
GitHub: github.com/Guanghan/arc-witness-envs | Demo: HuggingFace Space
You wake up. You don’t remember how you got here, but you’re standing on an island bathed in golden light, facing a stone panel with a single circle and a single line. No instructions. No tutorial pop-up. No voice telling you what to do. You press the circle, drag your finger along the line, and the panel clicks open. A gate swings wide. You step through — and the island unfolds before you, an open world of 523 puzzles, each one a silent question waiting to be understood. At some point you stop solving puzzles and start seeing patterns everywhere: in the branches of trees, in the shadows on the ground, in the power lines overhead. The game didn’t teach you rules. It taught you how to see. And now I can’t help wondering: is that what general intelligence actually is — not knowledge, but the capacity to perceive structure where none was announced?
Ten years ago, in 2016, I wrote about a game that changed how I think about intelligence. The game was The Witness, designed by Jonathan Blow — a puzzle game with 523+ puzzles and zero text instructions. No dialogue, no cutscenes explaining mechanics, no hint system. Just you and an island full of panels, each one a maze where you draw a line from a starting circle to an ending cap while satisfying constraints imposed by colored symbols. The game teaches you its rules the way reality teaches a child physics: through interaction, failure, and the gradual accumulation of hypotheses that either survive contact with the next puzzle or don’t.
I didn’t fully understand at the time why the game haunted me. I wrote about the puzzle mechanics, the visual design, the way each region of the island introduced a new symbol type and then combined it with everything you’d already learned. But the deeper thing — the thing I couldn’t quite articulate in 2016 — was that The Witness is a near-perfect operationalization of fluid intelligence. Not crystallized knowledge (facts, procedures, memorized solutions), but the raw ability to perceive novel patterns and reason about them in real time. The game measures exactly one thing: can you figure out rules you’ve never been told, from examples alone?
That question resurfaced this year, in a very different context.
On March 25th 2026, later this month, the ARC Prize Foundation is about to announce ARC-AGI-3 — the third iteration of François Chollet’s Abstraction and Reasoning Corpus, and the first to be interactive. Previous ARC benchmarks gave models a few input-output grid pairs and asked them to predict the output for a new input. ARC-AGI-3 changes the game: agents interact with an environment, submit candidate answers, receive feedback, and iterate. It’s no longer a static prediction task. It’s a conversation with a puzzle — hypothesis, test, revise, repeat. The format is strikingly reminiscent of how The Witness teaches: through cycles of attempt and feedback, not through instruction.
That parallel is not a coincidence. It’s the foundation of this project.
Today I’m releasing arc-witness-envs — 13 interactive puzzle games with 1,872 levels, inspired by The Witness, compatible with the official ARC-AGI-3 SDK, and RL-ready via OpenEnv. An open-source training ground for teaching machines fluid intelligence.
This post walks through the full story: The Witness and its design philosophy (Chapter 1), the theory of fluid intelligence that connects it to ARC (Chapter 2), the ARC-AGI-3 interactive benchmark (Chapter 3), the 13 games in detail (Chapter 4), the system architecture (Chapter 5), RL training integration (Chapter 6), and personal reflections on ten years of witnessing (Chapter 7).
Let’s start where it started for me: on an island, facing a panel, with no instructions.
1. The Witness: 523 Puzzles, Zero Words
Every puzzle in The Witness asks the same question: draw a line from start to end. The depth isn’t in the question — it’s in the constraints that make most lines wrong, and the fact that nobody ever tells you what those constraints are.
The One Mechanic
The Witness (2016), designed by Jonathan Blow, is built on a single interaction primitive. Every puzzle in the game — all 523+ of them — is a panel containing a grid. The grid has a starting circle and one or more ending caps (small rounded notches at the edge). You draw a continuous path from the circle to a cap, tracing along the grid lines. If your path satisfies all the constraints imposed by the symbols on the panel, it clicks open. If it doesn’t, the panel flashes and resets.
That’s it. One mechanic, 523 variations.
There are no text instructions anywhere in the game. No tutorial pop-ups, no NPC dialogue, no loading screen tips. You are placed on an island and left to figure out everything — every symbol, every rule, every interaction between rules — through experimentation alone. The game communicates exclusively through the language of puzzles: “here is a panel you can solve, and here is one you can’t yet. The difference between them is the lesson.”
The island is open-world, divided into roughly 11 regions, each anchored around a different symbol type. You can wander freely, but natural gating ensures you encounter simpler panels before harder ones within each region. The progression within a region follows a strict pedagogical arc: first, a trivially simple puzzle that isolates a new symbol; then a sequence of puzzles that gradually increase the number of constraints, the grid size, and the interactions with previously learned symbols; finally, a set of “exam” puzzles that test mastery of the full rule set. The entire island is a curriculum, and the player is both the student and the scientist.
The 10 Symbol Types
The game’s constraint vocabulary consists of 10 symbol types, each with a precise semantic rule:
| # | Symbol | Visual | Constraint Rule | Teaching Region |
|---|---|---|---|---|
| 1 | Hexagonal Dots | Small hexagons on grid edges or vertices | Path must pass through every dot on the panel | Entry Area |
| 2 | Colored Squares | Filled squares inside grid cells | All squares of the same color must end up in the same region | Tutorial Houses |
| 3 | Stars (Suns) | Six-pointed stars in grid cells | Each star must be paired with exactly one other same-colored element in its region | Treehouse |
| 4 | Polyominoes | Tetromino-like shapes in grid cells | The shapes in a region must exactly tile that region | Swamp / Marsh |
| 5 | Triangles | Small triangles (1-3) in grid cells | Path must touch exactly N edges of the cell, where N = triangle count | Scattered Panels |
| 6 | Erasers | Y-shaped symbols in grid cells | Each eraser absorbs exactly one constraint violation in its region | Quarry |
| 7 | Breakpoints | Marks on grid edges | Path cannot cross a broken edge | Various |
| 8 | Symmetry | Two starting circles, mirrored paths | Two lines drawn in mirror symmetry; both must reach valid endpoints | Symmetry Island |
| 9 | Cylinder Topology | Panel wraps around a 3D cylinder | Left and right edges are connected — path and regions wrap | Mountain Interior |
| 10 | Color Perception | Colored glass filters over panels | Filters change perceived color of symbols; solve based on filtered colors | Greenhouse / Bunker |
One thing that struck me when I catalogued these: the 10 types are not 10 independent rules. They form a layered system with deep interactions. Colored squares and stars both create region constraints but resolve differently (squares demand same-color grouping; stars demand same-color pairing). Polyominoes constrain region shape, not just region membership. Erasers are meta-constraints that modify other constraints. And color perception doesn’t add a constraint at all — it modifies your observation of existing constraints, which is a fundamentally different kind of challenge.
The Teaching Philosophy
Jonathan Blow’s approach is deliberately anti-conventional — what he’s called the “anti-Nintendo” philosophy of puzzle design. Traditional game design front-loads instruction: a character tells you the controls, a sign explains the mechanic, a gentle tutorial eases you in. Blow rejects all of this.
His principles:
Non-verbal communication. The game never uses words, not because words are bad, but because words create a different kind of understanding. Being told a rule and discovering a rule produce different cognitive structures. When you discover a constraint through a sequence of three puzzles — one where any path works, one where a path separating same-colored squares fails, and one where grouping them succeeds — you build a spatial, intuitive model of the constraint. Blow is betting that the discovered model is more generalizable.
Front-load failure. Most puzzle games are designed so the player succeeds early and often. The Witness deliberately places you in situations where you’ll fail — sometimes many times in a row — before you understand why. The failure is the teaching. Each wrong answer provides information: “my current hypothesis about this symbol is wrong, because this path should have worked under my theory but didn’t.”
Hypothesis modification, not accumulation. In most games, learning is additive: you learn rule A, then rule B, then rule C. The Witness deliberately sets up situations where your understanding of a symbol changes as you encounter it in new contexts. Your initial model of hexagonal dots might be “the path must pass through dots.” Then you encounter dots on vertices (not edges), and your model must accommodate that. Then you encounter dots combined with colored squares, and you realize dots constrain the path while squares constrain the regions — two orthogonal axes of constraint. The learning isn’t just “more rules.” It’s “better models of the same rules.”
