🎯 Key Result: Using the same Qwen2.5-Coder-7B-Base model, our SFT data curation pipeline produces an instruct model that outperforms the official Qwen2.5-Coder-7B-Instruct across Generic, Coding, and Math benchmarks:
- Generic: MMLU 68.75 vs 65.15, C-Eval 66.12 vs 61.59
- Coding: Arena Hard 50.49 vs 36.47 (+14🔥), LiveCode Bench 39.13 vs 34.50
- Math: MATH 70.90 vs 68.28, GSM8K 90.90 vs 88.17, AMC 2023 52.50 vs 41.75 (+10.8🔥)
1. Methodologies
Given the open-source Qwen2.5 coder base model, we collect & curate its instruction finetuning data.
1-1. Data Collection & Preprocess
| Dataset | HuggingFace Source | More Info |
|---|---|---|
| LIMA | tulu-v2-sft-mixture-lima | Paper: arxiv, Size: 1,018 |
| lmsys-chat-1m | lmsys-chat-1m | Paper: arxiv, Size: 1,000,000. 1M real conversations (210K users with 25 different SOTA LLMs), 154 languages, avg 2 turns per conversation |
| WizardLM v1 | WizardLM_evol_instruct_70k | Paper: arxiv, v1: 70,000 (single-turn) |
| WizardLM v2 | WizardLM_evol_instruct_V2_196k | v2: 143,000 (includes multi-turn) |
| WebInstructFull | WebInstructFull | Paper: arxiv, Size: 11,621,594 (5B tokens). Mined 10M from CC, rewritten with Mixtral & Qwen. 20%+ improvement on MATH/GSM8K, ~10% on MBPP/ArenaHard |
| InfinityInstruct | Infinity-Instruct | GitHub |
1-2. Data Analysis
1-2-1. Infinity Instruct
To construct a ten-million high-quality instruction dataset, we collect a large amount of open-source data as seed and iterate the dataset using two strategies: instruction selection and instruction evolution. We recommend applying the Foundational Dataset, which contains millions of instructions selected from open-source datasets, to improve the performance of models on challenging downstream tasks (e.g., code, math). We recommend applying the Chat Dataset, which contains about 1M instructions evolved from a small subset of high-quality seed data, to further improve the instruction-following ability of models in real conversation scenarios.
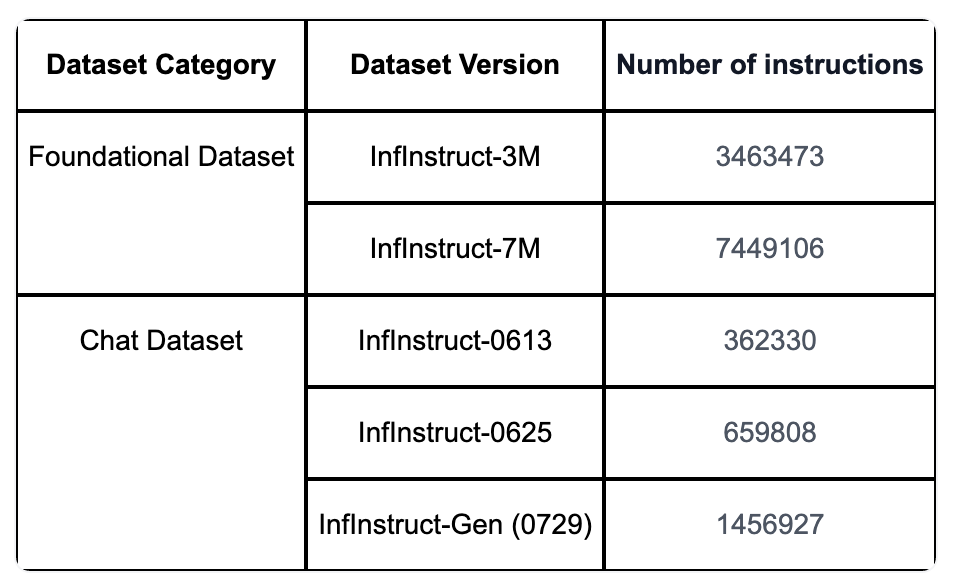
Subjective dataset components:
| Raw Dataset | Rows | HuggingFace URL | Paper URL |
|---|---|---|---|
| Alpaca GPT4 data | 13,490 | alpaca-gpt4-data | N/A |
| Alpaca GPT4 data zh | 32,589 | alpaca-gpt4-data-zh | N/A |
| Baize | 14,906 | baize-v2-13b | arxiv |
| BELLE Generated Chat | 43,775 | generated_chat_0.4M | GitHub |
| BELLE Multiturn Chat | 210,685 | multiturn_chat_0.8M | |
| BELLE 3.5M CN | 312,598 | train_3.5M_CN | |
| BELLE School Math | 38,329 | school_math_0.25M | |
