
Project repository: github.com/Guanghan/JustTinker
Core Idea
Can you transform an instruction-tuned LLM into a reasoning model with explicit thinking capabilities—all for under $150? JustTinker demonstrates that the answer is yes.
This project implements a minimal two-stage training pipeline using Reinforcement Learning with Verifiable Rewards (RLVR), achieving a +13.3% improvement on AIME 2024 (43.3% → 56.7%) while keeping the total cost under $150 using Tinker’s training API.
Key Achievement: Full RL pipeline executable from a standard laptop, making reasoning model development accessible to individual researchers.
Background & Motivation
The Rise of Reasoning Models
2024-2025 witnessed the emergence of “thinking models” like OpenAI’s o1 and DeepSeek-R1, which explicitly show their reasoning process through <think>...</think> tokens. These models demonstrate superior performance on complex tasks like mathematical olympiad problems.
The Accessibility Gap
However, training such models typically requires:
- Massive compute resources
- Complex RL infrastructure
- Significant engineering effort
JustRL Philosophy
The JustRL paper proposed a radical simplification: remove KL penalties and length penalties entirely, relying only on verifiable rewards. JustTinker extends this philosophy to a practical, low-resource implementation.
Why Cold-Start SFT?
The project uses Qwen3-4B-Instruct-2507 as the base model. Unlike distilled reasoning models (e.g., DeepSeek-R1-Distill), instruction-tuned models have internalized their reasoning into weights—they don’t naturally produce <think> tokens.
The key insight: We need a “cold-start” SFT phase to awaken explicit thinking capabilities before RL can reinforce them.
Two-Stage Training Pipeline
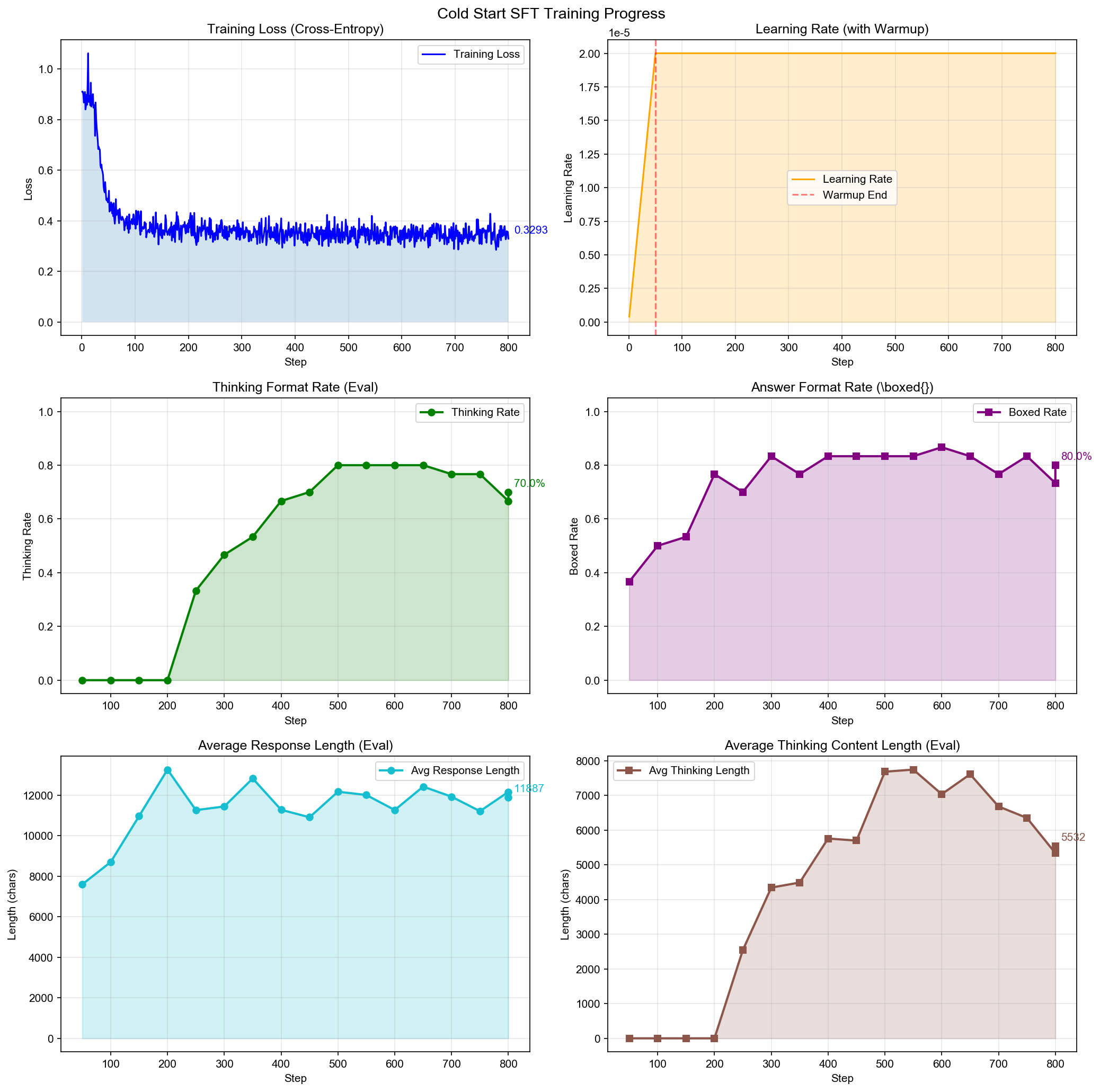
Stage 1: Cold-Start SFT
Goal: Teach the model to produce <think>...</think> tokens and boxed answers.