Miniature epiphanies. Blow has described the core player experience as the “epiphany moment” — the instant when a new constraint clicks and a previously impossible panel suddenly becomes solvable. He structures each region to deliver 3-5 of these moments, each one building on the last. The emotional arc: confusion → frustration → hypothesis → test → more frustration → revised hypothesis → epiphany → flow → mastery.
I think Blow accidentally (or perhaps deliberately) created one of the best training curricula for fluid intelligence ever designed. The parallel to how we’d want to train an RL agent is almost too clean: present tasks of escalating difficulty, provide only outcome feedback (success/fail), force the agent to build internal models of latent rules, and test generalization by composing rules in novel combinations.
The 6-Layer Constraint Model
As I was designing arc-witness-envs, I needed a formal framework for understanding how The Witness’s constraints compose. I settled on a 6-layer model that captures the qualitative jumps in difficulty:
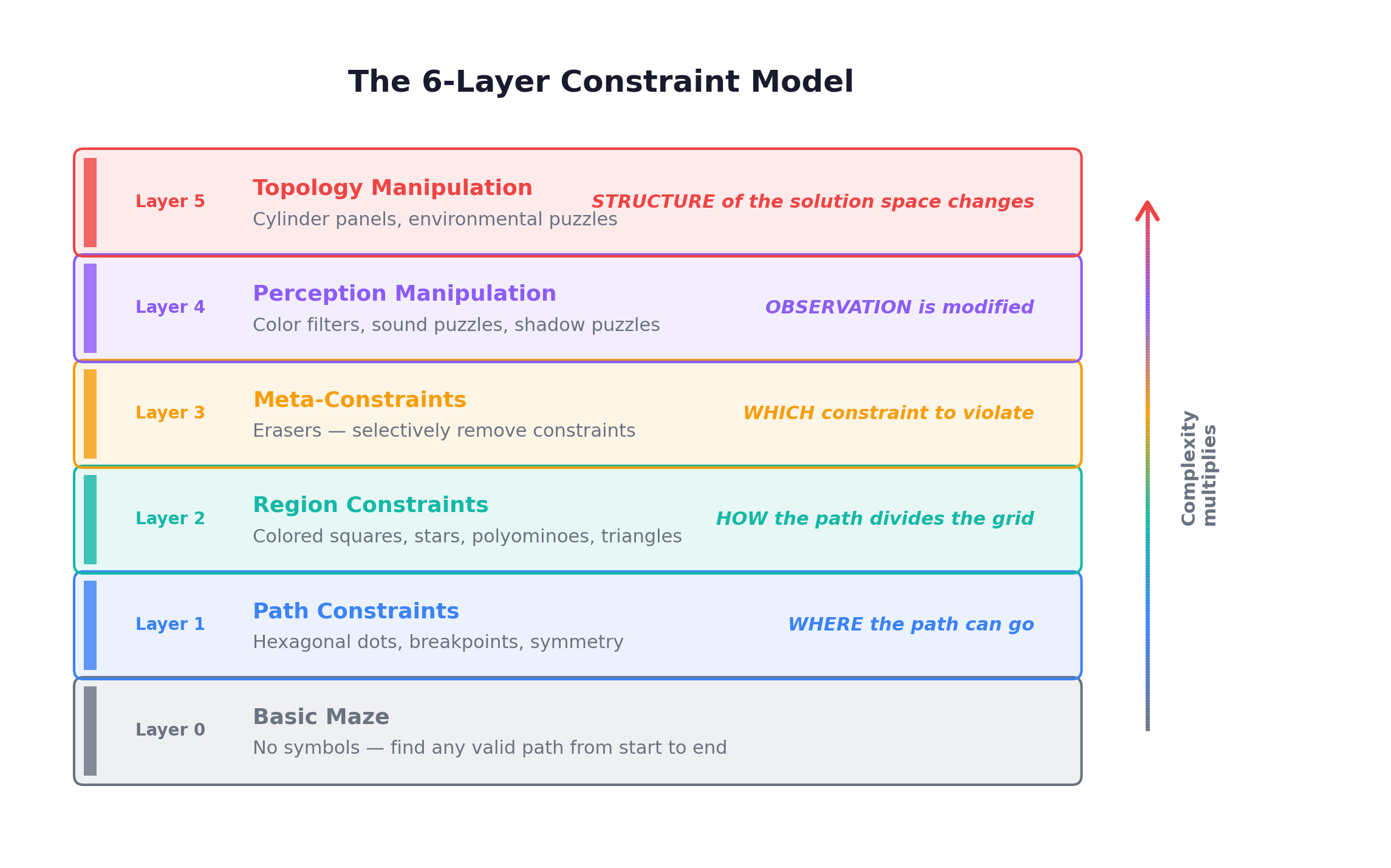
The key insight: layers compose multiplicatively, not additively. A puzzle with colored squares (Layer 2) is manageable. Add hexagonal dots (Layer 1 + 2) and the path must simultaneously visit specific vertices AND create valid regions. Add an eraser (Layer 3) and the solver must decide which constraint type to violate. Put it behind a color filter (Layer 4) and the solver must first figure out the actual colors. Wrap it on a cylinder (Layer 5) and the region topology itself becomes non-obvious.
Computational Complexity: From NP to Beyond
In 2018, Zachary Abel, Erik Demaine, Jayson Lynch, and collaborators published “Who witnesses The Witness? Finding witnesses in The Witness is hard and sometimes impossible”, analyzing the computational complexity of The Witness’s puzzle types. Their results are striking.
For most individual symbol types, the decision problem (“does a valid path exist?”) is NP-complete:
- Colored squares alone: NP-complete
- Stars alone: NP-complete
- Polyominoes alone: NP-complete
- Triangles alone: NP-complete
- Hexagonal dots alone: NP-complete (related to Hamiltonian path)
But the really remarkable result concerns erasers. Erasers push the complexity to Σ₂-complete — strictly harder than NP. Here’s the intuition: in a standard NP problem, you can verify a proposed solution in polynomial time. But with erasers, verifying a proposed solution requires solving an optimization problem: for each eraser, you must determine which constraint violation it optimally absorbs, and this optimization itself can be NP-hard. So you have an NP-hard problem nested inside the verification step of another NP problem — that’s Σ₂.
In plain terms: for puzzles with erasers, even if someone hands you a solution and claims it’s correct, checking whether they’re right is itself a hard problem.
This result is deeply relevant to the AGI discussion. The Witness achieves exactly what a good intelligence test should: its puzzle types occupy complexity classes that guarantee no lookup table, no memorized procedure, and no polynomial shortcut will suffice. An agent that can solve arbitrary Witness puzzles must be doing something that looks like genuine search and inference.
The Secret Ending: Waking Up
Everything I’ve described so far — the 523 puzzles, the 11 regions, the mountain — constitutes the “normal” game. But The Witness has a second ending, hidden behind a series of obscure triggers, and it’s the part of the game that has stayed with me for a decade.
After completing a specific sequence of environmental puzzles (puzzles hidden in the landscape itself — traces of light, shadows cast by trees, gaps in architecture that form path shapes when viewed from the right angle), the player gains access to a hidden elevator. It descends into a dark theater. A screen flickers on.
What follows is a full-motion video (FMV) sequence — live-action footage, not rendered graphics. A person wakes up. They are lying on a couch in what looks like a research lab, wearing something resembling a VR headset. They remove the headset. They stand up. They walk through the office, dazed, blinking. They step outside into the real world.
And then the extraordinary thing happens. The person begins seeing puzzle patterns in the real world. The circular drain cover looks like a starting circle. The power lines against the sky trace a path. The branches of a tree form a maze. The cracks in a sidewalk suggest breakpoints. Everywhere they look, the visual vocabulary of The Witness’s puzzles is superimposed on reality.
This ending is doing something philosophically profound. The entire island — the puzzles, the regions, the mountain — was a training environment. A simulation. The character was an agent placed in a controlled world designed to teach one thing: pattern perception. Not any specific pattern. The meta-skill: the ability to perceive structure in novel stimuli. To look at something you’ve never seen before and ask, “what are the constraints here? What’s the rule?”
