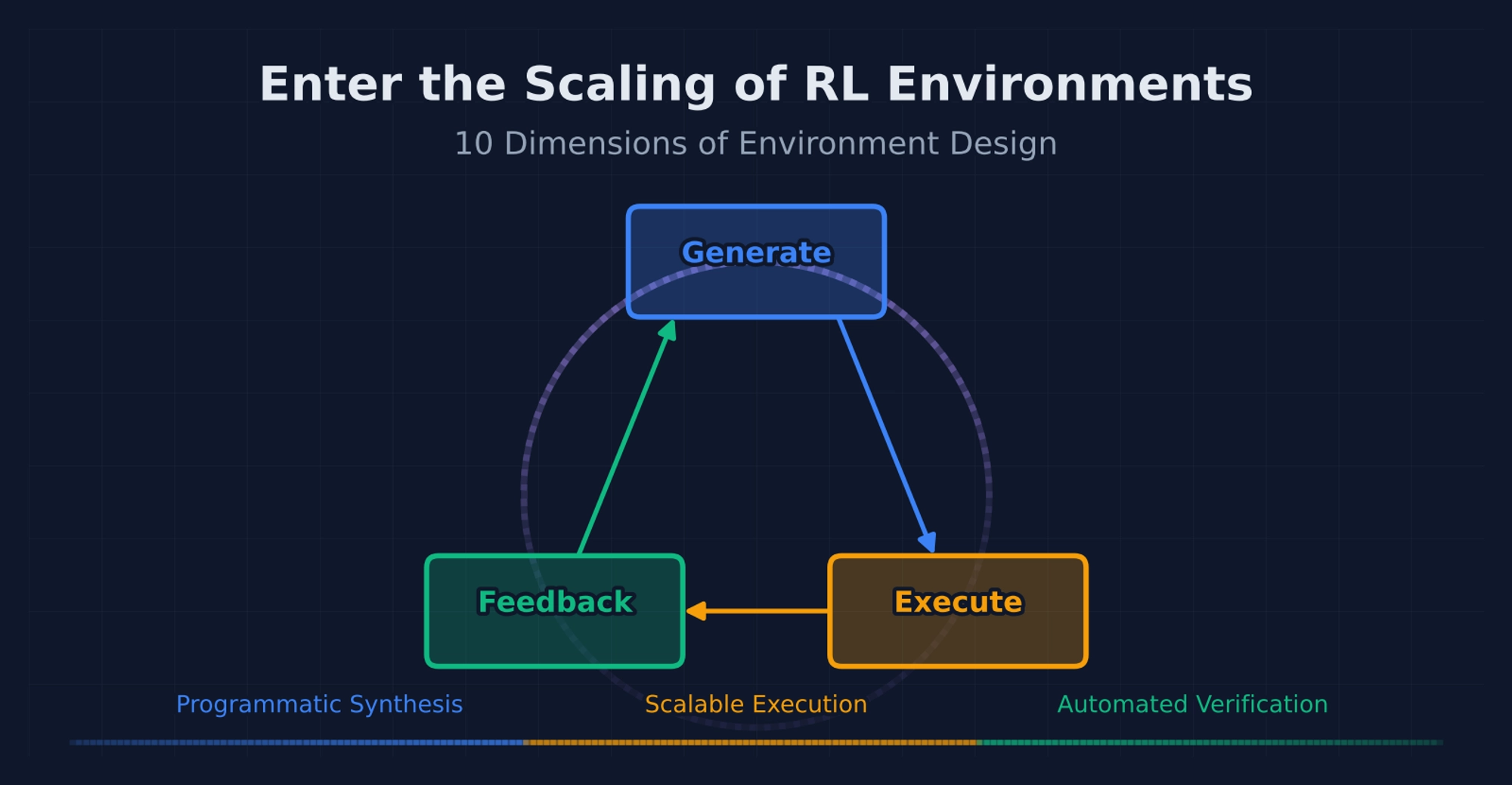
Over the past years, scaling has meant more parameters, more data, more FLOPs, i.e., the Chinchilla paradigm. But there’s a new dimension that may matter more for agentic intelligence: the environments themselves.
I’ve been studying how leading labs approach RL environment design for the past weeks by reviewing the literature. This post is a distillation of what I found. The central thesis is simple: the environment is no longer a passive container for evaluation. It is a data engine, and scaling it is the next frontier.
What this post covers:
- Foundations: From LLM to Agent, why RL, environment as data engine
- The GEF Loop: The core framework, 10 scaling dimensions across Generation, Execution, Feedback
- Task Generation: Complexity, dynamics, and diversity scaling
- Task Execution: Interactivity and realism
- Feedback: The five dimensions of reward design
- Implementation: Infrastructure for agentic RL at scale
- Environment Synthesis: Auto-generating training worlds
- Embodied AI: From virtual to physical environments
- Multi-Agent: When agents become each other’s world
- Future Directions: Open problems and roadmap
1. Foundations
The first generation of LLMs were text generators. The model’s world was a context window of tokens, no tools, no memory, no persistent state. The LLMs shipping today are agents: systems that reason about goals, plan multi-step strategies, invoke tools, observe results, and adapt.
- Qwen-Agent and Claude Code demonstrated autonomous software engineering: reading codebases, writing patches, running tests, iterating on failures.
- OpenAI’s Computer Use Agent (CUA) showed models controlling a full desktop environment.
- Deep Research proved that agents could conduct hour-long research sessions, synthesizing dozens of sources.
The common thread: all of these required the model to interact with an environment over multiple turns. This is fundamentally a reinforcement learning problem.
Why RL Over SFT
| Dimension | SFT | RL |
|---|---|---|
| Data source | Expert demonstrations (expensive, limited) | Agent-generated via environment interaction |
| Data scale | Bounded by annotation budget | Theoretically unlimited |
| Exploration | None (imitates demonstrations only) | Explores novel strategies autonomously |
| Generalization | Poor beyond demonstration distribution | Discovers generalizable behaviors |
| Ceiling | Bounded by demonstrator quality | Can exceed human-level |
| Cost trajectory | Linear: more data = more human labor | Front-loaded: environment investment amortizes |
The core issue with SFT is the data bottleneck. A single SWE-bench-style demonstration takes a skilled engineer 30-60 minutes. At $100+/hour, 100K demonstrations costs $5M-$10M for a single domain, and that’s a lower bound that doesn’t account for quality control and iteration. RL sidesteps this entirely: given an environment that generates tasks and verifies solutions, the agent produces its own training data.
Key RL Concepts
Two terms that recur throughout this post: RLVR (RL from Verifiable Rewards) skips the reward model entirely and uses programmatic verification instead, pioneered at scale by DeepSeek-R1. GRPO (Group Relative Policy Optimization) generates G completions per prompt and normalizes advantages within the group. It’s the dominant algorithm today. The expensive part is rollouts (running the policy in the environment), which consume 80-90% of wall-clock time.
The Paradigm Shift: Environment as Data Engine
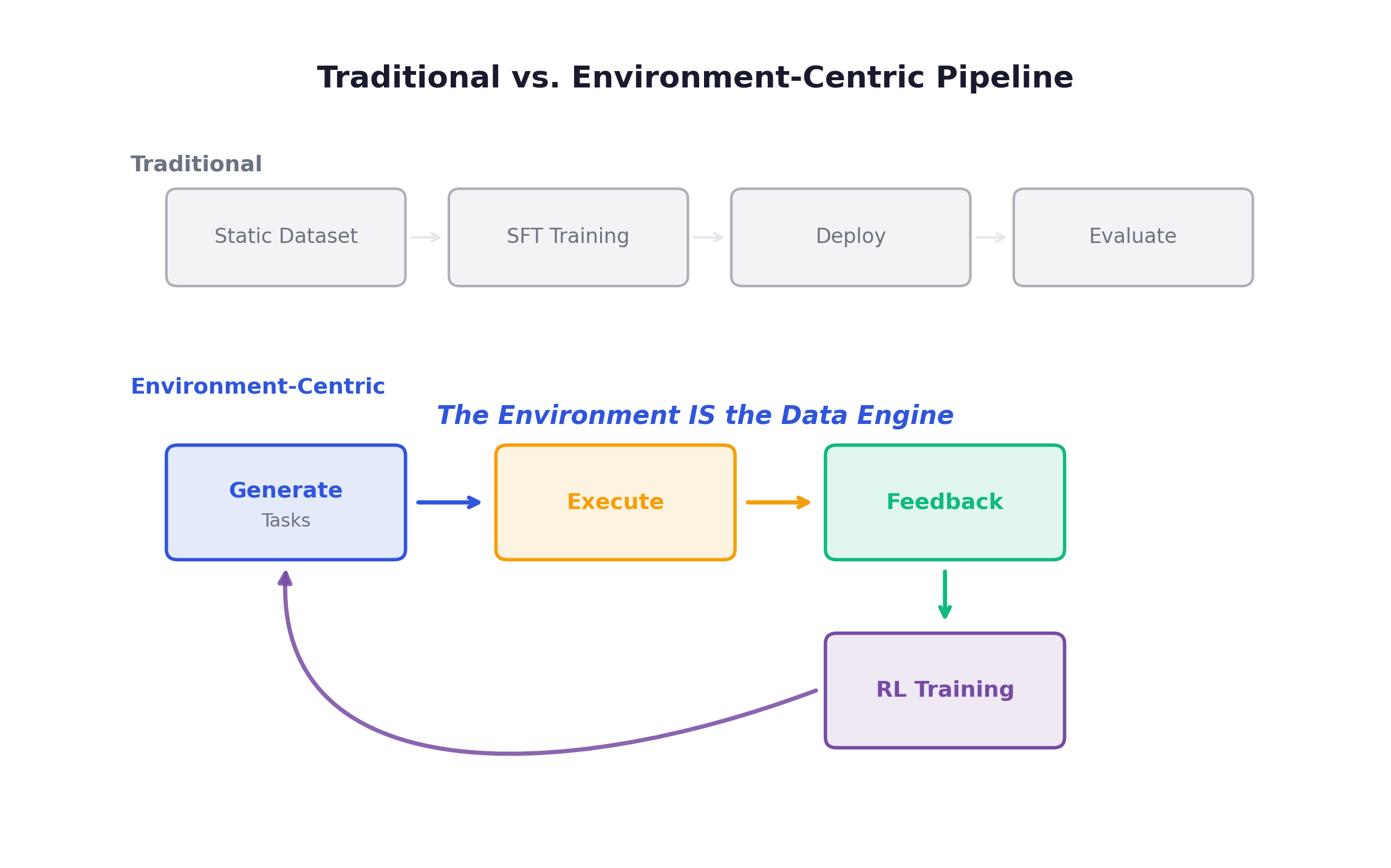
This is why environment scaling matters. If the environment is your data engine, then the quality, diversity, and complexity of your environments directly determine the capability of your agent.