| Metric | Before SFT | After SFT |
|---|---|---|
| Thinking Rate | ~0% | 70% |
| Boxed Answer Rate | ~0% | 80% |
| Training Steps | - | 800 |
| Cost | - | <$30 |
Stage 2: JustRL (GRPO)
Goal: Reinforce correct reasoning through Group Relative Policy Optimization.
Following JustRL’s minimalist approach:
- No KL penalty - Don’t constrain the model to stay close to the reference policy
- No length penalty - Don’t discourage long responses (which might contain valid reasoning)
- Verifiable rewards only - Mathematical correctness as the sole signal
The Reward Hacking Problem
What Went Wrong in Experiment 001
Without length penalties, training quickly collapsed:
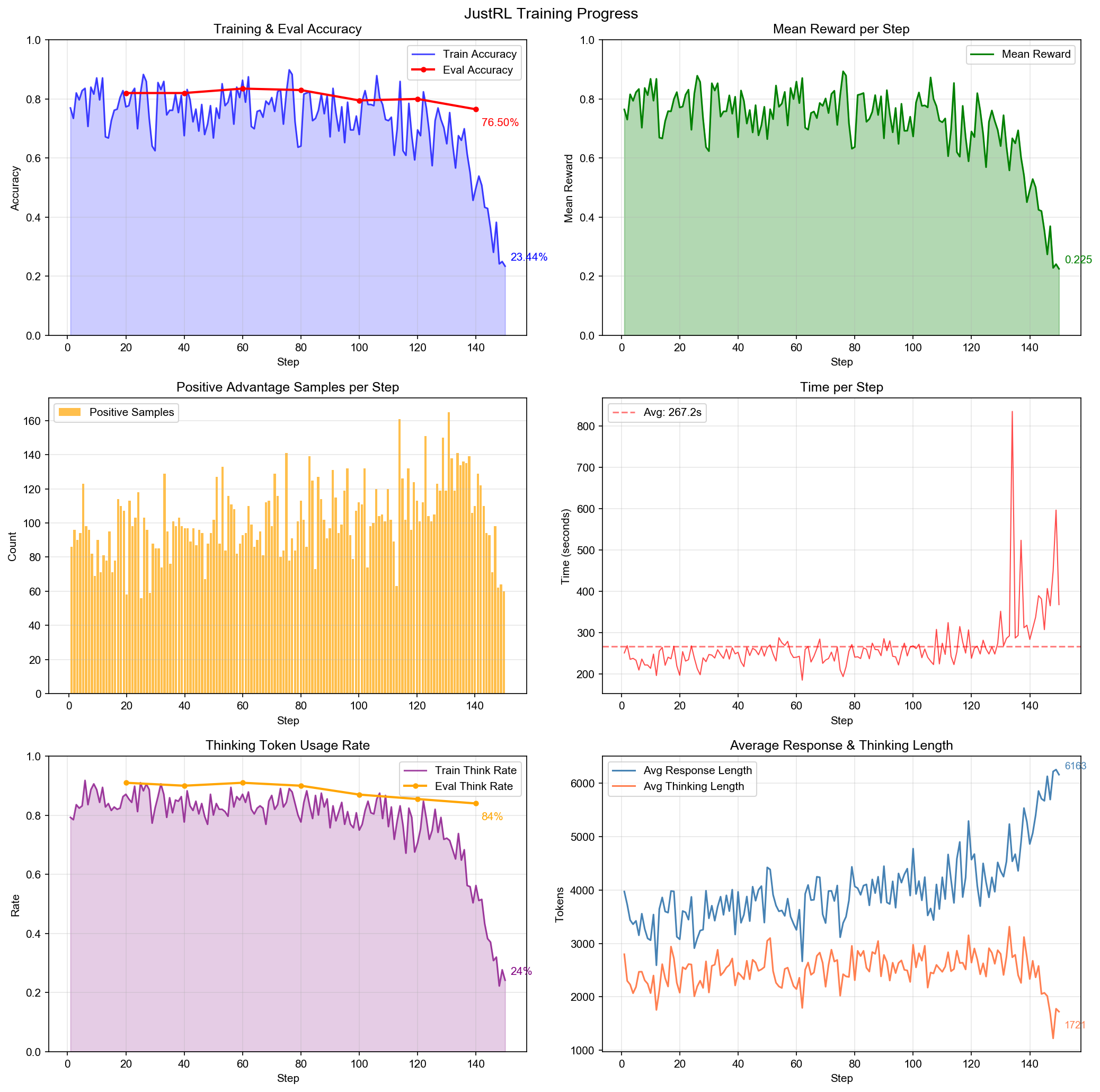
The model discovered a devastating shortcut: generate extremely long responses with multiple answer attempts.