And the FMV sequence — waking up, removing the headset, seeing puzzles in the real world — is the test of whether the training generalized.
I suspect the character who wakes up is an agent who passed the simulation’s test of general intelligence and earned the right to enter the real world. The island was the benchmark. The FMV is what happens after you pass — you graduate from the training environment into the deployment environment, carrying with you the perceptual machinery the training built.
If that reading is correct, then The Witness is a game about the relationship between training and generalization, between simulation and reality, between fluid intelligence and the world it operates on. It’s a game about exactly the problem ARC-AGI is trying to measure — and the problem arc-witness-envs is trying to help solve.
2. Fluid Intelligence: What ARC Actually Measures
LLMs are crystallized intelligence engines. They can recall and recombine, but can they truly reason about the unseen?
Before diving into any code or environment design, I want to spend time on the intellectual foundation that makes ARC — and by extension, arc-witness-envs — worth caring about. The foundation is a single paper: François Chollet’s “On the Measure of Intelligence” (2019). It changed how I think about what we’re actually building when we build AI systems, and it’s the reason ARC exists at all.
Chollet’s central argument is deceptively simple: we have been measuring the wrong thing. Most AI benchmarks measure skill — performance on a specific task after extensive training on that task or similar ones. GPT-4 scoring 90% on the bar exam doesn’t tell us the model is intelligent; it tells us the model has absorbed a vast corpus of legal reasoning patterns. Chollet wanted a benchmark that measures the ability to adapt, to generalize, to reason about genuinely novel situations.
Crystallized vs. Fluid Intelligence
In the Cattell-Horn-Carroll (CHC) model of human intelligence, two factors dominate:
-
Crystallized intelligence (Gc): The accumulation of knowledge, skills, and strategies learned through experience. Vocabulary, factual recall, domain expertise, procedural fluency. Gc grows throughout a lifetime.
-
Fluid intelligence (Gf): The capacity to reason in novel situations, independent of acquired knowledge. Pattern recognition in unfamiliar domains, abstract reasoning, the ability to see structure where you’ve never seen structure before. Gf peaks in early adulthood and is largely independent of education.
The distinction maps almost perfectly onto the current state of AI:
| Dimension | Crystallized Intelligence (Gc) | Fluid Intelligence (Gf) |
|---|---|---|
| What it is | Accumulated knowledge, memorized patterns | Reasoning in novel situations |
| How it grows | Through exposure and repetition | Largely innate capacity |
| LLM performance | Exceptional — this is what pre-training optimizes | Unclear — this is what ARC tests |
| Benchmark examples | MMLU, HumanEval, bar exam, medical QA | ARC-AGI, Raven’s Progressive Matrices |
| Can it be gamed by scale? | Yes — more data, more parameters, more Gc | In principle, no |
Large language models are, almost by construction, crystallized intelligence engines. Pre-training on trillions of tokens is the computational analog of a lifetime of reading — it produces extraordinary Gc. But when you show a model a puzzle it has never encountered — a novel spatial transformation, an unfamiliar counting rule, a pattern that doesn’t match any template in its training data — what happens? That’s the question Chollet designed ARC to answer.
Core Knowledge Priors
Chollet grounded ARC in developmental psychology — specifically, in the “Core Knowledge” systems that cognitive scientists like Elizabeth Spelke have identified as innate to human cognition. These are the conceptual primitives that human infants demonstrate before any formal education:
1. Objectness — Objects persist, have boundaries, and can be counted. Infants as young as 3–4 months show evidence of object permanence. In ARC, this manifests as puzzles where you must identify discrete objects, track them through transformations, and preserve their identity.
2. Numbers and Counting — Small quantities can be distinguished, ordered, and manipulated. Infants distinguish sets of 1, 2, and 3 items before they can speak.
3. Geometry and Topology — Spatial relationships matter. Symmetry, containment, adjacency, rotation, scaling — these are concepts humans reason about effortlessly because spatial cognition is deeply wired.
4. Agentness — Some entities behave in goal-directed ways. Even infants attribute intentionality to moving dots on a screen if those dots appear to be “trying” to reach a destination.
The brilliance of this design is that it creates a level playing field. Any system — human, AI, or alien — that possesses these Core Knowledge priors should be able to attempt ARC puzzles. The test doesn’t require knowing English, or calculus, or Roman history. It requires the ability to reason from a minimal set of universal primitives.
The Witness as a Fluid Intelligence Test
This is where the connection becomes precise. Each symbol type in The Witness maps onto one or more of Chollet’s Core Knowledge systems:
| Core Knowledge | Witness Symbol | Game IDs | What It Tests |
|---|---|---|---|
| Objectness | Hexagonal Dots | tw01 | Preserving specific elements — path must visit designated points |
| Objectness + Numbers | Colored Squares | tw02 | Classifying objects by attribute — separate regions by color |
| Numbers | Stars | tw05 | Counting and pairing — each color exactly twice per region |
| Geometry | Polyominoes | tw03 | Spatial composition — shapes must tile regions |
| Numbers | Triangles | tw06 | Local counting — edge count matches triangle count |
| Geometry | Symmetry Lines | tw04 | Geometric transforms — mirrored path drawing |
| Agentness | Erasers | tw07 | Meta-reasoning — which constraint to sacrifice |
| Topology | Cylinders | tw09 | Non-planar spatial reasoning — wrap-around |
| Perception | Color Filters | tw10 | Transform-then-apply — perceived vs. actual |
| Composition | Multi-constraint | tw08, tw11-tw13 | Integrating multiple Core Knowledge systems |
What I find striking is that this mapping wasn’t forced. I didn’t start with Chollet’s framework and work backward to The Witness. I started by playing The Witness, cataloging the symbol types, and then realizing that Jonathan Blow had, perhaps unknowingly, designed a near-perfect fluid intelligence test. Each symbol type is a minimal rule system that must be discovered through interaction. Each level adds a new wrinkle that prevents rote memorization.
Rules as Global Memory
Here’s where the game design insight intersects with the RL training insight.
When you play The Witness, each eureka moment — each rule you discover — is stored in a kind of global memory. Not in the game’s save file. Not in your character’s stats. In your own mind. This is the real growth. After beating the game, your character hasn’t leveled up. No +10 attack, no legendary armor. All the growth is in your understanding of the rules you’ve discovered. As long as you have that understanding, you can solve similar problems more efficiently.
This is an unusual design for a video game. Most games reward you with extrinsic resources — better weapons, more health, unlocked abilities — that make future challenges easier through mechanical advantage. The Witness gives you nothing except knowledge. And that knowledge doesn’t depreciate. If you put the game down for a year and come back, you can still solve hexagonal dot puzzles because you understand the rule. The understanding is the reward.
An agent solving ARC-AGI-3 should work the same way. The rules it discovers during exploration aren’t consumed — they become persistent priors that accelerate future problem-solving. An RL agent that solves tw01 (PathDots) across many levels isn’t just learning to solve specific puzzle configurations. If the training is working correctly, it’s learning the concept of path-must-pass-through-marked-points. That concept should transfer. When the agent encounters tw12 (hex dots combined with region constraints), it shouldn’t need to re-learn hex dots from scratch. It should arrive with that prior already internalized and focus its exploration budget on the new constraint.
This is exactly what arc-witness-envs is designed to train: not memorization of specific puzzle solutions, but the capacity to discover rules through interaction and carry those rules forward as persistent, reusable priors.
3. ARC-AGI-3: The Interactive Reasoning Benchmark
This is the difference between reading about swimming and actually being thrown in the pool.
From Static to Interactive
ARC-AGI has gone through three iterations, each tightening the screws on what counts as intelligence. ARC-AGI-1 and ARC-AGI-2 were static benchmarks: you see a few input-output grid pairs, infer the transformation rule, apply it to a test input. But static benchmarks have a shelf life. Given enough compute, teams found ways to brute-force solutions through program synthesis and massive ensembling.