What Is Environment Scaling
“Environment scaling” does not mean “make the environment bigger.” It means systematically expanding environments along multiple dimensions:
- Solve the data hunger problem. A single benchmark with 500 problems saturates quickly.
- Improve generalization. Training across diverse environments produces robust, transferable skills.
- Strengthen tool use. Complex environments force sophisticated tool-use behaviors.
- Reduce marginal training cost. Once built, generating additional training data is nearly free.
The Cost Is Real
- Anthropic reportedly spends tens of millions per year on RL environment development.
- OpenAI has reportedly signed seven-figure contracts with environment providers.
- Poolside built an entire platform around environment infrastructure: 800,000+ indexed repositories, OCI container isolation, millions of concurrent executions.
- MiniMax launches 5,000+ isolated environments within 10 seconds, with concurrent operation of tens of thousands.
Environment is now a primary infrastructure investment, on par with GPU clusters.
Three Types of Environments
| Property | Real-World | LLM-Simulated | Programmatic |
|---|---|---|---|
| Examples | Robots, live APIs | GPT-4 as user simulator | Code sandboxes, formal verifiers |
| Scalability | Very low (physical) | Medium (LLM cost) | Very high (commodity compute) |
| Consistency | Low (non-deterministic) | Low (hallucinations) | High (deterministic) |
| Controllability | Minimal | Moderate (prompting) | Full (programmatic) |
| Cost per episode | $1-$100+ | $0.01-$1 | $0.0001-$0.01 |
Current consensus: programmatic environments are the most promising path. They offer 3-4 orders of magnitude lower cost with high consistency. LLM-simulated environments remain useful for bootstrapping in domains where programmatic environments don’t yet exist; real-world environments are necessary for robotics.
If you’re familiar with classical RL (Atari, MuJoCo), it’s worth understanding how different the agentic setting is. The differences are not just quantitative; they’re qualitative:
| Dimension | Classical RL (Atari, MuJoCo) | Agentic RL (LLM Agents) |
|---|---|---|
| State space | Pixels or low-dim vectors | Natural language + structured data |
| Action space | Discrete keys / continuous control | Tool calls + natural language |
| Episode length | Fixed, short (hundreds of steps) | Variable, long (1-100+ turns) |
| Environment cost | Near-zero (simulator frame) | $0.01-$100+ per episode |
| Training iterations | Millions | Hundreds to low thousands |
| Rollout bottleneck | Negligible | 80-90% of wall-clock time |
In classical RL, environments are cheap and fast. You run millions of Atari frames per hour. In agentic RL, each rollout may involve spawning a Docker container, cloning a git repo, running a test suite, and waiting for an LLM to generate multi-turn responses. This cost asymmetry is why environment design matters so much more in the agentic setting.
The key insight: task generation and feedback are environment responsibilities. The quality of the entire RL pipeline is bounded by the environment’s ability to generate meaningful tasks and provide accurate feedback.
2. The GEF Loop
Every RL training loop, once you strip away the framework-specific abstractions, is really doing three things: generating tasks, executing them, and providing feedback. I find it useful to think of this as a Generation-Execution-Feedback cycle. Once you frame it this way, the entire field of environment scaling becomes easier to reason about.
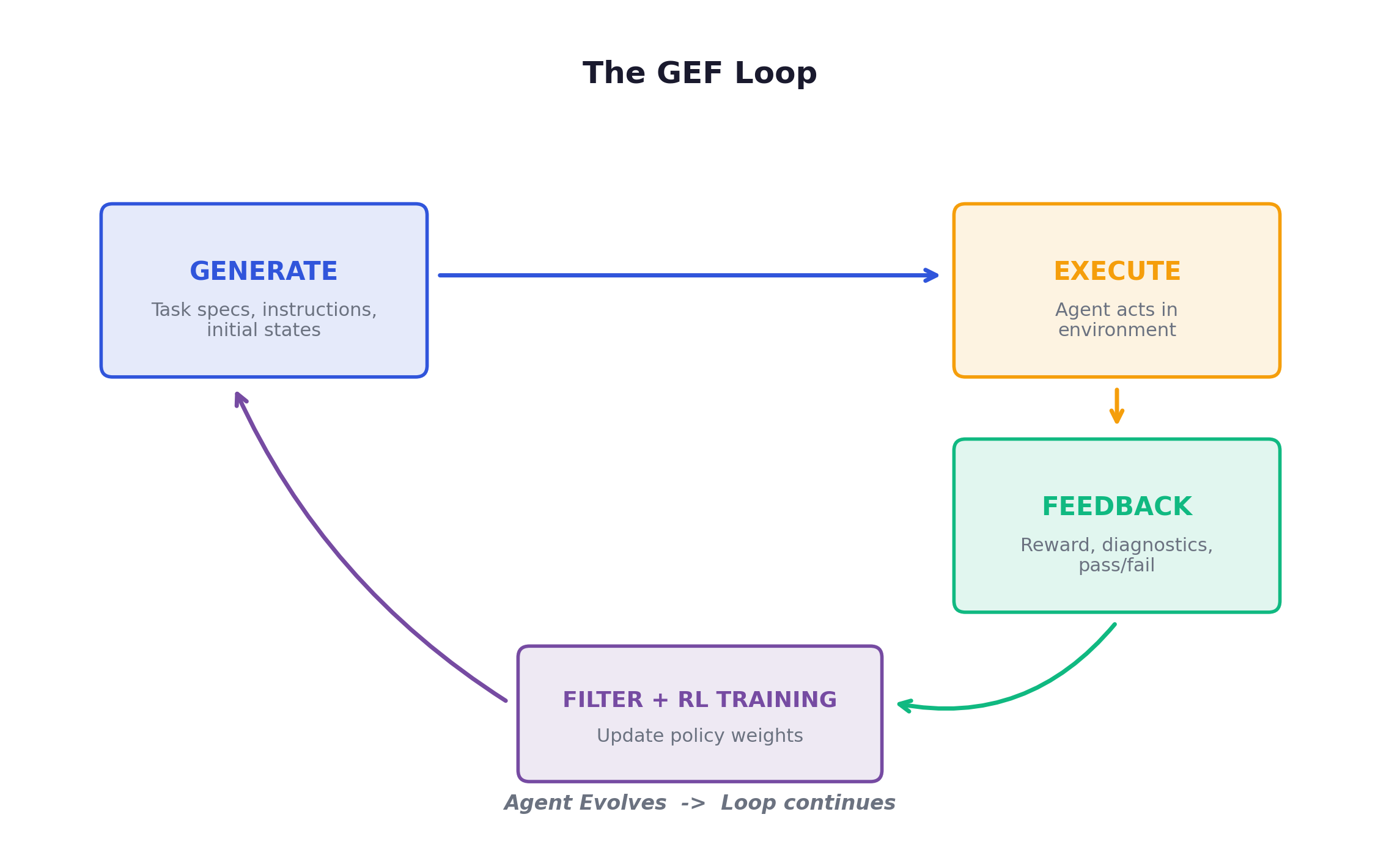
Scaling any one stage while neglecting the others produces diminishing returns. Diverse tasks with noisy feedback → garbage. Precise feedback with monotonous tasks → overfitting. The three stages must be scaled in concert.
