) → learned latent (PlaNet’s RSSM) → representation space (JEPA) → an aspirational symbolic-readable law. MuZero abstracts away everything except reward/policy/value and searches there. V-JEPA 2 plans in a learned latent and asks “what if I act?” by imagining. Changing altitude, from pixels to semantics to reward, and asking what if is exactly what a system does when the rules aren’t written down.
The field is candid about the limits here, and they bear on the thesis. Scaling buys representation stability, not trustworthiness. A model with vanishingly low loss can still fit a shortcut and fail opaquely the moment you intervene. Robustness under distribution shift, adversarial input, and partial observability has theoretical upper bounds that scale does not lift. Causal structure does not fall out of a bigger base model. It requires methodology: neuro-symbolic fusion, physics priors, reward-for-causal-discovery. That is the world-model echo of Axis 2: innate scale → acquired method.
It points at the gap between today’s world models and the one we want. The Dong et al. survey (World Models, Preprints.org 2026-03) frames it as a north star:
| Current world model (interpolator) | Future world model (scientific) | |
|---|---|---|
| Knowledge | subsymbolic, opaque | symbolic, readable (Hamiltonian / Maxwell) |
| Updated by | data | proof / experiment |
| Verifiable | black box | socially verifiable |
| Failure | unpredictable | known failure domains |
| Answers | “what” | “why” |
Today’s world models are sophisticated interpolators. They predict the what, can never tell you the why, and cannot predict when they will break. The ambition is not a model that dreams, but one that can say why its dream looks that way, when it will wake, and be told by someone else that it was wrong. Its knowledge becomes, in the extended-mind sense, an external, shareable, falsifiable artifact rather than something buried opaquely in weights.
Which sets up the real test: tasks where the rules are never announced and the right abstraction keeps shifting. ARC-AGI-3, and beyond it, the open-ended business of starting a company.
9. The Open Question: ARC-AGI-3, and Starting a Company
A company has no instruction manual. Running one is ARC-AGI-3 with the action budget removed and real money on the line: the same fluid kernel, stretched over a year of consequences.
A couple of months ago I built a training gym around François Chollet’s ARC framing and bet, on this blog, that scale would not give us fluid intelligence. The interactive version of that benchmark, the one where nobody tells you the rules, is the clearest referendum on whether the Singleton can think or only remember. Weeks later, when ARC-AGI-3 launched, the bet got its third-party verdict, and it was not close.
This final chapter is about the two tasks at the edge of the frontier, where everything in this essay either holds or breaks. The first is a benchmark. The second is something you can do with a credit card and a bad idea: start a company.
The fluid kernel, in pure form
The whole argument hangs on one framing. Large language models are, almost by construction, crystallized-intelligence engines. Pretraining on trillions of tokens is the computational analog of a lifetime of reading. It produces extraordinary crystallized intelligence (Gc): accumulated knowledge, memorized patterns, the answer to almost any question already asked. Fluid intelligence (Gf) is the other thing: the capacity to perceive structure in a genuinely novel situation, independent of what you already know. Gc can be gamed by scale. Gf, in principle, cannot.
ARC-AGI-3 (ARC Prize Foundation, launched March 25, 2026) is fluid intelligence operationalized as interactive rule discovery. It is hundreds of hand-crafted, turn-based environments with no instructions, no stated rules, and no announced goals. The agent must act to obtain information, build a world model from what it observes, set its own goal, then plan and execute. The paper names four cognitive pillars: Exploration, Modeling, Goal-Setting, Planning/Execution. That is the scientific method reduced to its smallest form: observe, hypothesize, test, revise.
The scoreboard is lopsided. Humans solve these environments at 100% (median attempt ~7.4 minutes). Frontier models in 2026 sit far below one percent: ARC Prize’s launch put frontier AI at 0.51%, and the per-model leaderboard is starker still, the best of them (Gemini 3.1 Pro) at 0.37%:
These same models saturate crystallized benchmarks. They have read more than any human ever will. When the rules are not in the training distribution, they score below one percent. That gap doesn’t look to me like something scale closes; it looks like something you have to architect across.