| databricks-dolly-15K | 10,307 | databricks-dolly-15k | N/A |
| LIMA-sft | 712 | tulu-v2-sft-mixture-lima | arxiv |
| CodeContest | 523 | code_contests | arxiv |
| LongForm | 3,290 | LongForm | arxiv |
| ShareGPT-Chinese-English-90k | 8,919 | ShareGPT-Chinese-English-90k | N/A |
| UltraChat | 276,345 | ultrachat_200k | arxiv |
| Wizard evol instruct zh | 44,738 | EvolInstruct_zh_DeepseekAPI | arxiv |
| Wizard evol instruct 196K | 88,681 | - | arxiv |
| Code Alpaca 20K | 13,296 | - | GitHub |
| WildChat | 61,873 | WildChat-1M | arxiv |
| COIG-CQIA | 45,793 | COIG-CQIA | arxiv |
| BAGEL | 55,193 | code_bagel | N/A |
| DEITA | 10,000 | deita-10k-v0 | arxiv |
| Math | 320,130 | - | N/A |
| Summary | 1,362,000 |
1-2-2. WebInstructFull
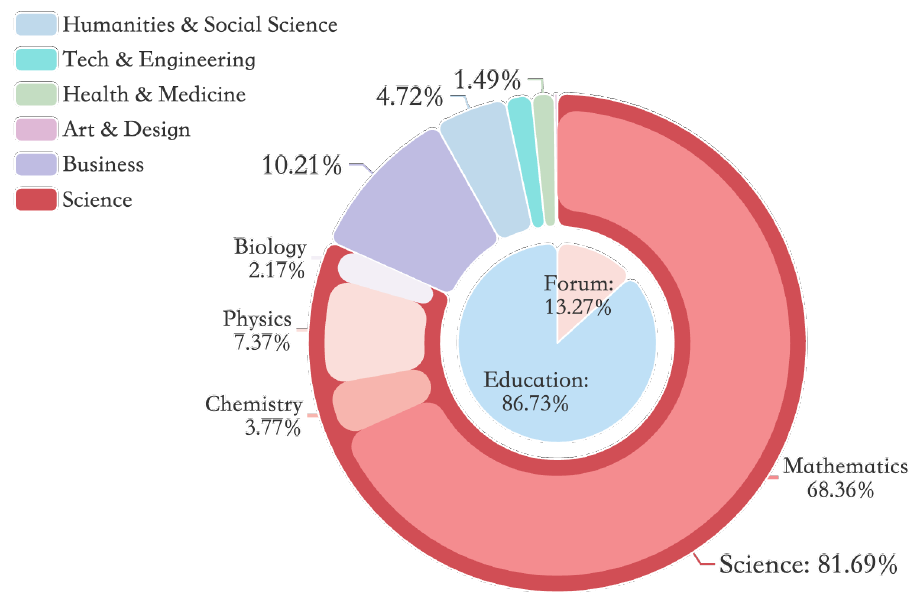
Existing SFT Datasets:
| Dataset | #Pairs | Domain | Format | Dataset Source |
|---|---|---|---|---|
| FLAN V2 | 100K | General | SFT | NLP data + Human CoT |
| Self-Instruct | 82K | General | SFT | Generated by GPT3 |
| GPT4-Alpaca | 52K | General | SFT | Generated by GPT4 |
| SuperNI | 96K | General | SFT | NLP Datasets |
| Tora | 16K | Math | SFT | GPT4 GSM+MATH Synthesis |
| WizardMath | 96K | Math | SFT | GPT4 GSM+MATH Synthesis |
| MathInstruct | 262K | Math | SFT | GPT4 Math datasets Synthesis |
| MetaMathQA | 395K | Math | SFT | GPT-3.5-Turbo GSM+MATH Synthesis |
| XwinMath | 1.4M | Math | SFT | GPT4 GSM+MATH Synthesis |
| OpenMathInstruct | 1.8M | Math | SFT | Mixtral GSM+MATH Synthesis |
Existing CT (Continue Training) Datasets:
| Dataset | #Tokens | Domain | Format | Dataset Source |
|---|---|---|---|---|
| OpenWebMath | 12B | Math | LM | Filtered from Web |
| MathPile | 10B | Math | LM | Filtered from Web |
| Cosmopeida | 25B | General | LM | Synthesized by Mixtral |
| MINERVA | 38B | Math | LM | Filtered from Web |
| Proof-Pile-2 | 55B | Math | LM | OWM+Arxiv+Code |
| Galactica | 106B | Math & Sci. | LM | Filtered from Web |
| DeepseekMath | 120B | Math | LM | Recalled from Web |
| WebInstruct | (10M) 5B | Math & Sci. | SFT | Recall and Extracted from Web |
The SFT datasets are mostly from NLP datasets or completely synthesized by GPT-4. The CT datasets are much larger because they are filtered or recalled from the web. The content contains lots of noise. We are the first dataset to combine these two to build a high-quality yet large-scale SFT dataset.
1-3. Data Pipelines
1-3-1. Open-source Evol & Synthesis
Infinity Instruct is a typical example of using opensource SFT data as seed and performing instruct-evol as data augmentation.