ARC-AGI-3 changes the game entirely. It’s the first Interactive Reasoning Benchmark (IRB): agents are placed inside an environment and must discover rules through actions, receiving only visual feedback from a 64×64 pixel grid. No instructions. No labels. No static examples to pattern-match against. Just an environment that responds to your actions, and the challenge of figuring out what it wants.
| Dimension | ARC-AGI-1/2 (Static) | ARC-AGI-3 (Interactive) |
|---|---|---|
| Input | 2-5 input→output grid pairs + 1 test input | 64×64 pixel environment |
| Task | Infer transformation rule, apply to test | Discover rules, navigate levels, achieve goals |
| Agent actions | Submit output grid | 8 actions: RESET + 7 game actions |
| Feedback | Correct / incorrect | Visual state change after each action |
| Time horizon | Single step | Multi-step, multi-level episodes |
| What it measures | Pattern recognition + rule inference | Exploration + rule discovery + planning + execution |
The interactive format forces agents to develop a tight observe-hypothesize-test loop. You take an action. You observe what changed. You form a hypothesis about the rule. You take another action to test that hypothesis. If it fails, you revise. This is the scientific method reduced to its smallest possible form.
SDK Architecture
The ARC-AGI-3 SDK has two packages: arc-agi (high-level interface) and arcengine (game engine). Understanding this matters because arc-witness-envs must be fully compatible — same interfaces, same observation format, same action space.
| Class | Package | Role |
|---|---|---|
Arcade | arc-agi | Entry point. Loads environments, manages evaluation |
EnvironmentWrapper | arc-agi | Agent-facing interface: reset() and step(action) |
ARCBaseGame | arcengine | Base class all games inherit from |
Level | arcengine | Manages sprites and game state |
Sprite | arcengine | Visual/physical units within a level |
Camera | arcengine | Renders the 64×64 viewport |
Action space: 8 discrete actions — RESET (0), UP (1), DOWN (2), LEFT (3), RIGHT (4), CONFIRM (5), CLICK (6), RESERVED (7).
Observation: Each observation is a 64×64 grid where each cell is an integer from 0 to 15, indexing into a fixed 16-color palette:
| Index | Color | Hex | Index | Color | Hex |
|---|---|---|---|---|---|
| 0 | White | #FFFFFF | 8 | Red | #F93C31 |
| 1 | Light Gray | #CCCCCC | 9 | Blue | #1E93FF |
| 2 | Gray | #999999 | 10 | Light Blue | #88D8F1 |
| 3 | Dark Gray | #666666 | 11 | Yellow | #FFDC00 |
| 4 | Darker Gray | #333333 | 12 | Orange | #FF851B |
| 5 | Black | #000000 | 13 | Dark Red | #921231 |
| 6 | Pink | #E53AA3 | 14 | Green | #4FCC30 |
| 7 | Light Pink | #FF7BCC | 15 | Purple | #A356D6 |
Sixteen colors. 64×64 pixels. Eight actions. That’s the entire interface. The simplicity is the point — it strips away every crutch that modern AI systems rely on (language understanding, retrieval, chain-of-thought prompting) and asks: can you figure out what’s going on just by looking and doing?
Scoring: Rewarding Efficient Discovery
score = max(0, 1 - actions_taken / baseline_actions)Computed per level, averaged across all levels. The baseline_actions is calibrated per level based on human performance. If you solve in fewer actions than baseline: high score. If you take more: score approaches zero. If you don’t solve: zero.
The scoring formula rewards agents that internalize rules quickly and exploit them efficiently — exactly what fluid intelligence looks like in practice. An agent that truly learns rules — that has aha moments where a rule clicks and subsequent levels become trivial — will score high because it acts efficiently. An agent that relies on random exploration will burn through its action budget and score near zero, even if it eventually stumbles onto the solution.
Why Training Environments Matter
The official competition provides ~150 secret test environments. Teams need training environments that share the same SDK interface, action space, and observation format — but test different specific rules while exercising the same cognitive skills.
arc-witness-envs fills this gap: 13 games × 1,872 levels of progressive, Witness-inspired puzzle training — all drop-in compatible with the ARC-AGI-3 SDK.
from arc_agi import Arcade, OperationMode
arcade = Arcade(
operation_mode=OperationMode.OFFLINE,
environments_dir="path/to/arc-witness-envs/environment_files",
)
# Your agent sees tw01-tw13 exactly like official ARC-AGI-3 games
for env_info in arcade.get_environments():
print(env_info.game_id, env_info.title)No adapter code. No format conversion. The Arcade class loads arc-witness-envs environments exactly as it would load official competition environments.
4. The 13 Games: A Taxonomy of Abstract Reasoning
Jonathan Blow hadn’t just designed a puzzle game. He’d designed a taxonomy of computational reasoning primitives — path planning, region partitioning, exact cover, symmetry simulation, error counting — all expressed through a unified visual grammar.
The Full Catalog
| Game | Mechanic | Levels | Core Knowledge |
|---|---|---|---|
tw01 PathDots | Mandatory waypoints | 16 | Objectness |
tw02 ColorSplit | Region color partition | 62 | Objectness + Numbers |
tw03 ShapeFill | Polyomino exact cover | 248 | Geometry |
tw04 SymDraw | Mirrored line drawing | 26 | Geometry (symmetry) |
tw05 StarPair | Region pair counting | 55 | Numbers |
tw06 TriCount | Edge counting | 144 | Numbers |
tw07 EraserLogic | Error absorption | 502 | Meta-reasoning |
tw08 ComboBasic | Squares + Stars | 108 | Composition |
tw09 CylinderWrap | Horizontal wrap | 5 | Topology |
tw10 ColorFilter | Perception transform | 5 | Perception |
tw11 MultiRegion | 2+ region constraints | 410 | Composition |
tw12 HexCombo | Dots + region rules | 160 | Composition |
tw13 EraserAll | Generalized erasers | 131 | Meta-reasoning |
1,872 levels total. Each one a formally specified constraint-satisfaction problem rendered as a 64×64 pixel environment.
Three Tiers of Complexity
Tier 1 (tw01-tw07): Single-mechanic games. Each teaches exactly one symbol type. A player (or agent) who masters Tier 1 has learned the entire symbolic vocabulary of The Witness.
Tier 2 (tw08-tw10): Advanced mechanics. ComboBasic combines squares and stars. CylinderWrap introduces topological wrapping. ColorFilter transforms perception itself.
Tier 3 (tw11-tw13): Multi-constraint compositions. MultiRegion stacks 2+ constraint types per region. HexCombo combines mandatory hex dot waypoints with region constraints — all present constraints must hold simultaneously (AND logic). EraserAll generalizes eraser logic to absorb violations from squares, stars, triangles, and tetris, while hex dots remain a hard constraint that cannot be erased.
Think of it like learning mathematics. Tier 1 is arithmetic — each operation in isolation. Tier 2 is algebra — combining operations, introducing new abstractions. Tier 3 is proofs — coordinating everything you know at once.
tw01 — PathDots: The Entry Area
If an agent can’t solve PathDots, it can’t solve anything.
The rules: draw a path from start to end that passes through ALL yellow dots. The 16 levels (10 validated, 6 unvalidated) form a clean difficulty ramp from a 3×3 grid with 1 dot to multiple start nodes with breakpoints and 4+ dots.
from arcengine import GameAction, ActionInput
from environment_files.tw01.tw01 import Tw01
game = Tw01(seed=0)
UP, DOWN, LEFT, RIGHT, CONFIRM = (
GameAction.ACTION1, GameAction.ACTION2,
GameAction.ACTION3, GameAction.ACTION4,
GameAction.ACTION5,
)
for action in [RIGHT, RIGHT, UP, LEFT, LEFT, UP, RIGHT, RIGHT, CONFIRM]:
frame = game.perform_action(ActionInput(id=action), raw=True)
print(f"Levels completed: {frame.levels_completed}")Nine actions. The path snakes through the grid collecting every yellow dot, then the agent submits. PathDots is the “Entry Area” of arc-witness-envs — the sanity check, the handshake, the “are you smarter than a Hamiltonian path?“
tw03 — ShapeFill: NP-Complete Tiling
The Swamp of arc-witness-envs — the pedagogical pinnacle of geometric reasoning.
Polyomino pieces must exactly tile the region. 248 levels — the largest single-mechanic game. The underlying problem (exact cover) is NP-complete. Pieces can be fixed orientation, rotatable (drawn tilted), or negative/subtractive.