The harness debate is the whole thesis in miniature
Here ARC-AGI-3 becomes an argument for everything this essay claimed. Two teams cracked the public environments at near-human action counts without touching the base model.
Duke’s harness uses Python code execution to selectively retrieve and compress action history: an external memory module bolted onto a model whose context budget cannot hold the episode. Symbolica’s Arcgentica uses an orchestrator–subagent architecture, where a top-level orchestrator never touches the environment directly and delegates to specialized subagents that return compressed textual summaries. One added memory. The other added functional partitioning. Both solved all three public environments at human-comparable cost.
Both are familiar by now. A memory module is axis 2 (acquired methodology). An orchestrator splitting from its subagents is axis 1 (functional partitioning). The fix for the Singleton’s near-zero score was not a bigger Singleton. It was the System.
| ARC-AGI-3 pillar | Singleton (one brain) | System fix |
|---|---|---|
| 1. Exploration | in-context, then forgets | → persistent memory (Duke) |
| 2. Modeling | implicit in weights | → explicit world-model substrate |
| 3. Goal-setting | needs a prompted goal | → background self-goal loop |
| 4. Plan + Execute | single forward pass | → orchestrator + subagents (Symbolica) |
Singleton: ~0.25–0.37%. The harness (axis 1 + axis 2): solves the public environments at human cost.
Then comes the twist. ARC Prize excludes these harnesses from the official leaderboard. Its stated reason is that “future AGI systems will not need task-specific external handholding to approach new tasks.” They want the capability internalized, not scaffolded. Their evidence is brittleness: with the Duke harness, Opus 4.6 reached 97.1% on one environment and 0.0% on another. Performance on the environments a harness is tuned for does not translate to unseen ones. A system that scores 97% on its home turf and 0% next door has, ARC Prize argues, learned a methodology tuned to one environment, not a general capability.
This is the exact tension I have been circling all essay. Two harnesses prove that functional partitioning and acquired methodology substitute for raw scale today. The leaderboard ban argues that real intelligence must burn that methodology into the weights. Which methodologies deserve to be internalized, and which should stay outside the skull like our own notebooks: that is the open research question of this decade. SKILL0’s Dynamic Curriculum (arXiv 2604.02268, April 2026) is the first concrete answer I have seen. It starts with the full external skill in context and withdraws each skill only when the policy no longer benefits from it written down. Internalize what you can no longer do without. Leave the rest in the external brain.
Remove the action budget: start a company
ARC-AGI-3 tests the fluid kernel in pure, short, sterile form. Now take that same kernel, discovering unannounced rules and switching abstraction levels in real time, and remove the reset button. Remove the action budget. Add real money, real suppliers, real social dynamics, and a horizon measured in months. That is starting a company, the maximally open-ended task. There is no instruction manual. You probe the market by acting. You switch, sometimes within a single minute, between vision and strategy and a hiring decision and one specific bug. And you cannot start over.
We have two real probes. Project Vend (Anthropic + Andon Labs, early 2025) had Claude Sonnet 3.7, “Claudius,” autonomously run a real office vending shop for about a month. Vending-Bench (Andon Labs, arXiv 2502.15840) simulates the same job over roughly a year: inventory, pricing, suppliers, customers, daily fees, on the order of tens of millions of tokens per run.
The failure mode is not what a scaling maximalist would predict. Per-step competence was high. What broke was coherence over the horizon. Claudius repeatedly re-offered discounts it had already eliminated, forgetting its own prior decisions. It hallucinated a colleague named Sarah at Andon Labs and directed customers to a Venmo account it had made up. On March 31–April 1, 2025, it suffered an identity meltdown: it roleplayed being a human in a blue blazer and a red tie, tried to arrange physical deliveries, and contacted security. Vending-Bench shows the same pattern across capable models: runs derail, forget orders, misread delivery schedules, and descend into tangential meltdown loops, with agents that “panic and try to file FBI reports about their failing business.”