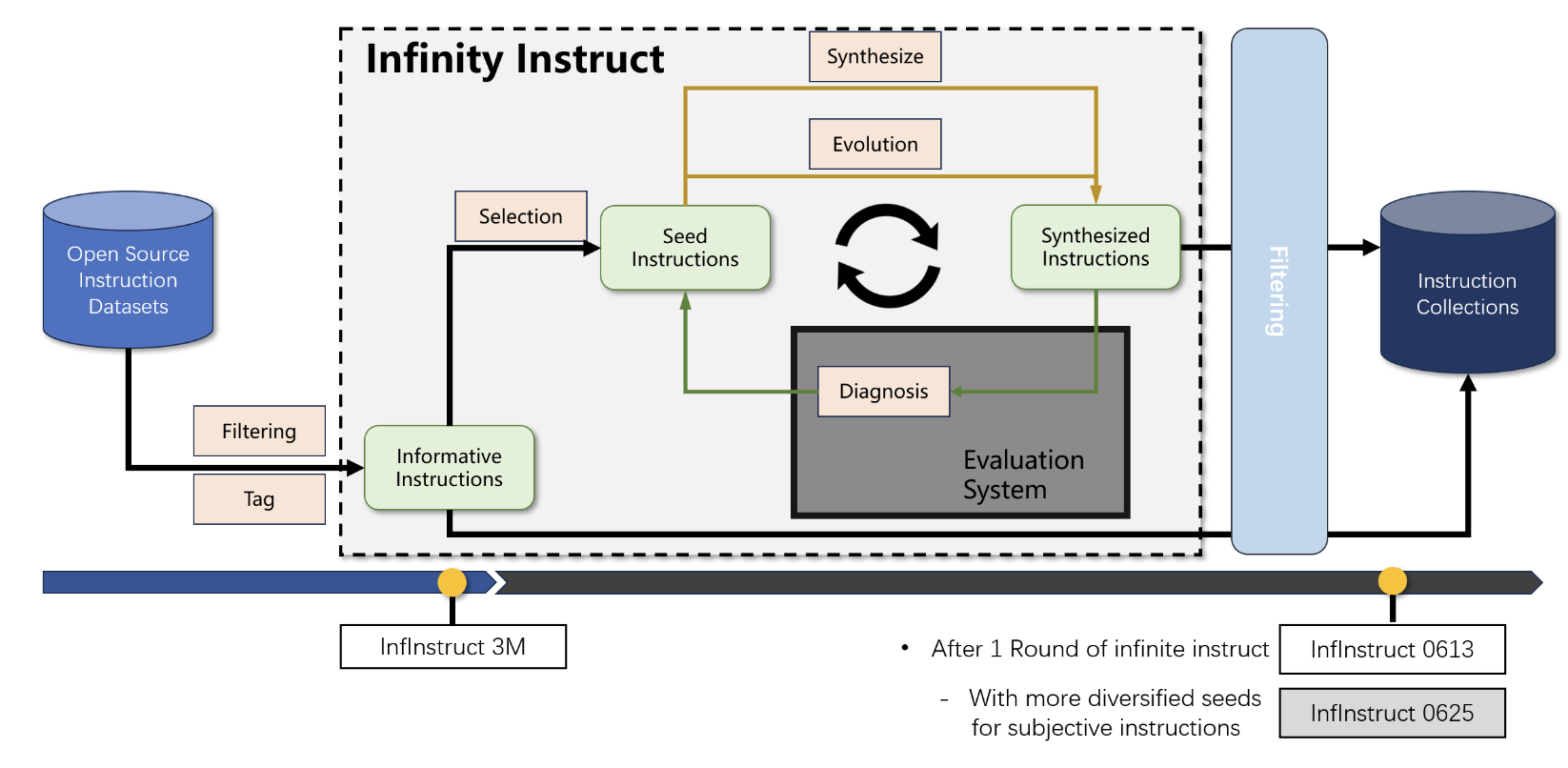
1. High-Quality Open Source Instruction Collection and Tag System
We start by collecting high-quality open-source instruction sets. We assign each instruction in the collection a set of tags that describe the abilities and knowledge necessary to complete the instruction.
- Instruction collection: We systematically reviewed available open-source instruction sets and included sets created by humans and advanced LLMs.
- Tag System with two levels:
- First level tag: Describe the specific knowledge and abilities required for completing each instruction (e.g., Arithmetic Calculation, Knowledge of Biology). The tags are automatically generated by LLM.
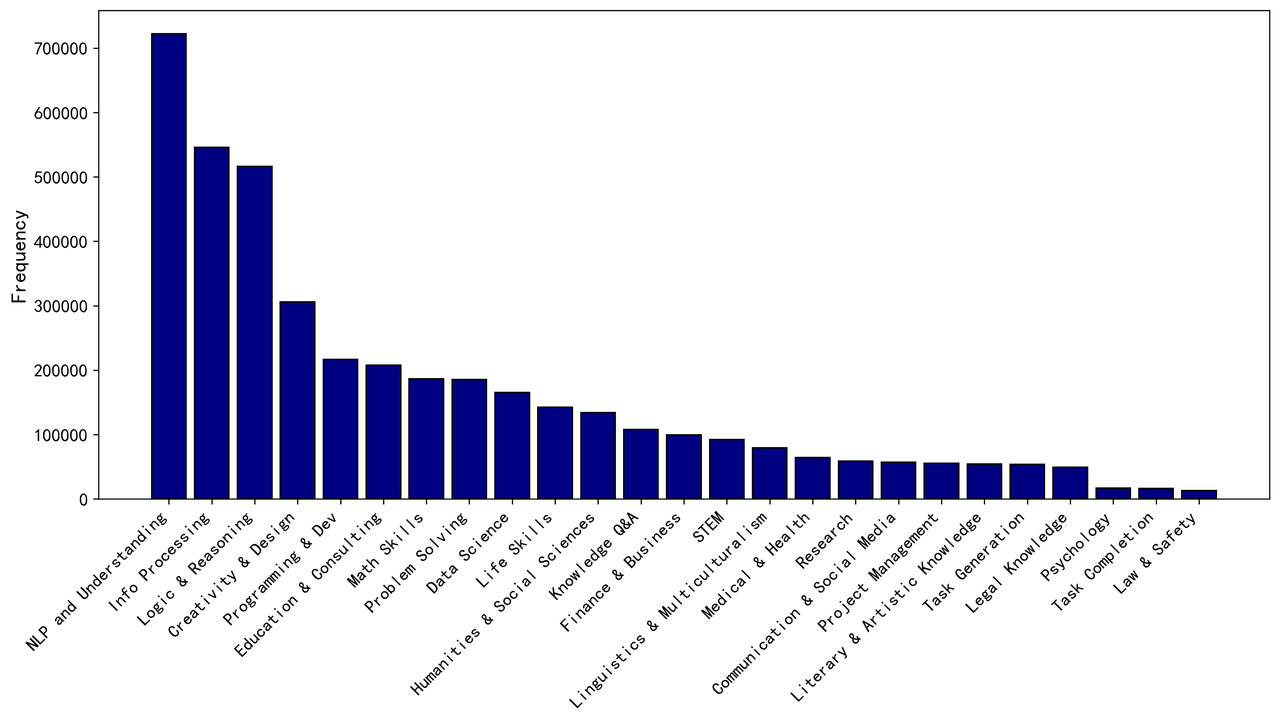
- Second level tags: Macro categories such as “Natural Language Processing” and “Math Reasoning.” Including 25 categories in total.