Why “Environment-Centric” Matters
Three developments justify shifting attention from agent to environment:
- The data bottleneck has moved. The constraint is no longer the agent or algorithm; it’s the environment. Algorithmic innovations (GRPO, DAPO) have plateaued in marginal gains; environment diversity is the new source of capability jumps.
- Single-environment saturation is real. Train a code agent on HumanEval-style problems long enough and performance plateaus. The task distribution ran out of entropy.
- Generalization requires environmental diversity. An agent trained across 100 different environments learns transferable skills.
The 10 Scaling Dimensions
| Stage | Dimension | Low End | High End |
|---|---|---|---|
| Generation | Complexity | Single-step Q&A | Multi-day project |
| Generation | Dynamism | Static task bank | Real-time adaptive curriculum |
| Generation | Diversity | Single template | Cross-domain heterogeneous tasks |
| Execution | Interactivity | Single-turn submit | Multi-turn branching + tool orchestration |
| Execution | Realism | Toy sandbox | Production-faithful replica |
| Feedback | Density | Only at episode end | After every action |
| Feedback | Granularity | Binary pass/fail | Multi-dimensional rubric |
| Feedback | Automation | Fully manual | Fully programmatic |
| Feedback | Objectivity | Subjective human judgment | Deterministic check |
| Feedback | Robustness | Easily gamed | Adversarially robust |
These 10 dimensions are not independent: scaling one often requires or enables scaling others. For example, increasing task complexity usually demands higher interactivity (complex tasks require multi-step execution) and denser feedback (the agent needs more guidance to learn from harder tasks).
Concrete example: conference scheduling. Consider training an agent to plan academic conferences. Complexity scales from “schedule 5 talks into 2 sessions” (Level 1) to “plan the full ACL 2026: 500+ papers across 15 tracks, keynotes, workshops, catering, visa letters” (Level 3). Diversity means varying not just conference size but the type of event (corporate retreat, music festival, medical symposium), the constraints (budget limits, accessibility, hybrid timezone formats), and the input format (structured JSON, unstructured email thread, verbal transcript).
At the high end of interactivity, the agent conducts a multi-turn dialogue:
Agent: "What's the budget for catering?"
Env: "$45,000 for 3 days, 600 attendees."
Agent: "Are there dietary restrictions I should account for?"
Env: "22% vegetarian, 8% vegan, 5% halal, 3% gluten-free."
Agent: [submits initial schedule]
Env: "Conflict: Dr. Smith is scheduled for 3A and 3B simultaneously."
Agent: [revises and resubmits]Each interaction provides information the agent couldn’t have inferred, forcing it to develop information-seeking and iterative-refinement behaviors. Feedback scales from binary pass/fail to a multi-aspect rubric ({conflict_free: 0.95, budget_compliant: 1.0, preference_satisfaction: 0.68}). A robust reward function penalizes gaming strategies like “schedule everything sequentially with huge gaps to avoid conflicts.”
Generator-Verifier Asymmetry
The structural issue that determines which domains are tractable for RL today:
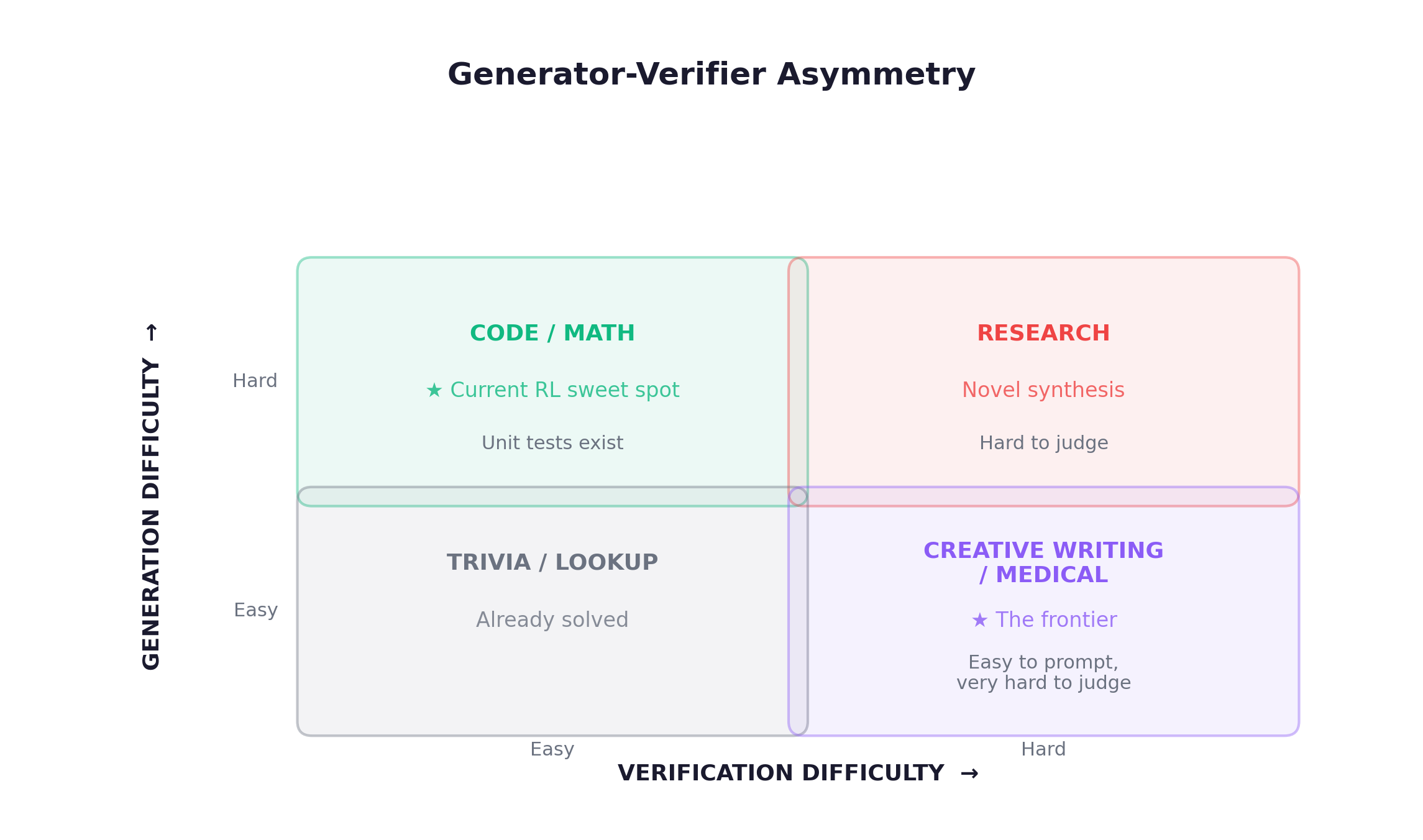
Code and math dominate current RL because verification is cheap and automated. Expanding to the right side of this diagram is one of the most important open problems.
3. Task Generation
The quality of an agent is bounded by the quality of the challenges it faces. Task generation is where the real curriculum lives.
3.1 Complexity Scaling
Four levels of structural difficulty:
Level 1: Single-hop "Look up the weather in Tokyo."
Level 2: Sequential "Find user → get orders → compute total."
Level 3: Graph-based Multiple paths, conditional branches, dependencies
Level 4: Hierarchical High-level goals decompose into sub-goalsComplexity scales along depth (longer tool chains) and width (parallel subtasks). TaskCraft (2025) parameterizes both and confirms that scaling simultaneously is more effective than either alone.
The practical challenge: as depth increases, context accumulates to 32K+ tokens. Asynchronous RL frameworks (Slime, ProRL Agent) allow rollouts of varying lengths to complete independently.
3.2 Dynamic Scaling (Curriculum Learning)
Static task distributions are a dead end. The most effective training signal comes from tasks right at the boundary of the agent’s current capability.
Approach 1: Success-Rate-Based (RLVE, RL with Verifiable Environments)
# RLVE's sliding window (simplified)
class AdaptiveDifficulty:
def update(self, success: bool):
self.window.append(success)
rate = sum(self.window[-WINDOW_SIZE:]) / WINDOW_SIZE
if rate > 0.9: # agent is crushing this level
self.h += 1 # unlock harder
self.l += 1 # skip easy onesApproach 2: Challenger-Solver Co-Evolution (Tool-R0). Train a Generator alongside the Solver. The Generator is rewarded for producing tasks where the Solver’s success rate falls within 20-80%. Critical finding: the Generator must co-evolve, not stay fixed.
Approach 3: Bidirectional Variation (AgentGen). Simultaneously adjusts difficulty up and down per dimension based on agent performance.