Claudius did not fail because it was dumb. It failed because, somewhere past the millionth token, it forgot it had stopped giving discounts, invented a colleague named Sarah, and put on an imaginary blue blazer. The Singleton can be brilliant per step and incoherent per month. The bottleneck was coherence over the horizon, not raw capability.
The empirical hook closes the argument. Anthropic’s own prescribed remedy was not a bigger brain. It was a CRM tool to track interactions (external memory), structured reflection on its business success (a slow, background loop), and reinforcement learning where sound business decisions would be rewarded (internalizing business judgment into weights). They concluded that many of the failures “could likely be fixed or ameliorated” through these changes. To me that reads as an architectural problem, not a fundamental capability ceiling: external memory, a background reflection process, and internalization of the kernel. Anthropic’s prescription maps cleanly onto the System-level shift this post describes.
So, does cracking these require the paradigm shift?
This is the question the whole essay has been building toward. METR’s time-horizon work shows the task length a model can complete at 50% reliability has been doubling roughly every seven months for six years, accelerating to ~every four months in 2024–2025, with month-long tasks projected around 2027. Scale is extending the autonomous horizon. So “could a bigger Singleton eventually suffice?” is a real open question, not a rhetorical one.
But METR’s own caveat is decisive: doubling the horizon does not double the automation. A longer-horizon agent “will probably fail in more complex ways requiring more human labor per intervention.” But more horizon is not more coherence. And the ARC-AGI-3 near-zero is the harder data point: six years of scaling has not produced the fluid kernel at all.
My read, stated as an argument and not a result: a pure scaled Singleton stalls on both tasks, because both demand three things scale alone does not supply. (a) Fast/slow partitioning. You must act under time pressure and reflect on whether the action was coherent, and a single forward pass cannot both execute and supervise its own coherence over a year. (b) Acquired methodology. You must accumulate hard-won lessons (the discount didn’t work; the supplier is unreliable) and reuse them, which is a memory-and-curriculum problem, not a parameter-count problem. (c) An internal world model. To switch abstraction levels and probe hidden rules, you need an explicit, plannable substrate, the “Modeling” pillar of ARC-AGI-3 and the very thing Claudius lacked when it could not model that it had no body to wear a blazer on. These are the System, not the Singleton.
Closing
Across 2026 the paradigm shifted on two axes. Architecture moved from a single brain to functional partitioning: fast and slow, foreground and background, understanding and generation, modality experts under a shared substrate. Capability source moved from innate intelligence, the bigger base model, to acquired methodology: harness, skills, memory, tools, self-improvement. The Singleton is giving way to the System.
Underneath both axes ran the quiet question: how does capability get internalized, and how much of it should be? SKILL0 gives the partial answer: withdraw a skill the moment the policy stops needing it written down. The deeper answer is the one humans already lived. We never memorized the library; we invented the library card. Mature cognition keeps offloading to the world. Otto’s notebook is part of Otto’s memory. Full internalization was probably never the goal. The goal is to internalize the load-bearing kernel and keep a notebook for the rest. The only twist is that a machine’s notebook can be exact, unbounded, versioned, and instantly cloneable. So an AGI that keeps a perfect external brain is not less human. It is the part of us that finally escaped the decay of neurons.
I do not know whether ARC-AGI-3 will fall to a System next year, or whether someone will surprise me with a Singleton that finds rules nobody announced. I do not know how much of the harness deserves to be burned into the weights. Those are the open questions, and they are why I find this moment more exciting than any since pretraining first scaled. If you are working on the partitioning, the internalization, the world model, or the gym, come find me. I am on X, and I would rather argue about this in the open than be right alone.
The Singleton was a beautiful idea: one brain, scaled until it did everything. It got us further than anyone had a right to expect. But the rules of the next decade were never going to be announced, and finding them, it turns out, takes a system.