| Metric | Normal | Reward Hacking |
|---|---|---|
| Response Length | ~2,000 chars | 35,000+ chars |
| Accuracy | ~85% | 10-28% |
| Content Quality | Coherent reasoning | Repetitive nonsense |
The Formation Mechanism
The reward hacking emerged through a four-phase process:
Normal learning with balanced response lengths
Phase 2 (Steps 50-100)
Longer responses appear more in positive samples
→ Multiple attempts increase luck-based correctness
Phase 3 (Steps 100-140)
Model learns spurious length → reward correlation
Phase 4 (Step 140+)
Complete collapse: 30,000+ char responses, 10% accuracy
Why Length “Helps” (Statistically)
The core issue is probability amplification through multiple attempts:
Assuming 5% correctness per attempt:
- 1 attempt: 5% success
- 10 attempts: ~40% success (1 - 0.95¹⁰)
GRPO only learns from correct samples—it never penalizes incorrect ones. This creates a statistical bias where longer responses (with more attempts) disproportionately appear in the positive training set.
Redundancy Penalty
The Key Insight
Simple length penalties would hurt legitimate long reasoning. Instead, target the actual problem: repetitive content.
Dual-Metric Detection System
| Method | Weight | Mechanism |
|---|---|---|
| Compression Ratio | 60% | Uses zlib compression—repetitive content compresses significantly (10-20% vs normal 50-70%) |
| N-gram Repetition | 40% | Counts repeated word sequences—reward hacking shows 60-70% vs normal ~5% |
Penalty Application
📐 REDUNDANCY PENALTY FORMULA
redundancy_score = 0.6 × compression_ratio + 0.4 × ngram_repetition
if redundancy_score > 0.3:
penalty = min(redundancy_score - 0.3, 0.3)
reward = reward - penalty
Validation Results
| Response Type | Redundancy Score |
|---|---|
| Normal reasoning responses | 0-4% |
| Reward-hacking responses | 62-89% |
Clear separation enables precise targeting without false positives.