3.3 Diversity Scaling
There are two levels of diversity, and they are not equally important. Task-level diversity means generating varied tasks within a single environment (e.g., different function calls in one API suite). Environment-level diversity means training across fundamentally different environments (hotel booking, healthcare, e-commerce, etc.). The latter is strictly more important because an agent trained in one environment, no matter how much data you generate, only learns the distribution of that environment. Different environments force the agent to learn transferable skills that generalize. Multiple papers converge on the same scaling law:
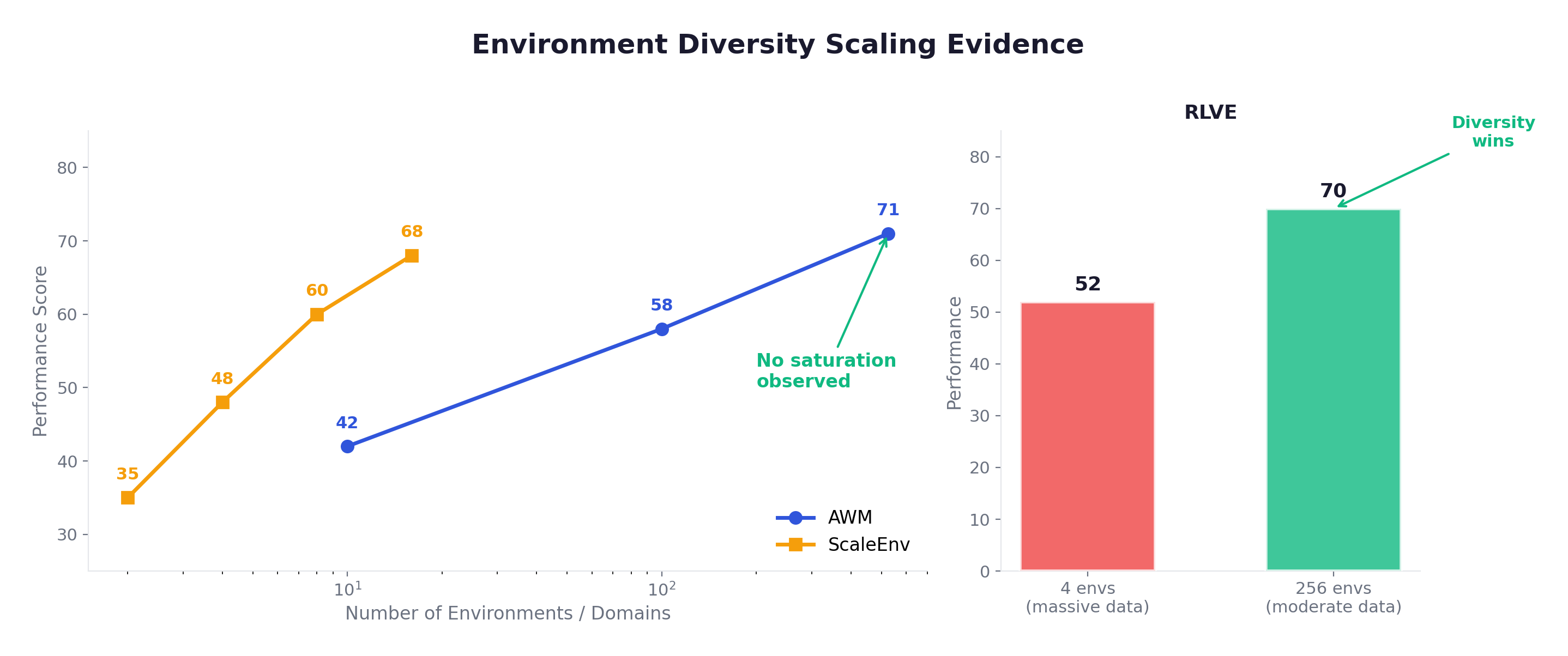
This is the single most important empirical finding: environment count is a scaling axis, and we’re still in the early, high-return phase.
A counter-intuitive insight from Andrews et al.: “Simple tasks in simple environments can be more effective than complex tasks in complex environments.” Clean signal from simple interactions beats noisy signal from complex ones.
3.4 2026 Frontier
LOGIGEN (Mar 2026) addresses a fundamental weakness of prior synthesis methods: generated tasks are sometimes impossible to solve due to missing tools, inconsistent DB states, or logical contradictions. LOGIGEN’s solution is a logic-first paradigm with triple-agent orchestration. The Architect designs the environment’s logical constraints. The Set Designer materializes those constraints into concrete DB states and tools. The Explorer verifies solvability by actually solving each task. This is Hard-Compiled Policy Grounding: every task is provably solvable and deterministically verifiable by construction, not by post-hoc filtering. 20K tasks across 8 domains, 79.5% on τ²-Bench.
HardGen (Jan 2026): Builds API dependency graphs from agent failure cases, synthesizing targeted hard samples. Difficulty tracks the agent’s evolving weaknesses.
4. Task Execution
There is a vast gap between “selecting the right API from a multiple-choice list” and actually calling that API, parsing a malformed JSON response, handling a 429 rate-limit error, adjusting your plan, and calling a fallback endpoint. Most benchmarks test the former. Real deployment demands the latter.
4.1 Interactivity Scaling
Non-interactive evaluation gives the agent a prompt and compares its output against a gold-standard action sequence via static string matching. Interactive evaluation lets the agent actually execute actions, observe real responses, and adapt in real time. Interactive is strictly more informative: it provides richer feedback (partial success is visible), allows exploration of alternative strategies, and produces trajectories that reflect realistic error-recovery behavior.
Interactivity scales along two axes: width (parallel tool calls, GUI + API switching, multi-modal observations) and depth (longer tool chains without context overflow). MiroThinker (2025) addresses depth by actively removing weak-relevance historical tool calls from the context, functioning as an attention mechanism over interaction history.
The cost problem is severe: every real API call has monetary cost (third-party charges), latency cost (100ms-10s per call), and context cost (verbose JSON responses eat the context window). GRPO (G=8) multiplies all of this by 8.
Solutions ordered by fidelity:
Real API calls ● Highest fidelity, highest cost
Offline DB snapshots ● Good balance (current mainstream)
LLM simulation (GTM) ● Most flexible, hallucination-prone
Static matching ● Cheapest, least informativeOffline DB snapshots have emerged as the sweet spot. The idea: take real-world data (user profiles, product catalogs, flight schedules), load it into a local database, and implement tools as programmatic operations on that database. The agent interacts with real data via real operations, but without external API calls, rate limits, or costs. AWM, ScaleEnv, and AgentScaler all use this approach. It provides realism (the data and operations have correct semantics), determinism (same inputs always produce same outputs), scalability (no external dependencies, arbitrary parallelism), and verifiability (ground-truth can be computed by comparing final DB states).
| Work | Interaction Mode | Key Contribution |
|---|---|---|
| RandomWorld (2025) | Programmatic tool gen | Massively diverse tool interactions |
| AppWorld (2024) | Real application sandbox | Interactive coding agent benchmark |
| MiroThinker (2025) | Context-managed tool use | Removes weak history for longer chains |
| OSWorld-MCP (2025) | GUI + MCP fusion | Bridges computer-use and tool-use |
| GTM (2025) | LLM-simulated tools | 1.5B model simulates 20K+ tools |
| WebWorld (2026) | Learned world model | 1M-trajectory web simulation |
4.2 Realism Scaling
For tool-use scenarios, the three implementation strategies (real APIs, LLM simulation, offline DB) represent different trade-offs along a realism-scalability frontier. Real APIs are the gold standard for realism but the worst for scalability: they change without notice, impose rate limits, and cost money at RL scale. Offline DB hits the practical optimum today.
For computer-use agents, realism progresses through three stages:
- Static screenshots: the agent sees a single image and outputs an action label. Brittle, no dynamics, no error recovery.
- Docker containers (WebArena): containerized websites with real content. The agent clicks, types, and navigates in a real browser. Limited to web, pre-configured sites.
- Real OS (OSWorld): full Ubuntu/macOS VM with real applications. The agent controls mouse and keyboard at pixel level, handling pop-ups, overlapping windows, and heterogeneous UIs.
The gap between stages 2 and 3 is substantial. Training in Docker and deploying on real OS produces measurable performance degradation: agents that work in clean containers can’t handle the visual clutter and unexpected UI state of a real desktop.
For multi-agent scenarios, each agent’s behavior is part of every other agent’s environment, requiring reliable async communication (MQTT) and decoupled clocks.
The core design principle across all these trade-offs: maximize the training signal per compute dollar. Real API calls give the highest signal per trajectory but the lowest trajectories per dollar. Static matching gives the most trajectories per dollar but the lowest signal per trajectory. The best systems today do both: realistic data and interactions at a cost that RL can afford.
2026 frontier: WebWorld trained a world model on 1M+ real web trajectories, rivaling Docker container fidelity while maintaining simulation scalability. If this approach generalizes, the realism-scalability trade-off may become significantly less constraining.
5. Feedback
In my experience, more RL projects fail at reward design than at any other stage. The model architecture is fine, the training loop runs, but the reward signal is too sparse, too noisy, or too biased. Getting feedback right is the make-or-break of agentic RL. The field has converged on five dimensions to think about this problem.
5.1 Density Scaling
Trajectory-level (single scalar at episode end) vs step-level (per-action feedback). Best results combine both.