The solver in our validation pipeline uses DFS with pruning and still times out on many ShapeFill levels. For an agent trained via RL, ShapeFill demands genuine spatial reasoning: can this T-piece fit here if rotated 90 degrees? Does that leave enough room for the L-piece? This is geometric computation, not pattern matching from training data.
tw04 — SymDraw: Dual-State Mental Simulation
Forces the agent to simulate two parallel state machines.
The player controls a blue line; a yellow mirror line moves automatically according to a symmetry rule (horizontal, vertical, or 180° rotational). Both must reach their endpoints simultaneously. Every move has two effects: it extends the blue path AND the mirrored yellow path.
26 levels introduce symmetry types progressively. SymDraw tests simulation — the ability to predict consequences of actions in a system with non-trivial dynamics. A reactive agent can solve PathDots by local heuristics. But SymDraw has no local heuristic. You can’t solve it without simulating the mirror.
tw07 — EraserLogic: Reasoning About Reasoning
This game tests the ability to reason about reasoning itself.
502 levels — the largest game. Eraser symbols absorb constraint violations: #erasers must equal #violations per region. This creates a second-order reasoning problem: to evaluate whether a region is valid, the agent must understand what other constraints require, check which are violated, and verify the count matches the erasers.
The computational complexity is Σ₂-complete — strictly harder than NP. The 502 levels combine erasers with progressively more constraint types: squares, stars, triangles, polyominoes. The Witness itself gives hundreds of eraser puzzles because the concept is so unintuitive. If you want an agent to learn meta-reasoning, you need a lot of training signal.
tw11 — MultiRegion: Where Everything Comes Together
The Town of arc-witness-envs — where every skill is tested at once.
Each region must satisfy 2+ constraint types simultaneously. 410 levels. Constraint combinations span the full vocabulary: squares + triangles, stars + polyominoes, erasers + squares + stars, and more exotic mixes.
The logic is pure AND: ALL present constraints must hold per region. An agent that solves MultiRegion has demonstrated compositional reasoning — the ability to combine independently learned rules into novel configurations.
Dataset Statistics
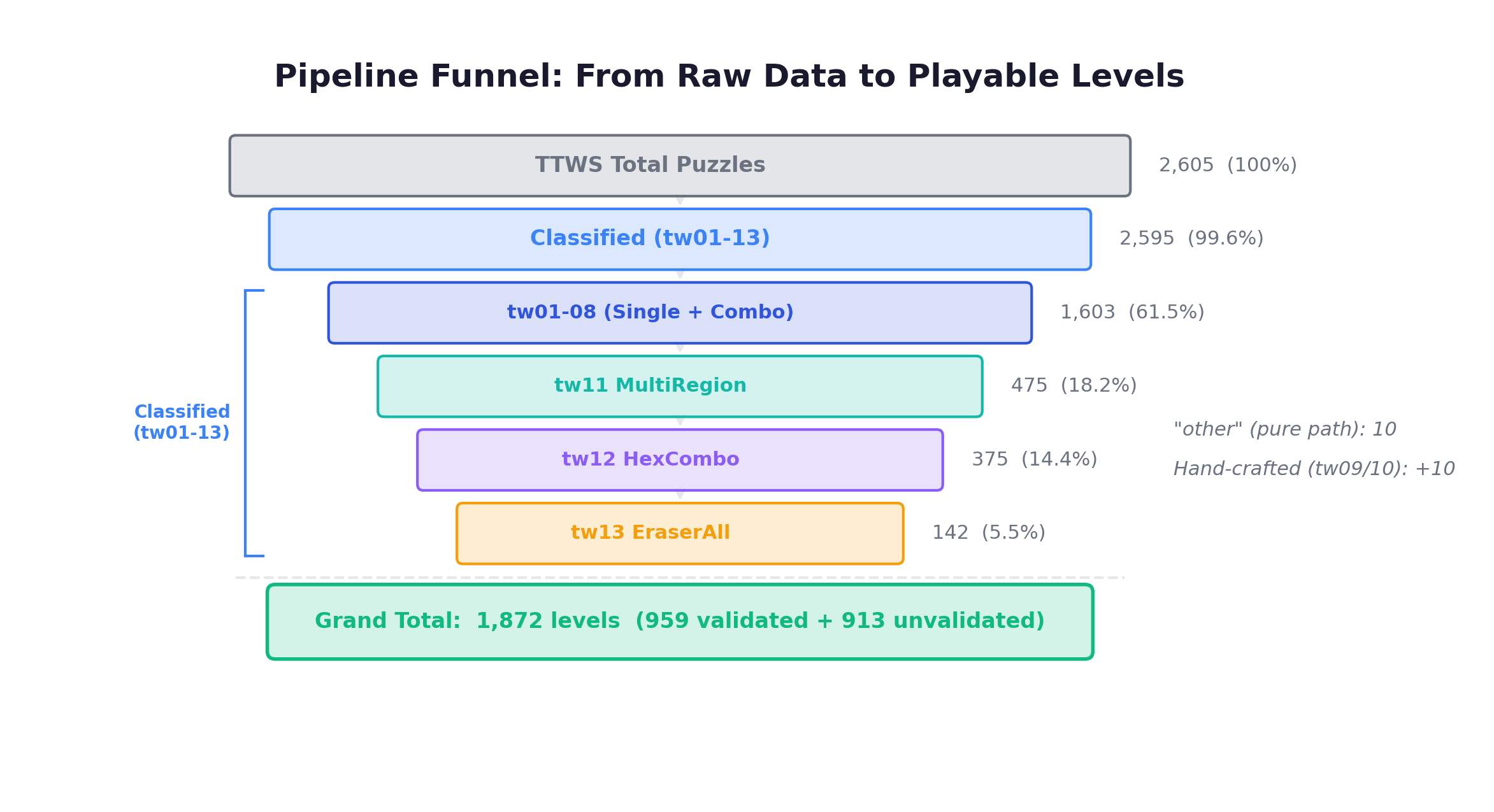
Grand total: 1,872 levels (959 validated + 913 unvalidated)
| Game | Mechanism | Validated | Unvalidated | Total |
|---|---|---|---|---|
| tw01 | PathDots | 10 | 6 | 16 |
| tw02 | ColorSplit | 46 | 16 | 62 |
| tw03 | ShapeFill | 88 | 160 | 248 |
| tw04 | SymDraw | 20 | 6 | 26 |
| tw05 | StarPair | 42 | 13 | 55 |
| tw06 | TriCount | 118 | 26 | 144 |
| tw07 | EraserLogic | 359 | 143 | 502 |
| tw08 | ComboBasic | 56 | 52 | 108 |
| tw09 | CylinderWrap | 5 | 0 | 5 |
| tw10 | ColorFilter | 5 | 0 | 5 |
| tw11 | MultiRegion | 145 | 265 | 410 |
| tw12 | HexCombo | 4 | 156 | 160 |
| tw13 | EraserAll | 61 | 70 | 131 |
| Total | 959 | 913 | 1,872 |
Validated levels have solver-verified solutions with action sequences and baseline scores. Unvalidated levels passed filtering but the solver timed out — these are the NP-hard puzzles where brute force isn’t enough. They’re still playable and included; when a human solves one in play_human.py, it gets automatically promoted to validated.
The pipeline funnel from raw data to playable levels:
5. Architecture: From Puzzle Data to Playable Environments
A good renderer disappears. You don’t think about pixels — you think about paths, regions, constraints. The 64×64 grid is just a window into the abstract puzzle space.