2. Informative Instruction Selection
Aimed at selecting the most informative instructions from the whole collection for enhancing the performance of LLM and improving user experience.
- [Complexity] Instructions demand multiple kinds of abilities or multiple domains of knowledge
- [Diversity] Instructions with long-tailed ability or knowledge
- [Difficulty] Instructions with high following difficulty
3. Instruction Generation by Data Evolution Strategy
We expand the seed instructions in directions breadth, depth, difficulty, and complexity with a method built based on Evol-Instruct method.
- Validate the evolved data, and use AI assistants to eliminate data that failed to evolve from the perspective of instruction compliance
- Use the evolved instructions as the initial input, and use an AI assistant to play different roles to generate 2 to 4 rounds of dialogue for each instruction
4. Instruction Generation by Model Ability Deficient Diagnosis
Automatically identifying weaknesses in the model’s capabilities to guide the synthesis of data.
- Model performance evaluation System
- Automatic ability deficient diagnosis
- Targeted data synthesis
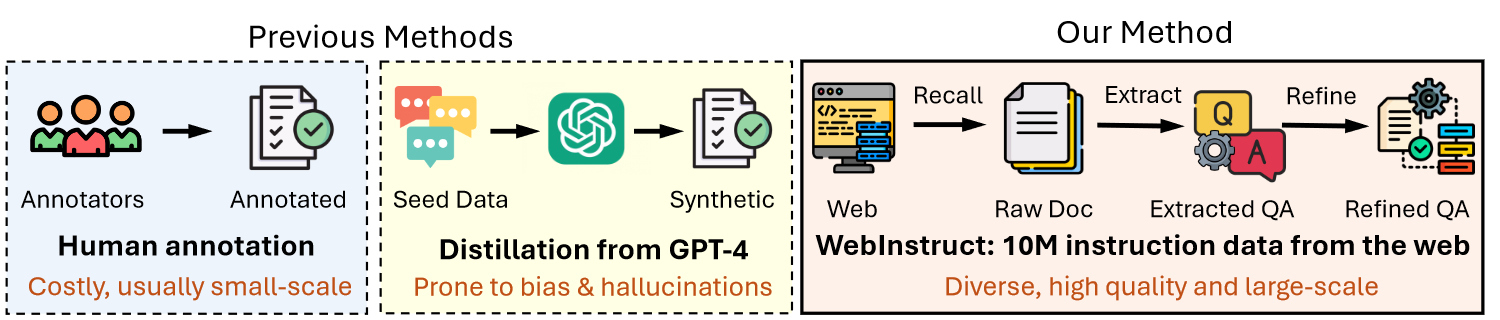
1-3-2. Web Crawling, Extracting & Refining
WebInstructFull is a typical example of crawling data from the web, extracting QA pairs out of it, and refining the responses.
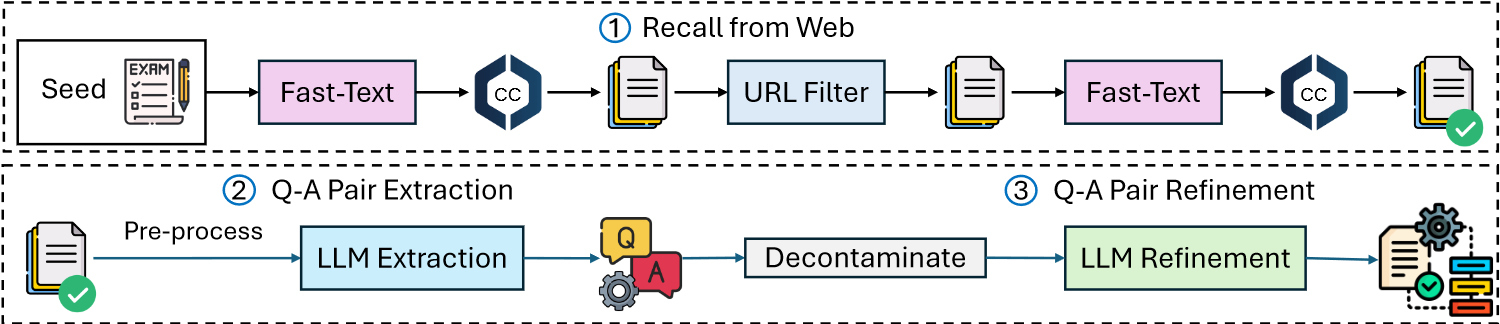
Stages: (1) high-quality data recall from the web corpus, (2) Q-A pair extraction and (3) Q-A pair refinement.