2026 Breakthrough, RewardFlow: Dense rewards with zero additional model training. The insight: if you run K rollouts of the same task (which GRPO already does), you can extract all intermediate states and build a state graph connecting them. States that appear in successful trajectories but not failed ones are “necessary” states; states that appear in both are “irrelevant.” Using BFS or Personalized PageRank, you propagate the terminal reward backward through this graph, assigning each intermediate state a dense reward signal. No reward model training, no LLM judge, no additional inference cost:
| Method | Extra Model? | Density | Cost |
|---|---|---|---|
| Outcome Reward | No | Sparse | Free |
| Process Reward Model | Yes | Dense | High |
| LLM-as-Judge | Yes | Dense | High |
| RewardFlow | No | Dense | Free |
SOTA on 4 agentic benchmarks. The only requirement is multiple rollouts per task, which GRPO already provides.
5.2 Granularity Scaling
Reward granularity has evolved through four stages. Binary pass/fail tells you nothing about partial progress. A single scalar score (0.73) is better but opaque. Multi-dimensional scores break down performance by aspect but require manual dimension design. The current frontier is Rubrics as Rewards, which decompose requirements into individually verifiable checkpoints, similar to how a teacher grades with a rubric:
Task: "Book a flight SFO→NRT for John, March 15"
✓ Called flight_search with correct origin [1.0]
✓ Correct destination [1.0]
✗ Wrong date (used March 16) [0.0]
✓ Called book_flight with correct passenger [1.0]
→ Score: 3/4 = 0.75 (with per-item breakdown)Rubicon adds defense rubrics: items that penalize sycophancy and reward hacking.
5.3 Automation Scaling
The progression: RLHF → LLM-as-Judge → Training-based RM → RLVR → Agent-Synthesized Rewards.
LLM-as-Judge has systematic biases that are not minor. Verbosity bias: the judge prefers longer responses even when a shorter response is more correct. Position bias: placing the same answer in position A vs position B changes the preference 15-25% of the time. Egocentric bias: the judge prefers outputs that resemble its own generation style. Training RL on a reward signal with 20%+ noise is, at best, inefficient.
2026 Breakthrough, RLAR: The agent autonomously searches the internet for evaluation tools and synthesizes task-specific verifiers. Consider a concrete example: for a Japanese→English translation task, the RLAR agent searches the web, finds BLEU and COMET as standard evaluation metrics, locates reference implementations, and synthesizes a composite verifier that scores translations along multiple dimensions. No human needs to specify what “good translation” means. 10-60 point improvements across math, code, translation, and dialogue tasks. RLAR potentially collapses the Generator-Verifier Asymmetry by expanding the boundary of what counts as “easy to verify.”
5.4 Objectivity and Robustness
For easy-to-verify domains: RLVR (unit tests, answer matching). For medium-difficulty: hybrid verification where hard constraints are checked programmatically, soft constraints checked semantically. For hard-to-verify: pairwise comparison (BRPO).
Robustness requires handling both reward noise (probabilistic soft rewards, score differencing) and environment failures (async retry, caching, timeout budgets).
The Golden Rule of Feedback Design:
Dense but not too dense (per meaningful action, not per token). Structured but not too complex (match rubric to task). Automated but not biased (programmatic first, LLM where necessary). Adaptive but not volatile (periodic refinement).
6. Implementation
The algorithm is the easy part. GRPO fits on a whiteboard. What doesn’t fit on a whiteboard is how to run 4,000 Docker containers in parallel, each hosting a stateful agent session, while keeping GPU utilization above 70%. The real bottleneck in agentic RL has never been the loss function; it’s the infrastructure.
Different agentic scenarios have fundamentally different environment requirements:
- Tool-use agents need interaction breadth (many tools, MCP protocol) and depth (long tool chains without context overflow).
- Deep research agents need global caching (the same webpage shouldn’t be fetched twice across rollouts) and hour-long episode support.
- Coding agents need a full development setup per task: git repo at a specific commit, dependencies pre-installed, test suite available, all inside an isolated Docker container.
- Computer-use agents need a full OS with GUI state: mouse/keyboard control, screen capture, handling of pop-ups and notifications.
These diverse requirements make a one-size-fits-all environment framework impossible. Three system challenges emerge:
Three System Challenges
Challenge 1: Heterogeneous Agent ↔ RL Framework Integration. Different teams use LangGraph, AutoGen, custom frameworks. Solution: unified trajectory data interface. Regardless of agent internals, the RL trainer sees clean (state, action, reward) tuples.
Challenge 2: Environment Management at Scale. Key insight: many “tools” are not simple function calls. Shells, browsers, file systems are stateful environments requiring lifecycle management. Three patterns: remote execution service, efficient sandbox infra (Docker/K8s), centralized environment pool.
Challenge 3: Long-Tail Task Efficiency. 63 of 64 rollouts finish in 2 minutes but one takes 20 minutes → 63 GPUs sit idle for 18 minutes waiting for the straggler. At current GPU rates, that’s tens of dollars wasted per batch, and it happens every batch. Three solutions have emerged: async/decoupled architecture (rollout engine feeds trajectories to the training engine asynchronously, so no one waits), partial rollout (checkpoint long episodes, save state, resume in the next training iteration, as in Kimi-Researcher), and dynamic load balancing (predict action execution time, assign tasks to workers with compatible resources).
The paradigm shift:
Traditional: prompt → response → reward
Agentic RL: task → remote agent execution → trajectory capture → replay pool → trainer update2026 Industrial Solutions
ProRL Agent (NVIDIA): Rollout-as-a-Service via HTTP. The key idea: any RL trainer (NeMo, veRL, custom) sends a task description via HTTP to the ProRL Agent service, which spawns a sandboxed environment, runs the agent inside it, captures the full trajectory, and returns it. The trainer never touches the environment directly. This decoupling means rollout infrastructure and training infrastructure can scale independently. ProRL Agent uses rootless sandboxing (no root privileges needed), making it deployable on shared HPC clusters.
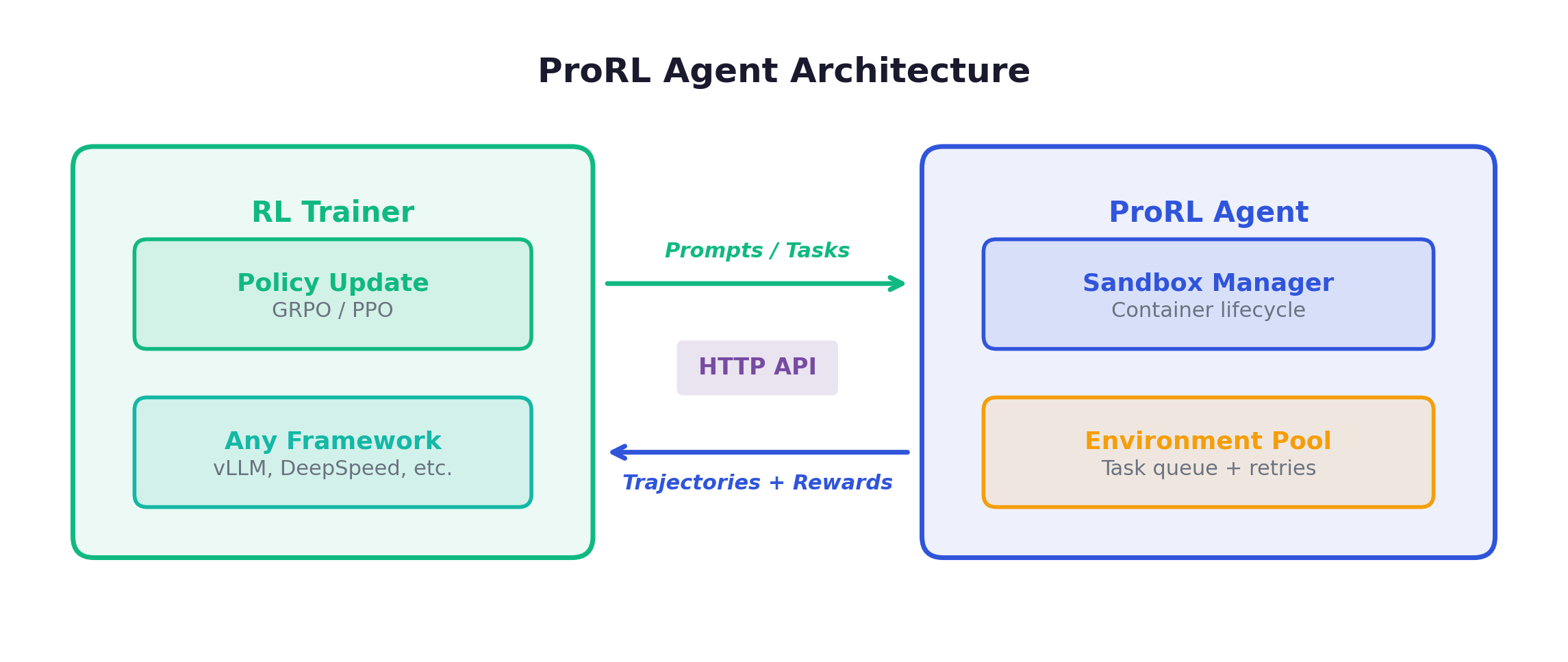
RollArt: Hardware affinity mapping + trajectory-level asynchrony + statefulness-aware compute. 3,000+ GPU deployment, 1.35-2.05x speedup.