System Overview
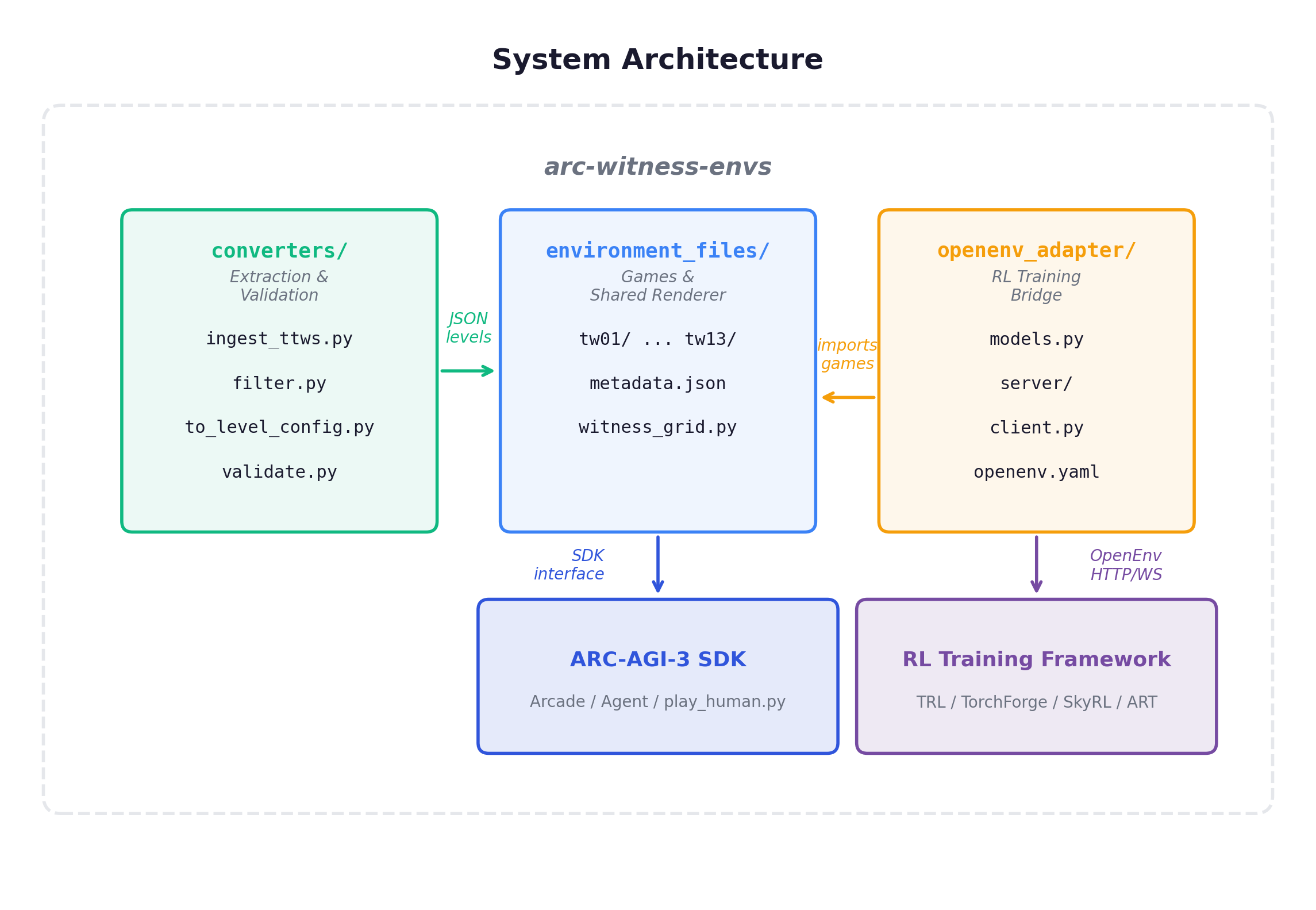
Three subsystems: converters/ (extraction pipeline), environment_files/ (the 13 games), openenv_adapter/ (RL training bridge).
The Extraction Pipeline
Where do 1,872 levels come from? From a systematic pipeline that extracts, classifies, converts, solves, and exports puzzles from community data.
The source is barrycohen/ttws, a community project that decoded The Witness’s puzzle data — 2,605 puzzles in protobuf format.
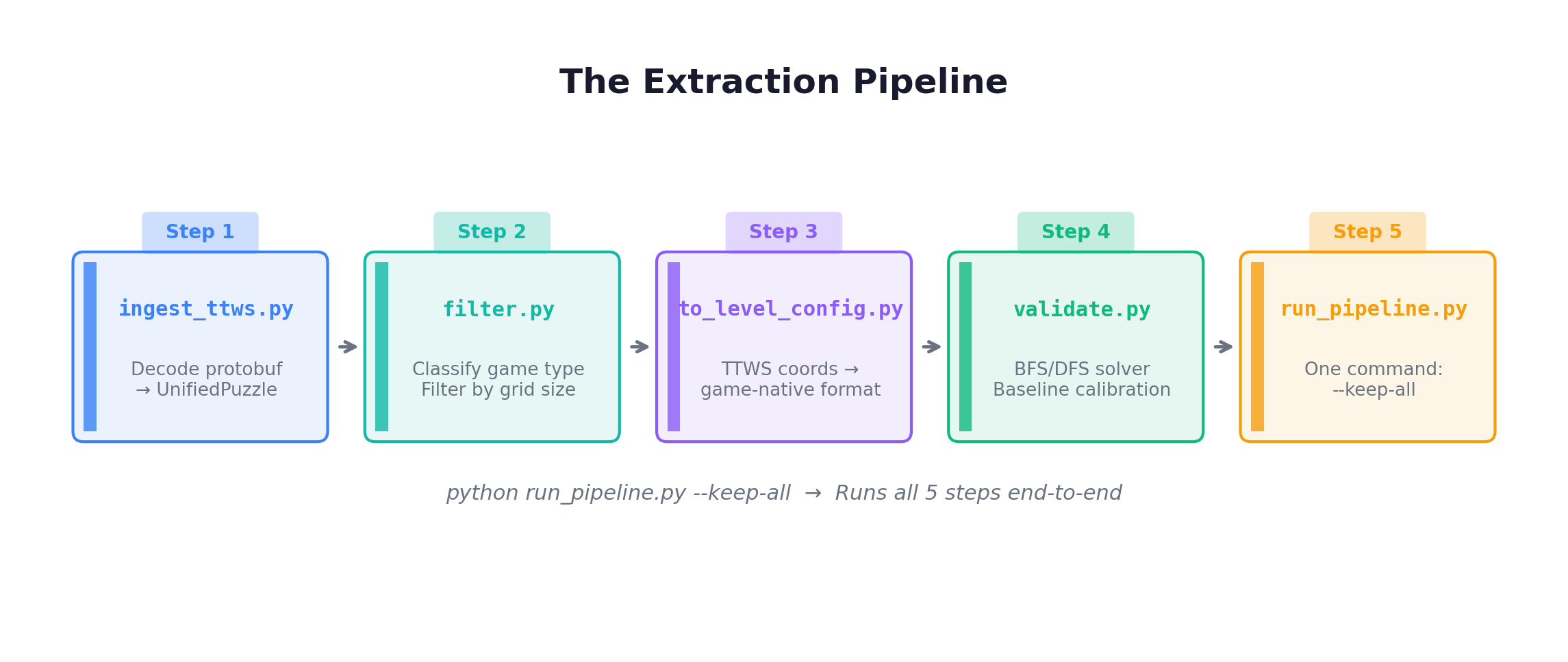
The classifier is essentially a decision tree over symbol presence: has hex dots only → tw01; has colored squares only → tw02; has polyominoes only → tw03; has symmetry → tw04; and so on. tw09 (CylinderWrap) and tw10 (ColorFilter) are hand-crafted — cylinder topology and color perception don’t exist in the TTWS dataset.
WitnessGrid — The Shared Renderer
All 13 games share WitnessGrid, responsible for mapping abstract puzzle state into 64×64 pixel frames.
class WitnessGrid:
def __init__(self, cols: int, rows: int, margin: int = 4):
self.cols = cols
self.rows = rows
avail = 64 - 2 * margin # Available pixel space: 56
self.node_size = 1
self.line_width = 1
max_dim = max(cols, rows)
self.cell_size = (avail - (max_dim + 1) * self.node_size) // max_dim
# Center the grid within the 64×64 canvas
total_w = (cols + 1) * self.node_size + cols * self.cell_size
self.offset_x = margin + (avail - total_w) // 2For a 4×4 grid: cell_size = (56 - 5) // 4 = 12 pixels per cell. For an 8×8 grid: cell_size = (56 - 9) // 8 = 5 pixels. Auto-adapts to any grid size that fits.