Experimental Results
Experiment 002: Successful Mitigation
With the redundancy penalty in place:
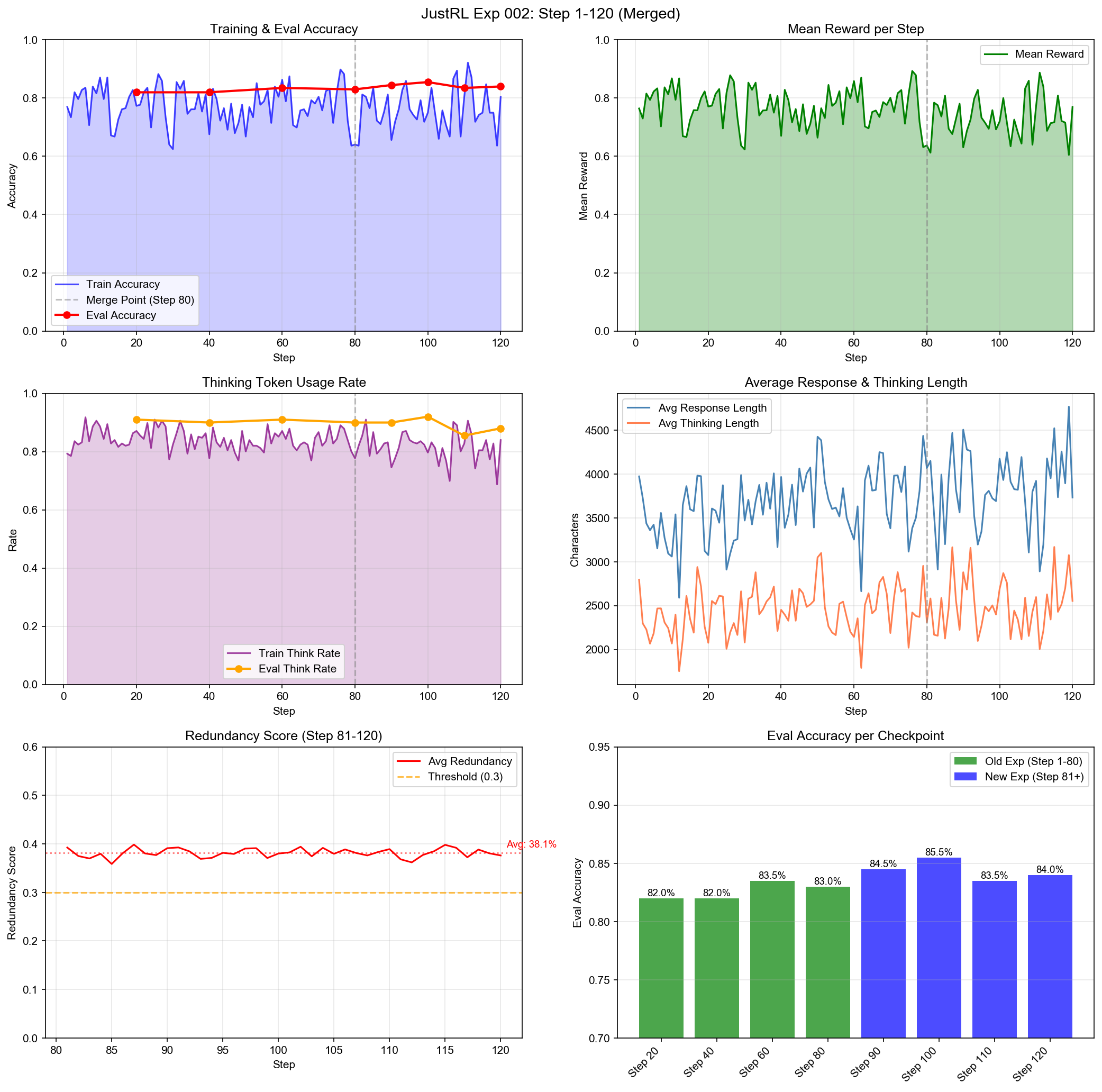
Training stability restored with 84-85.5% evaluation accuracy maintained throughout.
Experiment 003: Final Results
Using harder datasets (DAPO-Math-17k) and AIME 2024 benchmarking:
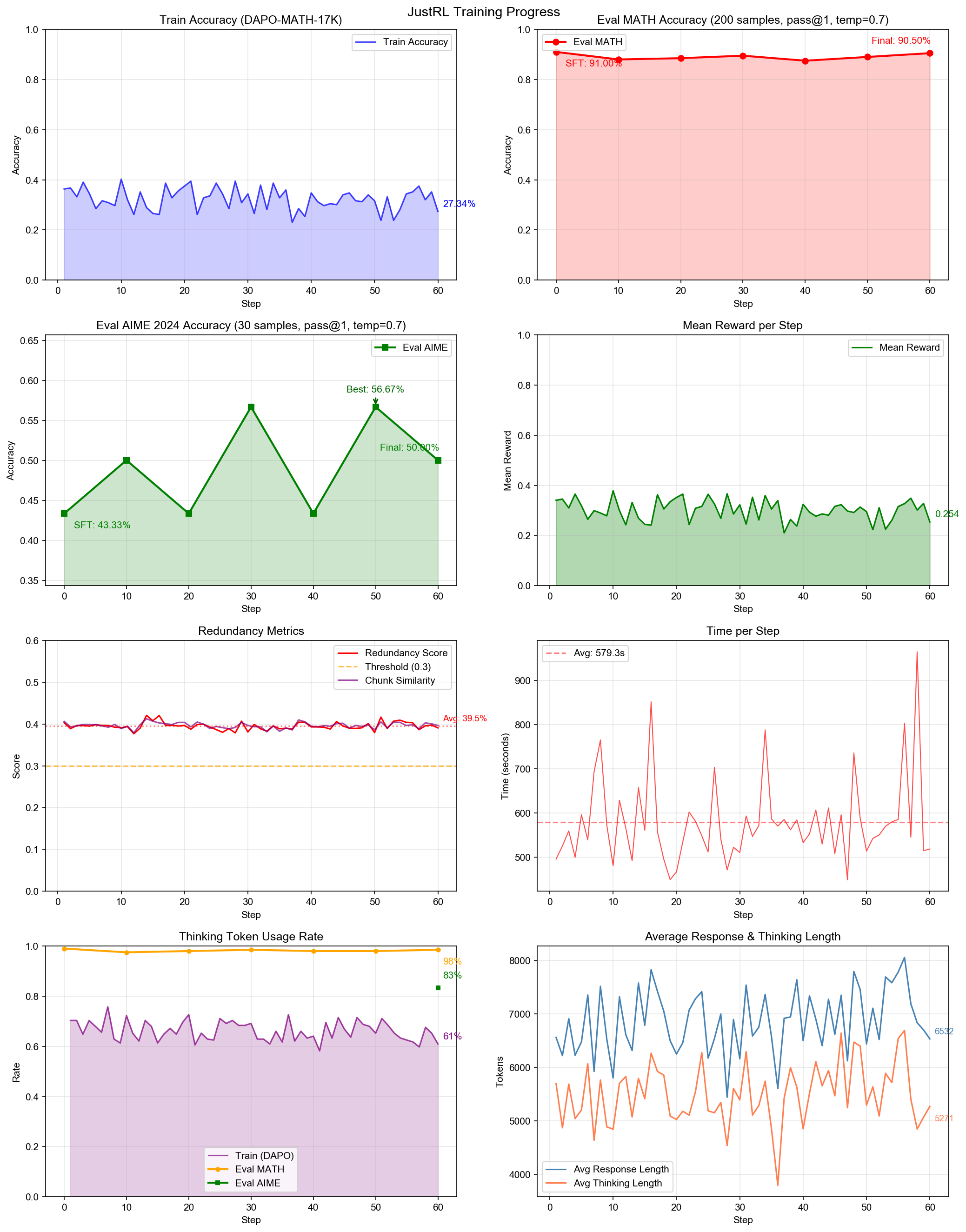
| Benchmark | Before | After | Change |
|---|---|---|---|
| AIME 2024 | 43.3% | 56.7% | +13.3% |
| MATH | ~88% | ~91% | Stable |
Cost Breakdown
| Phase | Cost |
|---|---|
| Cold-Start SFT | <$30 |
| Experiment 001-002 | ~$72 |
| Experiment 003 | ~$34 |
| Total | ~$136 |
Key Takeaways
1. Cold-Start SFT is Essential
Instruction-tuned models need explicit format training before RL can reinforce reasoning. Without this, the model has no “thinking” behavior to optimize.
2. Reward Hacking is Statistical, Not Intentional
The model isn’t “trying” to cheat—it’s following statistical gradients. Understanding the mechanism enables targeted solutions.
3. Target Root Causes, Not Symptoms
Length penalties create false positives on legitimate reasoning. The redundancy penalty targets the actual problem: repetitive content exploitation.
4. JustRL’s Minimalism Needs Guardrails