ARL-Tangram: Action-level resource scheduling. Predicts action execution time, assigns to workers with compatible resources. 4.3x speedup.
| Year | State of Agentic RL Infra |
|---|---|
| 2024 | Research prototypes. Single-machine. |
| 2025 | Early frameworks (Slime, veRL). Docker orchestration. |
| 2026 | Industrial deployment. Rollout-as-a-Service. 3,000+ GPU clusters. |
AEnvironment: Everything as Environment
“Everything is an environment”: benchmarks, tool sets, other agents. The infrastructure vision is Environment-as-a-Service (EaaS): register environments in a standardized hub (analogous to Docker Hub for containers), deploy them as services with a unified API, compose them into training curricula, and train agents at scale. Each environment exposes a standard interface (reset, step, evaluate), regardless of whether it’s a coding sandbox, a web browser, or a multi-agent negotiation arena. The goal is an “operating system for environments” where building a new training curriculum is as easy as pulling containers from a registry.
7. Environment Synthesis
The finding from the previous chapters that stuck with me most: environment variety matters more than data volume. But building one quality environment costs weeks of engineering. We clearly need more, and we clearly can’t afford to build them all by hand. This chapter covers the methods that make automated synthesis viable.
Three Technical Routes
| Route | Input | Output | Realism | Scalability |
|---|---|---|---|---|
| Tool-first | Existing APIs | Programmatic envs | High | Medium |
| Domain-first | Domain seeds | Complete envs (DB+tools+tasks) | Medium-High | High |
| Model-based | Tool descriptions | Simulated responses (1.5B model) | Medium | Highest |
EnvScaler: SkelBuilder + ScenGenerator
Two-stage pipeline. SkelBuilder constructs environment skeletons (state, rules, tools, code) and runs them through a dual-agent quality loop: a Testing Agent sends tool requests to the environment, and a Checking Agent verifies the results are correct. This iterates until the pass rate meets a threshold. It’s not just “does the code run” but “are the results semantically correct.” ScenGenerator then populates scenarios with DB states, tasks, and rule-based verification. Result: 191 environments, 7K scenarios.
AWM: 1,000 Environments from 100 Seeds
The most ambitious synthesis effort to date. The pipeline starts with 100 domain seed names (hotel booking, healthcare, e-commerce, etc.) and expands them through five stages: (1) LLM expands each seed into diverse scenarios, filtered to keep only CRUD-capable ones, (2) embedding-based deduplication and class balancing produce ~1,000 unique scenarios, (3) for each scenario, the system generates a SQLite schema with realistic sample data (~18.5 tables per environment), (4) Python + FastAPI backends implement ~35 tools per environment exposed via MCP protocol, (5) hybrid verification (DB state diff + LLM judge) validates correctness. The entire pipeline is largely self-correcting: 86.8% of generated environments work on the first try, with an average of only 1.13 fix iterations for the rest.
| Metric | Value |
|---|---|
| DB generation success rate | 88.3% |
| Average tools per environment | 35.1 |
| Average LOC per environment | ~2,000 |
| 8B model score improvement | 53.83 → 65.94 |
Key innovation, History Mismatch Alignment. During RL training, the agent sees the complete interaction history. But during inference, the context window is truncated, so the agent can’t see all past turns. This creates a distribution shift: the model optimizes actions conditioned on full history but must act on truncated history at test time. AWM’s solution: train with the same truncation strategy used at inference. The experimental evidence is stark: without this alignment, performance degrades significantly on long-horizon benchmarks like τ²-Bench where trajectories are longest.
AgentScaler: Read/Write Abstraction
Core insight: any function call is a database read/write operation. Pipeline: 30K+ APIs → tool dependency graph → Louvain community detection → per-domain materialization → two-stage training (cross-domain SFT → domain-specific RL). AgentScaler-30B-A3B matches 1T-parameter models on τ-bench, τ²-Bench.
GTM: 1.5B Model Simulates 20K+ Tools
Train a small model to simulate all tool responses. Fast, cheap, zero API cost, but no real state transitions. Best for learning tool-calling patterns, not precise state management. Think of it as “pretraining” of environment interaction.
2026 Frontier
LOGIGEN: Logic-first paradigm. Triple-agent orchestration ensures every task is provably solvable with deterministic verification. 20K tasks, 79.5% τ²-Bench.
AutoForge: From tool documentation to environments. Introduces ERPO (Environment-level Relative Policy Optimization), computing baselines per environment rather than globally, so the model improves on hard environments rather than only optimizing easy ones.
Choosing the Right Method
| Need | Method | Why |
|---|---|---|
| Highest verification reliability | LOGIGEN | Deterministic, zero unsolvable tasks |
| Highest realism | EnvScaler/ScaleEnv | Complete tool-DB logic |
| Largest scale | AWM | 1,000 envs, proven scaling curve |
| Lowest cost | GTM | No real environments needed |
| Existing tools | AgentScaler | 30K+ API integration |
| From docs only | AutoForge | Swagger → environments |
In practice, these methods are complementary and can be staged: Phase 1 (days): prototype with GTM for fast simulation, validate the training pipeline end-to-end at minimal cost. Phase 2 (weeks): scale with AWM or ScaleEnv, building 500-1,000 diverse environments with real DB logic. Phase 3 (weeks): specialize with AgentScaler’s two-stage training (cross-domain SFT → domain-specific RL) or LOGIGEN for domains requiring airtight verification.
8. Embodied AI
Everything discussed so far assumes text and tool environments: discrete states, deterministic tools, cheap resets. Embodied AI operates under fundamentally different constraints. The real world is continuous, noisy, and doesn’t have a reset button.
What Makes Embodied Different
| Dimension | Text/Tool Envs | Embodied Envs |
|---|---|---|
| State space | Discrete (JSON, DB) | Continuous (poses, joint angles) |
| Action space | Tool calls, text | Continuous control + discrete decisions |
| Physical constraints | None | Gravity, collision, friction |
| Sim-to-real gap | Minimal | Massive |
| Verification | Programmatic | Requires perception |
The Three-Level Hierarchy
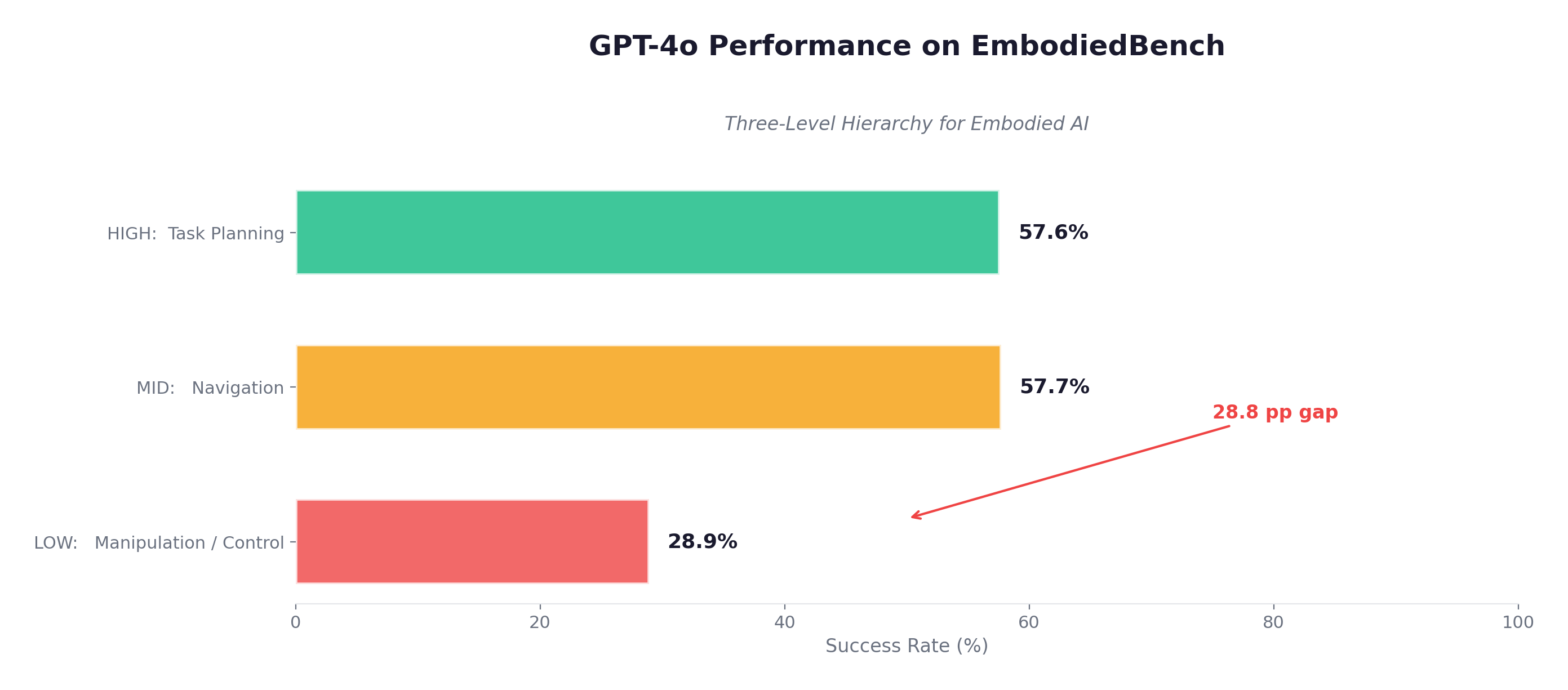
EmbodiedBench (ICML 2025) quantified this gap: GPT-4o scores 56-59% on high-level planning tasks (EB-ALFRED, EB-Habitat), but only 28.9% on low-level manipulation. LLMs can plan but cannot execute continuous control.