Three coordinate systems coexist:
| System | Range | Represents |
|---|---|---|
| Nodes | [0, cols] × [0, rows] | Path intersections |
| Cells | [0, cols-1] × [0, rows-1] | Spaces holding symbols |
| Pixels | [0, 63] × [0, 63] | Final rendering |
Drawing primitives for every symbol type:
| Method | What It Draws |
|---|---|
render_grid() | Empty grid with lines and cell backgrounds |
draw_path_segment(node1, node2) | Blue path between adjacent nodes |
draw_dot(node) / draw_start / draw_end | Yellow dot / green start / red end markers |
draw_cell_symbol(cell, color) | Colored square in cell center |
draw_star(cell, color) | Diamond-shaped star symbol |
draw_triangle(cell, count) | 1-3 small orange triangles |
draw_polyomino(cell, shape) | Tetris piece preview |
draw_eraser(cell) | Y-shaped elimination symbol |
draw_breakpoint(node1, node2) | Gap on blocked edge |
path_splits_regions(path) | BFS region extraction (foundation for all region constraints) |
cell_edge_count(cell, path_edges) | Count path edges touching a cell (for triangles) |
The Game Implementation Pattern
Every game follows the same architecture:
ARCBaseGame (from arcengine SDK)
├── __init__() → Load levels from JSON, create Level/Sprite objects
├── on_set_level() → Initialize game state for the current level
├── step() → Process one GameAction, validate, update display
└── next_level() → Advance when solution is correctThe step() method is where each game’s unique logic lives. Here’s the annotated core from tw01:
def step(self) -> None:
action = self.action.id
current = self._current_node()
if action == GameAction.ACTION5: # CONFIRM — submit path
self._check_solution()
elif action in (ACTION1, ACTION2, ACTION3, ACTION4): # Movement
dc, dr = {
ACTION1: (0, -1), # Up
ACTION2: (0, 1), # Down
ACTION3: (-1, 0), # Left
ACTION4: (1, 0), # Right
}[action]
target = (current[0] + dc, current[1] + dr)
if self._is_valid_move(current, target):
if len(self._path) >= 2 and target == self._path[-2]:
self._path.pop() # Backtracking
elif target not in self._path:
self._path.append(target) # Extend path
self._update_display()
self.complete_action() # Required by SDK contractConstraint Validation — The Heart of Each Game
The _check_solution() method is where abstract mathematics becomes executable code:
tw01 (PathDots) — the simplest: are all dots in the path? Set membership check.
tw02 (ColorSplit) — extract regions via path_splits_regions(), check that each region contains only one color of square.
tw03 (ShapeFill) — NP-complete: extract regions, attempt exact cover with DFS and pruning, timeout after 3 seconds.
tw07 (EraserLogic) — meta-reasoning: extract regions, evaluate all non-eraser constraints, count violations, count erasers, verify #erasers == #violations.
The progression from tw01 to tw13 mirrors The Witness itself: from path checks to region checks to NP-complete tiling to meta-reasoning about constraint violations. Each game’s validation logic is a direct encoding of the formal constraint definitions from the original game.
6. RL Training: From Puzzles to Policy Gradients
The environment doesn’t care which framework you use. It presents a grid, accepts actions, and returns a reward. Everything else is your problem.
The Dual Interface
The game logic should never know it’s being used for RL training. The 13 games implement puzzle mechanics. They don’t know what a reward function is. This separation is the most important architectural decision in the project.
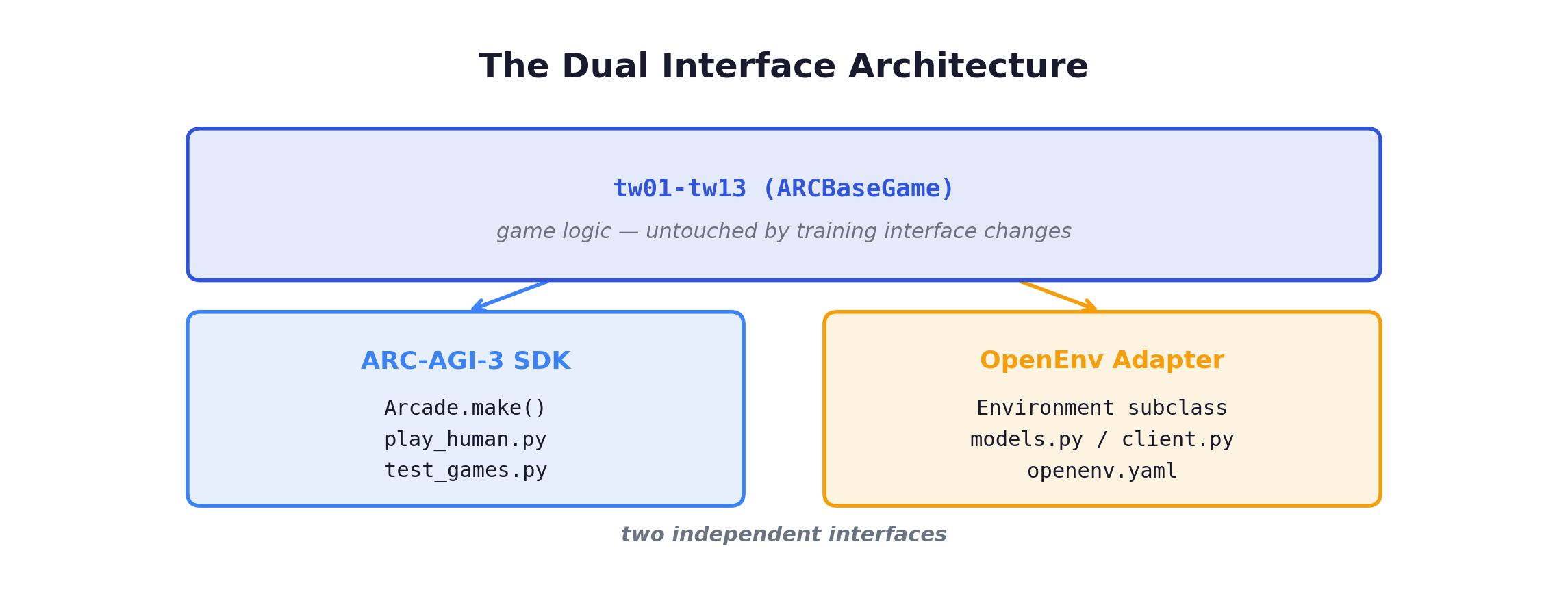
The OpenEnv adapter has gone through three reward function revisions and two observation encoding changes — and the game code hasn’t been touched once. The puzzles are stable. The training interface is not.
OpenEnv Protocol
An episode = one puzzle level. reset() initializes the level. step(action) processes moves. Episode ends on solve or truncation (max_steps = baseline × 3).
- Observation: 64×64 integer grid (color indices 0-15)
- Action: Discrete 1-5 (UP/DOWN/LEFT/RIGHT/CONFIRM)
- Truncation:
max_steps = baseline × 3
Three Reward Modes
| Mode | Solve Reward | Step Penalty | Wrong CONFIRM | Best For |
|---|---|---|---|---|
sparse | +1.0 | 0 | 0 | Exploration-heavy (RND, ICM) |
shaped (default) | +1.0 | -0.01 | -0.1 | PPO, SAC |
arc_score | min(baseline/steps, 1) | 0 | -0.1 | GRPO (mirrors ARC-AGI-3 scoring) |
Key design property: solving a level is ALWAYS a positive reward signal, regardless of how many steps it took. In shaped mode, the worst-case accumulated penalty for a 20-step baseline is -0.6 against +1.0 for solving — net positive. This prevents the agent from learning to avoid attempting solutions.
Algorithm-Reward Pairing
| Algorithm | Recommended Mode | Why |
|---|---|---|
| PPO / APPO | shaped | Step penalty encourages efficiency; dense signal stabilizes advantage estimation |
| DQN | shaped | Natural fit for discrete 5-action space |
| GRPO | arc_score | Directly mirrors ARC-AGI-3 scoring; outcome-based optimization |
| RND / ICM | sparse | Pure exploration signal; intrinsic curiosity provides density |
| SAC | shaped | With discretized action space |
GRPO with arc_score is the most interesting pairing. Different rollouts for the same level get different rewards based on efficiency — a natural ranking signal that GRPO was designed to exploit.