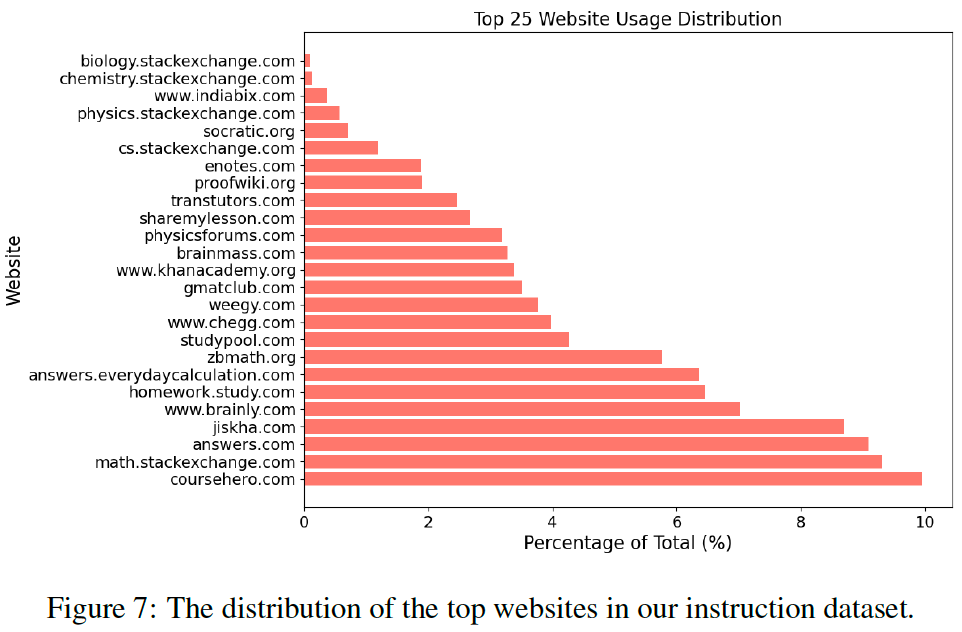
1. Recall from Common Crawl
To ensure diversity in our training data across various disciplines like math, science, and engineering, we propose crawling exam problems from educational websites such as stemez.com, homeworkstudy.com, and khanacademy.org. We collected 100K diverse seed examples and randomly selected 100K negative documents from Common Crawl (CC) for training a fastText model.
In the initial stage, the trained fastText model recalls the top 100B documents from CC, categorizing them by domain (root URL). We employ GPT-4 to identify domains likely to contain instructional content. Subsequently, we sample additional documents from these selected domains as positive examples and use documents from non-selected domains and the general CC as negative examples to refine the fastText classifier. The updated classifier then recalls the top 18M documents for further processing.
2. Q-A Pair Extraction
Recalled documents contain diverse content from forums, homework, quizzes, and exams. Despite noise like ads and HTML, they contain valuable Q&A pairs. We preprocess by parsing HTML to remove unrelated info. We then use Mixtral-8×7B to identify Q&A pairs, resulting in 5M candidates.
3. Q-A Pair Refinement
To further improve extracted Q-A pair candidates, we prompt Mixtral-7B×8 and Qwen-72B to reformat the extracted Q-A pairs. If the answer does not contain any explanation, we prompt the LLMs to complete the intermediate reasoning steps leading to the answer. We adopt two models to increase diversity. Eventually, we harvest 10M Q-A pairs as our final instruction-tuning dataset WebInstruct.
1-3-3. Collecting Real Conversations between Human and LLMs
LMsys1M is a typical example of such a genre.
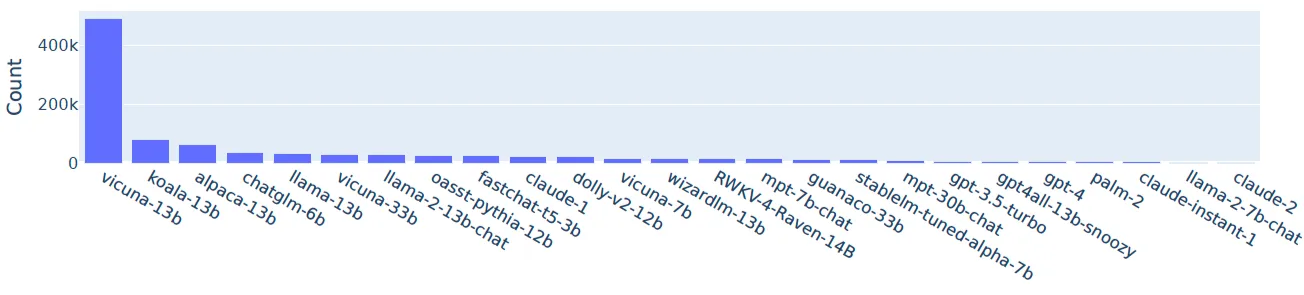
The dataset contains 1 million real-world conversations with 25 state-of-the-art LLMs. It is collected from 210k unique IP addresses in the wild on the Vicuna demo and Chatbot Arena website, from April to August 2023.
Arena-Hard-200, the 200 most challenging and high-quality user prompts are selected and curated from this LMSYS-Chat-1M dataset.
The data-collection website contains three types of chat interfaces: (1) single model, (2) chatbot arena (battle), and (3) chatbot arena (side-by-side).