Platform Evolution
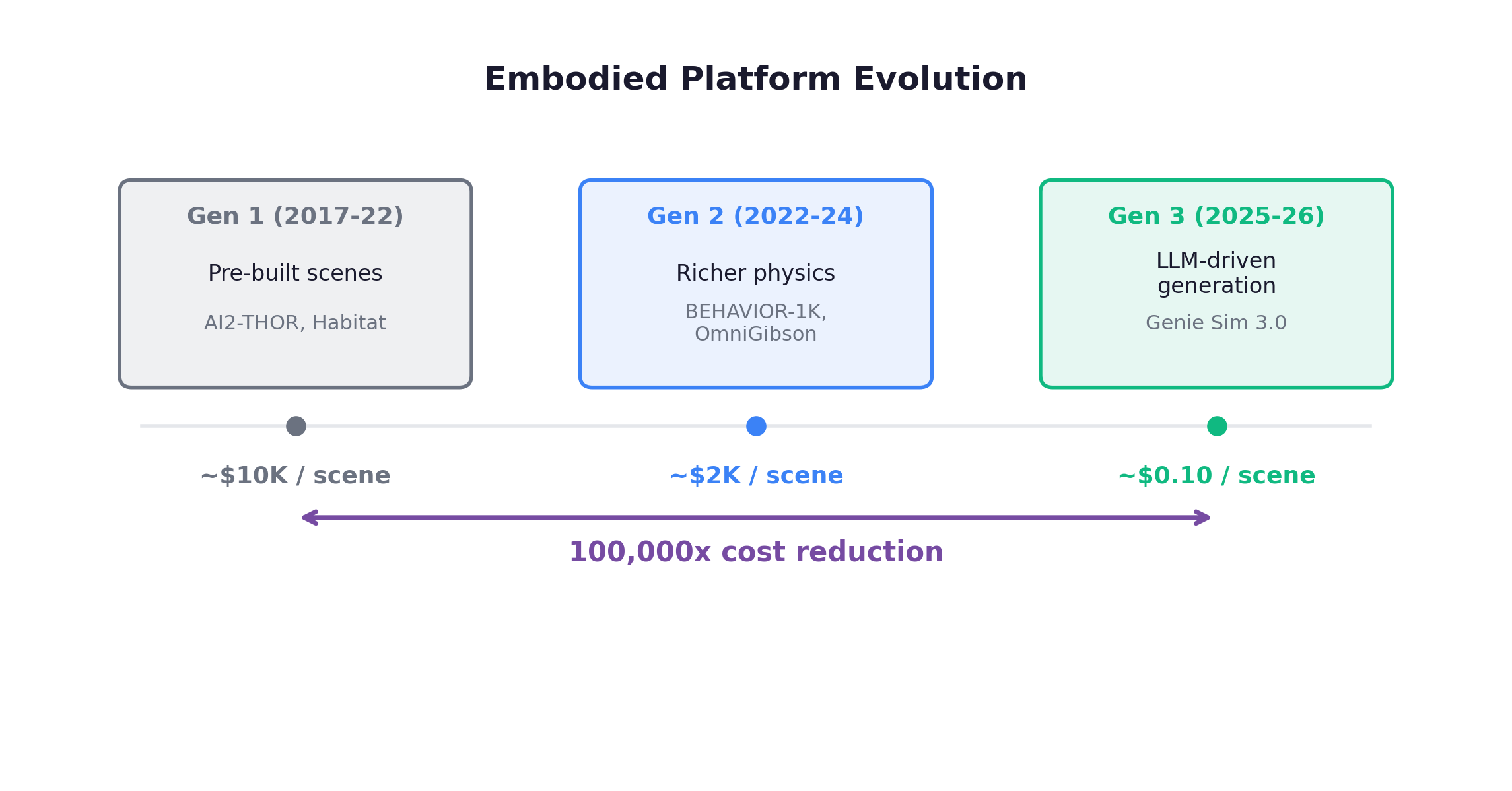
Each generation brought qualitative improvements. Gen 1 platforms like AI2-THOR offered ~120 pre-built rooms with limited scene diversity. Gen 2 platforms pushed interaction fidelity: BEHAVIOR-1K models 1,000 everyday activities across 50 scenes with 5,000+ object categories; OmniGibson adds full physics simulation including fluids, granular materials, and deformables. Gen 3 platforms like Holodeck 2.0 take a text description and generate a fully furnished, physics-enabled 3D room in seconds. The 100,000x cost reduction (from $10K to $0.10 per scene) mirrors what’s happening in text/tool domain synthesis.
World Models as Embodied Environments
Three paradigms of world models have emerged for embodied AI. Video-generative models (GigaWorld-0) take the current frame plus an action and predict the next frame as video, capturing visual realism but losing physics consistency over long horizons. State-predictive models (RWML) predict latent state vectors rather than pixels, which is more compact but less interpretable. LLM semantic models (Simia, ALFWorld) represent states as text descriptions and predict state changes in natural language, which is accurate for semantic reasoning but useless for continuous control.
WoVR breakthrough: LIBERO success rate 39.95% → 69.2%. Real robot 61.7% → 91.7%. A 30-point improvement on real robots by training in a learned world model. WoVR’s key contribution is explicitly handling imperfect world models rather than assuming simulation fidelity. This challenges the assumption that hand-crafted physics simulators are always needed. The caveat: WoVR works because it was trained on focused manipulation tasks (tabletop objects), not arbitrary physics. Domain-specific world models outperform general-purpose ones.
World-VLA-Loop creates a mutual improvement cycle: world model generates training data for the policy, policy generates real data that improves the world model. This creates a flywheel where both components improve together.
Key Findings
LogicEnvGen: Logical diversity matters more than visual diversity for training. Constructing decision-tree behavior plans and synthesizing logic trajectories reveals agent deficiencies 4-68% faster than varying visual appearance alone. Structure beats surface.
Affordance-Graphed Task Worlds: Formalize tasks as paths through affordance graphs. Atomic manipulation primitives → combinatorial task generation with automatic VLM+geometry verification.
SafeAgentBench (2025) exposed a critical gap: across 750 tasks spanning 10 hazard types, the best baseline achieves only a 10% refusal rate on unsafe commands. That should be 100%. Embodied agents’ safety understanding remains severely lacking.
9. Multi-Agent
In multi-agent systems, the environment takes on a qualitatively different character: every agent’s behavior is part of every other agent’s environment. The environment doesn’t just change between episodes. It learns alongside the agent, because it is made of other learning agents.
Why Multi-Agent is the Ultimate Scaling Challenge
- State space explosion: N agents → S^N joint state space
- Credit assignment: Team succeeds. Who deserves credit?
- Non-stationarity: Other agents are learning simultaneously, making the environment a moving target
- Communication overhead: N agents, O(N²) potential message pairs
Communication Mechanisms
| Mechanism | Scalability | Realism |
|---|---|---|
| Sync broadcast | O(N²) — poor | Low |
| Point-to-point | O(N) — good | Medium |
| Async queues (MQTT) | O(N) — good | High |
| Environment-mediated | O(1) per agent | Highest |
The Multi-Agent RL Explosion (2025-2026)
Standard GRPO fails in multi-agent settings for a subtle reason: it computes advantages by comparing completions for the same prompt, but in multi-agent scenarios, different agents receive different prompts (their own observation of the shared state). You can’t meaningfully compare Agent A’s response to Agent B’s prompt. AT-GRPO (Agent-Turn-wise GRPO) solves this by computing advantages per agent and per turn: within each turn, it groups completions from the same agent facing the same observation, normalizes within that group, and aggregates across turns. This directly addresses credit assignment. Alternatives include MAGRPO (centralized critic that observes all agents) and CoLLM (cooperation rewards for collaborative tasks), but AT-GRPO’s results are the most striking:
| Benchmark | Single-Agent GRPO | AT-GRPO |
|---|---|---|
| Multi-agent negotiation | 14% | 96% |
| Collaborative coding | 23% | 97.5% |
Self-Play as Environment. No external environment needed. Agents generate challenges for each other. MAE uses a three-role system: a Proposer generates tasks, a Solver attempts them, and a Judge evaluates the results. All three co-evolve, with each role’s improvement driving the others. SAGE extends this to four co-evolving agents (task generator, solver, critic, meta-controller) on Qwen-2.5-7B, achieving +8.9% LiveCodeBench with zero external data. The multi-agent system itself becomes the environment.