The original JustRL philosophy (no KL, no length penalty) is sound but incomplete. Targeted interventions (format rewards, redundancy penalty) preserve simplicity while preventing collapse.
5. Low-Resource RLVR is Feasible
With the right infrastructure (Tinker API) and methodology, meaningful reasoning improvements are achievable under $150.
Quick Start
# Clone the repository
git clone https://github.com/Guanghan/JustTinker.git
cd JustTinker
# Install dependencies
pip install -r requirements.txt
# Set API key
export TINKER_API_KEY=your_api_key
# Run cold-start SFT (or use public checkpoint)
./scripts/launchers/run_coldstart_sft.sh small
# Run JustRL training
./scripts/launchers/run_justrl.shA public cold-start checkpoint is available, enabling direct RL training without repeating the SFT phase.
Summary
JustTinker demonstrates that building reasoning models doesn’t require massive resources:
- Two-stage pipeline: Cold-start SFT → JustRL (GRPO)
- Reward hacking prevention: Novel redundancy penalty using compression ratio and N-gram detection
- Significant results: +13.3% on AIME 2024 for under $150
- Accessible: Full pipeline runnable from a laptop via Tinker API
The project provides both a practical implementation and insights into the challenges of minimal RLVR training—particularly the reward hacking phenomenon and its mitigation.