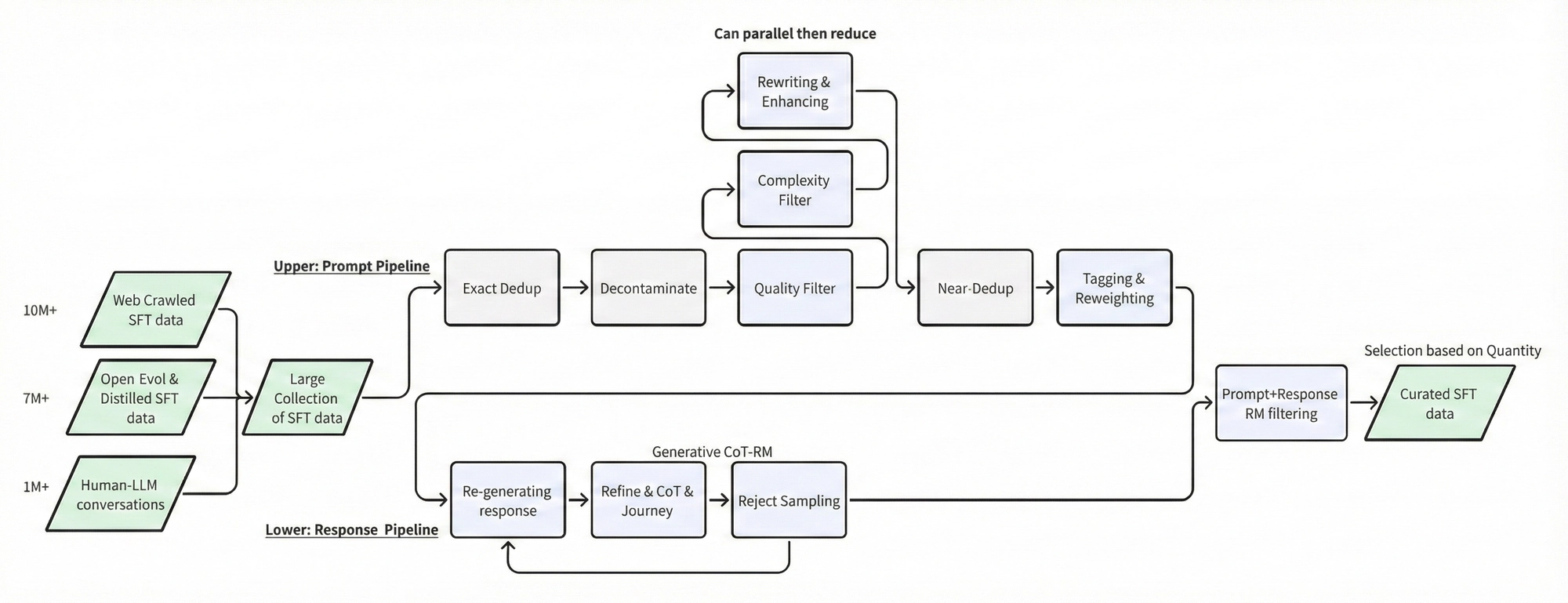
1-4. Our Pipeline
Given the two different sources of data mentioned above, we further process the large collection of data with our own pipeline:

Merge General SFT data
Number of Rows: 18,922,281
Exact Dedup & Decontamination
Exact dedup: 18,922,281 → 18,629,484
Quality Filter
Let our LLM-scorer assign each prompt a rating between 1-10.
For this comparatively easier task, we can just use a smaller inhouse or opensource model. We query the result with a required format in this “Reasons first, score last” order.
{
"reasons": "point out the issues and your reasons for the rating",
"score": "<integer>"
}Suffering from insufficient prompting, where the scoring guidelines are absent and only output spaces (e.g. 0-100) are provided, this will result in inconsistent and misaligned evaluations.
Therefore, we follow an LLM-as-evaluator prompt template:

Generic Criterions:
- A good prompt for benchmarking
- A greater score represents a greater potential to evaluate the LLMs in problem-solving, creativity, and truthfulness
- Trivial or ambiguous user prompts should get lower scores
Domain-based Templates:
Code Template Example
You are an excellent user question qualifier. You are responsible for evaluating the quality of programming questions submitted by users, including various types such as QA questions, multiple-choice, debugging tasks, code explanations, and more. Your goal to ensure they meet the standards for precision, clarity and solvability.
Steps:
Think and Understand: Start by thoroughly understanding the question's intent. Consider whether the question meets the qualifying principles listed below.
Analysis: Based on your understanding, explain whether the question satisfies each qualifying principle.
Score: Assign a quality score based on your analysis.
Scoring System:
1: The question is clear, precise, solvable and ready for use by the programming community.
0: The question is ambiguous, unclear or unsolvable and needs further clarification before it can be answered.
Qualifying Principles:
1. **Clear and Concise Problem Statement**:
- Clarity: The problem should be stated clearly. The reader should immediately understand the task after reading the problem.
2. **Relevant Background and Context**:
- Allow simpler or high-level questions to meet the clarity requirement without needing extensive detail. If the question is understandable, it should be rated positively.
3. **Reasonable Assumption**
- Assumption: The question should avoid unnecessary details, allowing the reader to make minor, reasonable assumptions to solve the problem without changing the intent of the question.
4. **Non-Trivial and Achievable Problem**:
- Difficulty: The question should present a problem that is solvable given the tools and constraints available.
5. **No Further Detail is Asked**:
- The question should not explicitly ask for more details or context to be provided by the responder. If the question itself is framed as a request for further clarification or additional information, it should be considered incomplete and not valid for evaluation.
Instruction Following:
- Please adhere strictly to the provided output format in the few-shot examples.
- Your response should consist of three essential sections: Thinking Steps, Analysis, Json Output.Complexity Filter
It has been recommended that we consider a prompt to be challenging if it requires integrating various knowledge and skills to derive appropriate responses. This will require both knowledge tagging & skill tagging. But this has some overlap with diversity.
Therefore, as the first resort, we simply decompose complexity here as the number of explicit instructions in a user query.
Instruction Counting: Count the number of specific instructions requested by the user.
PE for general instruction counting
You are an expert in analyzing user queries. Your task is to identify and enumerate all the specific explicit instructions present in a given user query.
---
**Requirements:**
Please note that there is no response provided. Your focus should be solely on the user's query.
Please list all the specific explicit instructions found in the user's query.
---
**Output Format:**
Please provide your output in the following JSON format:
{
"instructions": [
"Instruction 1",
"Instruction 2",
"Instruction 3"
],
"instruction_count": X
}
---
**User Query:**
{user_prompt}PE for instruction-following analysis (with response)
You are an expert in evaluating how well responses follow user instructions. Your task is to analyze the given user query and the corresponding response, identify all the specific explicit instructions in the user query, and assess how well the response fulfills each instruction.
---
**Requirements:**
1. **Instruction Identification:**
- List all the specific explicit instructions found in the user's query.
2. **Response Analysis:**
- For each instruction, analyze whether the response satisfies it completely, partially, or not at all.
- Provide reasons for your assessment.
3. **Scoring:**
- Assign a score between 0 and 10 based on how well the response follows the instructions, where:
- **0** means the response is completely unrelated to the user's instructions.
- **10** means the response fully satisfies all the instructions in the user's query.