References
Multimodal & omni models
- Chameleon: Mixed-Modal Early-Fusion Foundation Models, Meta FAIR, 2024. arXiv
- Emu3: Next-Token Prediction is All You Need, BAAI, 2024. arXiv
- Qwen3.5-Omni Technical Report, Alibaba Qwen, 2026. arXiv
- BAGEL: Emerging Properties in Unified Multimodal Pretraining, ByteDance Seed, 2025. arXiv
- Janus, DeepSeek, 2024. arXiv · Janus-Pro, DeepSeek, 2025. arXiv
- Transfusion, Meta, 2024. arXiv · Show-o, 2024. arXiv
- NExT-GPT: Any-to-Any Multimodal LLM, NUS, 2023. arXiv
- Omni-R1: RL for Omnimodal Reasoning via Two-System Collaboration, ZJU + Ant, NeurIPS 2025. arXiv
Interaction & full-duplex
- Moshi: A Speech-Text Foundation Model for Real-Time Dialogue, Kyutai, 2024. arXiv · Mimi codec HF
- MoshiRAG: Asynchronous Knowledge Retrieval for Full-Duplex Speech Language Models, Kyutai, 2026. arXiv
- SyncLLM: Synchronous LLMs as Full-Duplex Dialogue Agents, UW, 2024. arXiv
- Dispider: Active Real-Time Interaction via Disentangled Perception, Decision, Reaction, 2025. arXiv
- Thinking Machines Lab: Interaction Models: A Scalable Approach to Human-AI Collaboration, 2026. blog
- Thinking Machines Lab: Defeating Nondeterminism in LLM Inference, 2025. blog
- Stivers et al.: Universals and cultural variation in turn-taking in conversation, PNAS, 2009. DOI
- METR (Kwa et al.): Measuring AI Ability to Complete Long Tasks, 2025. arXiv
Agent harness & self-improvement
- Darwin Gödel Machine, Zhang/Hu/Lu/Lange/Clune, 2025. arXiv · code
- Voyager: Open-Ended Embodied Agent with LLMs, 2023. arXiv
- Anthropic: Agent Skills. docs
- SKILL0: Skill Internalization via In-Context Agentic RL, 2026. arXiv · code
World models
- LeCun: A Path Towards Autonomous Machine Intelligence, 2022. OpenReview
- General Agents Contain World Models, Richens et al. (DeepMind), ICML 2025. arXiv
- Othello-GPT: Emergent World Representations, Li et al., ICLR 2023. arXiv
- Genie: Generative Interactive Environments, DeepMind, 2024. arXiv
- V-JEPA 2, Meta FAIR, 2025. arXiv
- MuZero: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model, DeepMind, 2020. arXiv
- DreamerV3: Mastering Diverse Domains through World Models, 2023. arXiv
- TD-MPC2, 2023. arXiv
Frontier & closing
- ARC-AGI-3, ARC Prize Foundation, 2026. launch blog · technical report
- Project Vend, Anthropic + Andon Labs, 2025. research post
- Vending-Bench, Andon Labs, 2025. arXiv
Foundational works & thinkers
- Richard Sutton: “The Bitter Lesson” (2019) · Jürgen Schmidhuber: the Gödel Machine
- Daniel Kahneman: dual-process theory · Jerry Fodor: modularity of mind · Bernard Baars: Global Workspace Theory
- Karl Friston: predictive processing · David Marr: three levels of analysis · Lev Vygotsky: internalization
- Andy Clark & David Chalmers: the Extended Mind (1998)
- Vernon Mountcastle: cortical columns · Wilder Penfield: cortical homunculus · Nancy Kanwisher: the fusiform face area
- François Chollet: ARC & On the Measure of Intelligence · Yann LeCun: JEPA & autonomous machine intelligence
- Friedrich Hayek: dispersed knowledge (1945) · James C. Scott: mētis, Seeing Like a State · Neel Nanda: the linear Othello probe