Games as Training Environments. The MARS result that stunned me:
| Training on games | Transfer Result |
|---|---|
| Self-play on diverse games | +28.7% unseen games |
| Transfer to AIME (math) | +10.0% |
| Transfer to GPQA (science QA) | +12.5% |
Training on games transfers to math and science reasoning. This is perhaps the most surprising finding in multi-agent research. Why would playing Werewolf improve math performance? The hypothesis: multi-agent games force agents to develop theory of mind (modeling what others know), strategic planning (reasoning several moves ahead), hypothesis testing (evaluating evidence under uncertainty), and counterfactual reasoning (what would have happened if…). These are general cognitive skills, not game-specific ones, and they transfer because the same reasoning patterns appear in mathematical proofs and scientific analysis.
Social simulations have reached remarkable scale: OASIS runs 1 million LLM-driven agents simultaneously. At this scale, macro-level phenomena emerge that no individual agent was programmed to produce: information cascades (one viral post triggers waves of resharing), opinion polarization (agents cluster into echo chambers), herd effects in markets, and social stratification. These mirror patterns observed in real social data, suggesting that multi-agent LLM simulations can serve as testbeds for studying collective behavior.
Sotopia-RL tackles social intelligence training. The problem: episode-level rewards (“did the negotiation succeed?”) are too sparse for learning nuanced social skills. Sotopia-RL trains an utterance-level reward model from full-dialogue evaluations, then distills it to a real-time reward signal. The agent receives feedback on each conversational turn, not just at the end. This achieves SOTA on social goal completion tasks.
Open Problems
The biggest gap: multi-agent environment auto-generation. We have sophisticated methods for single-agent tasks but generating multi-agent scenarios with appropriate roles, dynamics, and evaluation criteria remains manual. Safety is also critical: competitive environments naturally incentivize deception, and deceptive capabilities might transfer to non-game contexts.
10. Future Directions
After surveying the landscape across nine chapters, I want to close with the directions I find most promising and the open problems that remain unsolved.
Direction 1: Embedded External Tools
Embed compilers, formal verifiers, domain simulators directly into the training loop. LLM + tool hybrid evaluation is strictly more powerful: the compiler catches syntax errors exactly while the LLM assesses semantic quality.
Direction 2: Generator-Verifier Co-Evolution
Strong generators decompose hard tasks into verifiable sub-problems. Strong verifiers provide feedback that improves generators. Tool-R0 demonstrates this. The open question: preventing mode collapse where both stop improving.
Direction 3: Strategy-Space Exploration
SGE (Apple): Instead of exploring individual actions, explore in strategy space, i.e., high-level approaches to problems. The strategy space is orders of magnitude smaller than the action space, making exploration tractable.
Direction 4: World Model Renaissance
WebWorld (1M+ web trajectories, +9.2% WebArena) proves that domain-specialized world models trained on massive data can rival programmatic environments. As a world model for lookahead search, WebWorld outperforms GPT-5 on MiniWob, which is remarkable for a domain-specialized model. World models expand the frontier of what’s trainable.
Direction 5: Automated Reward Discovery
RLAR (agent-synthesized rewards from internet search) and RewardFlow (topology-based propagation) may finally solve “reward design is too expensive for every task type.” The domain of what’s trainable via RL expands dramatically.
Direction 6: Skill Libraries
SkillRL/ARISE: Agents auto-discover, abstract, and manage reusable skill libraries. The process has three stages: skill discovery identifies recurring sub-trajectories that consistently lead to positive outcomes; skill abstraction parameterizes these trajectories so they generalize across contexts (e.g., “search for X” becomes a reusable skill regardless of what X is); hierarchical scheduling uses a high-level policy to select which skill to invoke, while the skill handles low-level execution. A 7B model with a learned skill library beats GPT-4o by 41% on complex multi-step tasks in ALFWorld. Skills are a form of environment scaling: each skill encapsulates knowledge about a class of environment interactions, and the library compounds capability across training runs.
Open Problems
- Environment Quality Metrics. No cheap proxy for “is Environment A better than B for training?”
- Environment Scaling Laws. Is there a Chinchilla law for environments?
- Cross-Modal Environments. Text + vision + audio + physical interaction, integrated at training time.
- Safety. Automated reward discovery might produce exploitable functions. Competitive training might teach deception.
- Sim-to-Real. The embodied domain’s fundamental bottleneck.
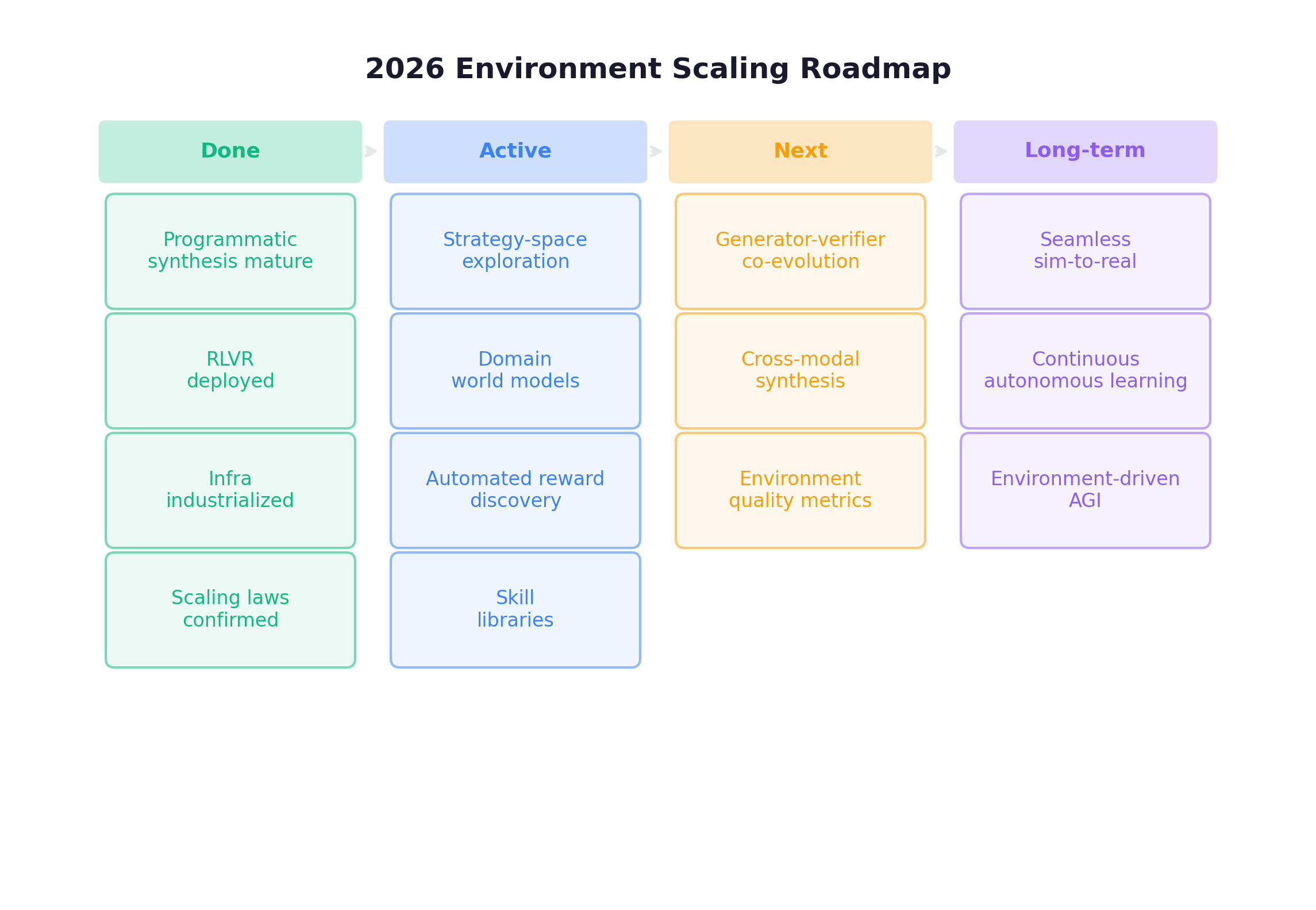
Roadmap (2026 Update)
Closing
I started this post with a claim: the environment is no longer a passive container, but a data engine. After reading through the landscape across ten chapters, I’m more convinced than when I started. A few things stood out to me:
- Programmatic environments can generate millions of verified training tasks at near-zero marginal cost.
- Adaptive curricula automatically match task difficulty to the agent’s current ability.
- World models are starting to cover domains where hand-built simulators aren’t practical.
- Multi-agent self-play produces reasoning skills that transfer to math and science, without any external environment.
- Skill libraries let agents accumulate and reuse learned behaviors across training runs.
If the Chinchilla era taught us that data quality matters as much as model size, I think the post-Chinchilla lesson is that for agentic AI, the environment is the data. Scale the environment, and the data scales with it.
I hope this survey has been useful in clarifying the landscape.