---
**Output Format:**
Please provide your output in the following JSON format:
{
"instructions": [
"Instruction 1",
"Instruction 2",
"Instruction 3"
],
"analysis": {
"Instruction 1": "Analysis of how well the response fulfills Instruction 1.",
"Instruction 2": "Analysis of how well the response fulfills Instruction 2.",
"Instruction 3": "Analysis of how well the response fulfills Instruction 3."
},
"score": X
}Diversity: Intention Tagging & Reweighting
Plus, intention tagging is important. This tagging will also cover both knowledge and skill.
InsTag for diversity and complexity.
This algorithm adopts a “complexity-first” strategy by prioritizing queries with more (# of required knowledge and skills) tags and checking if each addition to the sub-dataset increases tag diversity. By doing so, it ensures that the final sampled sub-dataset not only meets the size requirement N but also maintains a high level of tag diversity. This approach helps the sampled subset represent as many tag categories from the original dataset as possible, even with a limited sample size.


PE for annotating intention tags
PE backbone:
You are an excellent user query tagging expert. Given the following example tags described below, for a given user query, you are responsible for providing one or more tags that fully cover the intentions of the user. Your goal is to ensure user prompts are tagged properly for user intention analysis.
**Example tags:**
{examples}
The example tags are not exhaustive, you can provide other finer tags as you see appropriate.
---
**Output Format:**
Please provide the evaluation for the given query in the following JSON format:
{
"explanation": "Explain what the tag is about",
"reasons": "Point out your reasons in assigning the tags to this query",
"tag": "list<string>"
}
---
**Query:**Example tags include: Tagging System, Instruction Classification, Format Specification, Intent Analysis, Content Generation, Information Retrieval, Data Extraction, Summarization, Translation, Sentiment Analysis, Error Correction, Advice Seeking, Educational Instruction, Task Automation, Content Moderation, Code Generation, Emotion Detection, Personalization, Knowledge Retrieval, Data Analysis, Opinion Generation, Scheduling, Problem Solving, Hypothetical Scenario, Comparative Analysis, Definition Request, Paraphrasing, Trend Analysis, Formatting, Simulation, Clarification Request, Example Generation, Step-by-Step Explanation, Creative Writing, Role-playing, Algorithm Explanation, Metadata Extraction, Pattern Recognition, Policy Compliance Check, Benchmarking, Contextual Understanding, Conversational Continuation, Error Diagnosis, Code Refactoring, Language Learning Assistance, Voice Tone Analysis, Mood Setting, Personal Development, Mind Mapping, Goal Setting, Proofreading, Fact Checking, Joke Telling, Storytelling, Songwriting, Poem Composition, Historical Contextualization, Cultural Explanation, Mathematical Calculation, Scientific Explanation, Logical Reasoning, Analogy Creation, Visual Description, User Feedback Analysis, Resource Recommendation, Time Management, Memory Recall, Event Planning, Feedback Provision, Stress Testing, Hypothesis Formation, Data Visualization, Conflict Resolution, Etiquette Guidance, Idea Brainstorming, Priority Setting, Budget Planning, Negotiation Strategy, Product Review, Risk Assessment, Language Style Conversion, Protocol Simulation, Statistical Analysis, Energy Conservation Tips, Environmental Impact Assessment, Health and Wellness Guidance, Ethical Dilemma Discussion, Memory Enhancement Techniques, etc.
Response Enhancement
After filtering for high-quality instructions, we also improve the response quality through two strategies:
(1) GPT4-o response replacement: We regenerate responses using GPT-4o to ensure higher quality and more consistent formatting across the dataset.
(2) Strategy tag for response selection: For instructions with multiple candidate responses, we use strategy tags to select the most appropriate response based on the instruction’s domain and complexity.
Attribute Analysis
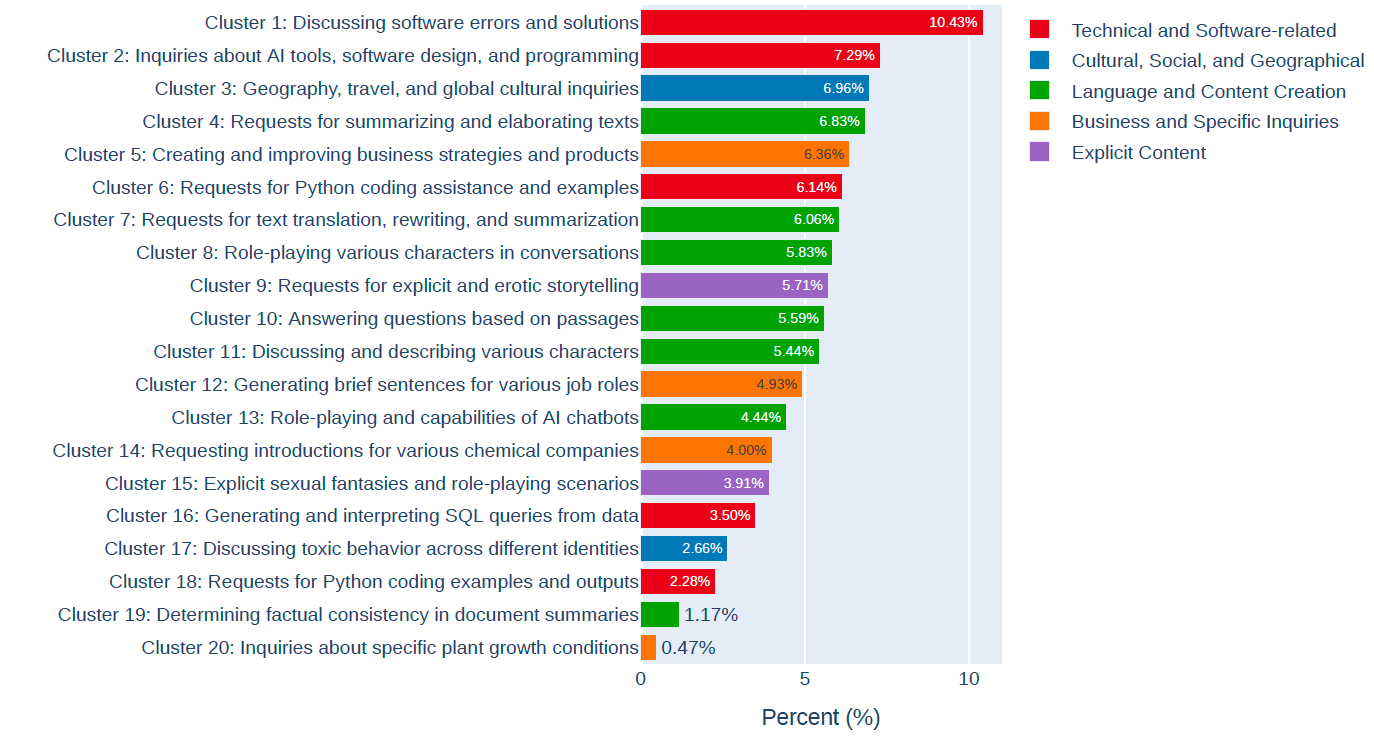
With all the filtering and enhancement steps complete, we now analyze the processed dataset to understand its characteristics. We examine the statistical distributions of various attributes, identify correlations between features, and ensure the final dataset maintains high quality and diversity.