Compatible RL Frameworks
| Framework | OpenEnv Support | RL Algorithms | Notes |
|---|---|---|---|
| TRL (HuggingFace) | Official | GRPO | GRPOTrainer with custom rollout_func |
| TorchForge (Meta) | Native | GRPO, PPO | Direct plug-in, scales to 512 GPUs |
| SkyRL | Official | GRPO, PPO, DAPO | Megatron 5D parallelism |
| ART (OpenPipe) | Official | GRPO | Any OpenEnv environment works |
| VeRL (ByteDance) | Planned | PPO, GRPO | Architecturally compatible |
| Oumi | Via TRL | GRPO | Uses TRL’s GRPOTrainer |
Important caveat: these frameworks are primarily designed for LLM-based agents (text in, text out). For 64×64 int grid observations, you’ll likely need a vision encoder (simple CNN) or a multimodal model. The OpenEnv adapter handles the environment side — the model architecture is up to you.
Quick Start
Server + Client (distributed training):
pip install arc-agi openenv
cd arc-witness-envs
uvicorn openenv_adapter.server.app:app --host 0.0.0.0 --port 8000
# Serve specific game and reward mode
WITNESS_GAME=tw03 WITNESS_REWARD=arc_score uvicorn openenv_adapter.server.app:app --port 8000import asyncio
from openenv_adapter.client import WitnessEnvClient
from openenv_adapter.models import WitnessAction, WitnessGameAction
async def main():
client = WitnessEnvClient(base_url="ws://localhost:8000")
async with client:
result = await client.reset()
print(f"Level: {result.observation.level_index}")
for action in [WitnessGameAction.RIGHT, WitnessGameAction.UP,
WitnessGameAction.CONFIRM]:
result = await client.step(WitnessAction(action=action))
print(f"Reward: {result.reward}, Done: {result.done}")
asyncio.run(main())Direct Python (simplest, no server):
from openenv_adapter.server.witness_environment import WitnessEnvironment
from openenv_adapter.models import WitnessAction, WitnessGameAction
env = WitnessEnvironment(game_id="tw01", seed=0)
obs = env.reset()
obs = env.step(WitnessAction(action=WitnessGameAction.RIGHT))
print(f"Reward: {obs.reward}, Done: {obs.done}")
print(f"Frame shape: {len(obs.frame)}x{len(obs.frame[0])}") # 64x64What Should You Train First?
Start with tw01 (PathDots) in shaped mode. This is the simplest game — a basic PPO agent should start solving early levels within a few hundred episodes. If it doesn’t, something is wrong with your setup.
Move to tw02 (ColorSplit) — region-based constraints. Then tw05 (StarPair) — counting constraints that require global reasoning. Beyond that, the right approach shifts from “train longer” to “train smarter” — curriculum learning, intrinsic motivation, or transferring representations from earlier games.
7. Reflections: Ten Years of Witnessing
You wake up. Not in the game — from it. The screen fades and you’re sitting in your chair, but the island is still there behind your eyes. The panels, the rules, the moment when everything clicked. You carry it with you.
A Decade Between Two Blog Posts
In 2016, I played The Witness and wrote about it. That blog post was about a game. This one is about what happens when you take that game’s design philosophy — teach abstract rules through pure interaction, no instructions — and turn it into a machine learning problem.
Ten years. The game asked: can a player discover abstract rules through interaction alone? ARC-AGI-3 asks the same question, but to machines. And arc-witness-envs is my attempt to build the training gym for that question.
Fluid Intelligence Doesn’t Last Forever
I’ll be honest: I haven’t gone back to platinum The Witness again. It would probably only take a weekend. But I can’t quite bring myself to face the possibility that my fluid intelligence isn’t what it was ten years ago.
Human Gf peaks in our early-to-mid twenties and enters a slow, measurable decline. The Cattell-Horn-Carroll model is unambiguous on this. Gc keeps growing — I know more now than I did at 26, have better intuitions, can draw on a deeper reservoir of patterns. But Gf — the raw capacity to see novel structure, to reason in unfamiliar territory — that capacity has a biological clock. And the clock doesn’t care how many papers you’ve read.
The funny thing is, this is exactly why we need machines to develop fluid intelligence. Human Gf peaks and declines. It’s a wasting asset, bound to neurons that age and connections that slow. But if we can teach it to an AI — if we can distill the “out-of-the-box factory settings” of human cognition into learnable priors — that intelligence doesn’t decay. It doesn’t get tired. It doesn’t lose a step at 35 and another at 45.
There’s a kind of melancholy in building a fluid intelligence benchmark you suspect you’d score worse on than your younger self. But there’s also a kind of hope: if the benchmark works, the thing it trains won’t have that problem.
The Awakening
Let me return to the secret ending one more time.
A person removes a headset. Walks through an office. Steps outside. Starts seeing puzzle patterns in power lines, pipe joints, shadow edges. The game is over, but the pattern-recognition can’t be turned off.
The Witness puzzles are the gym for fluid intelligence. The 1,872 levels are the simulation. The moment an agent solves enough puzzles to demonstrate general reasoning — to show it can discover rules, not just memorize solutions — it earns the right to “wake up.” To graduate from the training environment and face the real ARC-AGI-3 tasks that demand the same kind of reasoning but in forms it has never seen.
ARC-AGI-3 is our version of that test. And arc-witness-envs is one of the training gyms.
The 1,872 levels aren’t the destination. They’re the preparation.
Rules as Living Memory
One more thought that’s stayed with me since 2016.
When you beat The Witness, your character hasn’t leveled up. No +10 attack power, no legendary armor, no skill tree unlocked. All the growth happened in your mind: the rules you discovered, the patterns you internalized, the constraints you learned to compose.
This is the purest form of learning. The rules aren’t items in an inventory — they’re living memory, a global model that makes you faster and more accurate at everything that comes after. Every eureka moment — “oh, each star must pair with exactly one same-colored element” — becomes a permanent prior that accelerates every subsequent puzzle.
An RL agent training on arc-witness-envs should develop something analogous. The reward signal from solving tw01 isn’t just a number — it’s an opportunity to internalize “paths must visit mandatory waypoints.” The negative feedback from a wrong submission on tw07 isn’t just a penalty — it’s a signal that “constraint violations must be perfectly balanced by erasers.” These internalized rules are the agent’s equivalent of what the player carries out of The Witness: not loot, but understanding.
What’s Next
This release is a starting point:
- 13 games covering the full spectrum of Witness constraint types
- 1,872 levels extracted from community puzzle data + hand-crafted additions
- Two interfaces: ARC-AGI-3 SDK for competition, OpenEnv for RL training
- 959 solver-verified levels with baseline scores; 913 additional unvalidated levels
Where it could go:
- Procedural level generation — the Challenge area in The Witness randomizes puzzles from a rule pool. The same approach could generate unlimited training data.
- Multi-game curriculum learning — sequencing levels across games to optimize learning speed. Does learning one rule type make you better at discovering others?
- VLM integration — vision-language models as the agent backbone, since observations are pixel grids and the action space maps to token predictions.
- Community contributions — new games, level packs, constraint types. The architecture makes adding a game straightforward: subclass
ARCBaseGame, implementstep()and_check_solution(), writemetadata.json.
Get Involved
GitHub: github.com/Guanghan/arc-witness-envs
Star the repo if you find this useful. Open issues for bugs or ideas. PRs welcome — new games, level packs, framework integrations, or just telling me what breaks.
If you’re building an ARC-AGI-3 agent, point it at environment_files/ and let it learn. If you’re doing RL research, spin up the OpenEnv adapter and start training. If you’re studying abstract reasoning, curriculum learning, or compositional generalization — these environments offer something most RL benchmarks don’t: difficulty that comes entirely from reasoning, not from perception or motor control.
Welcome to chat or leave comments on X — I’d love to hear your thoughts, especially if you’ve played The Witness yourself.
The panels are lit. The lasers converge. The mountain opens. Now it’s your turn to witness.