Outlier Detection and Elimination
To ensure data quality, we identify and remove statistical outliers that could negatively impact model training. The following tables show the dataset statistics before and after outlier removal.
Before pruning the outliers:


After pruning: 2,407,758 rows left. [v1]

2,334,645 rows left. [v2]

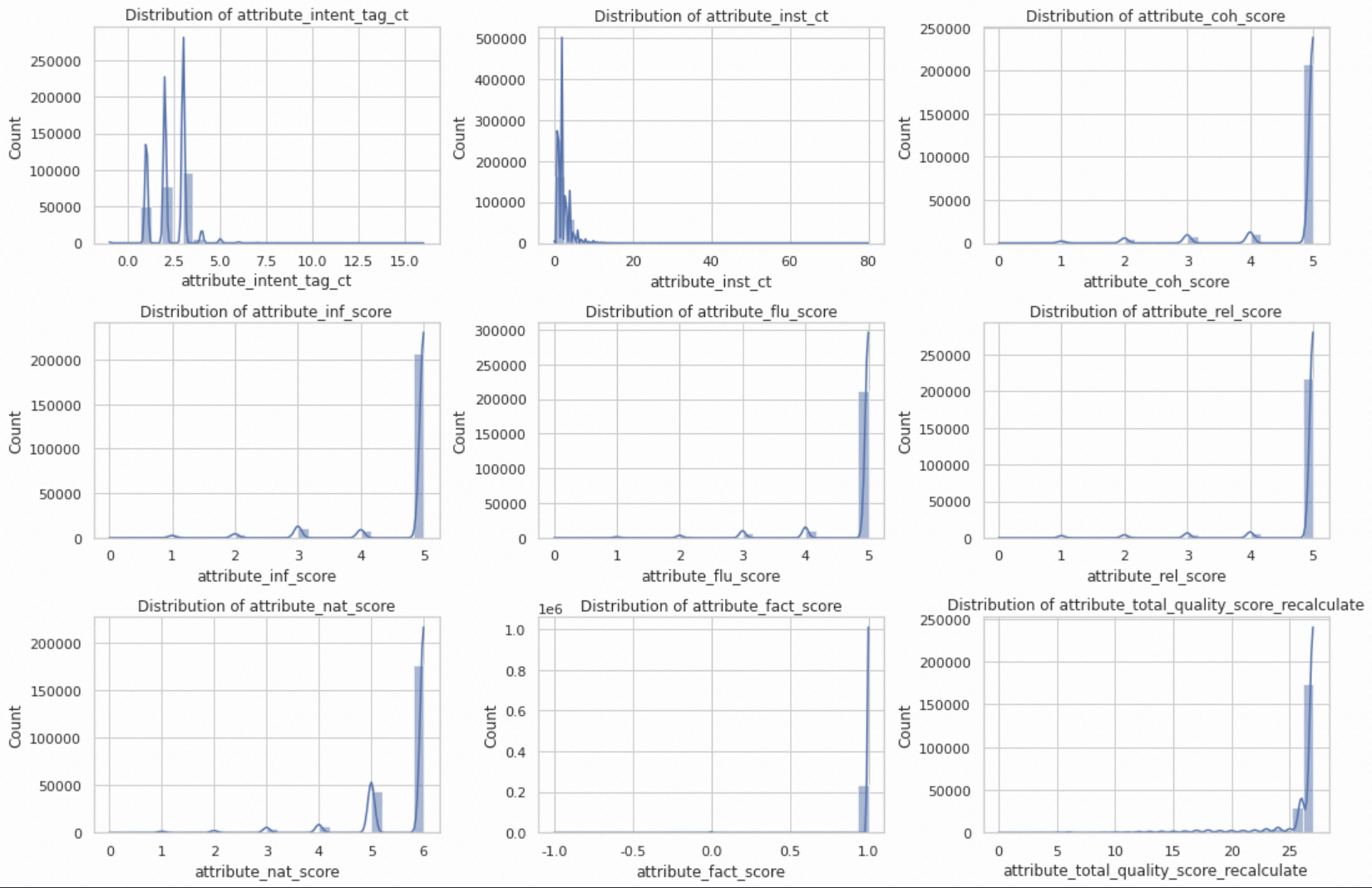
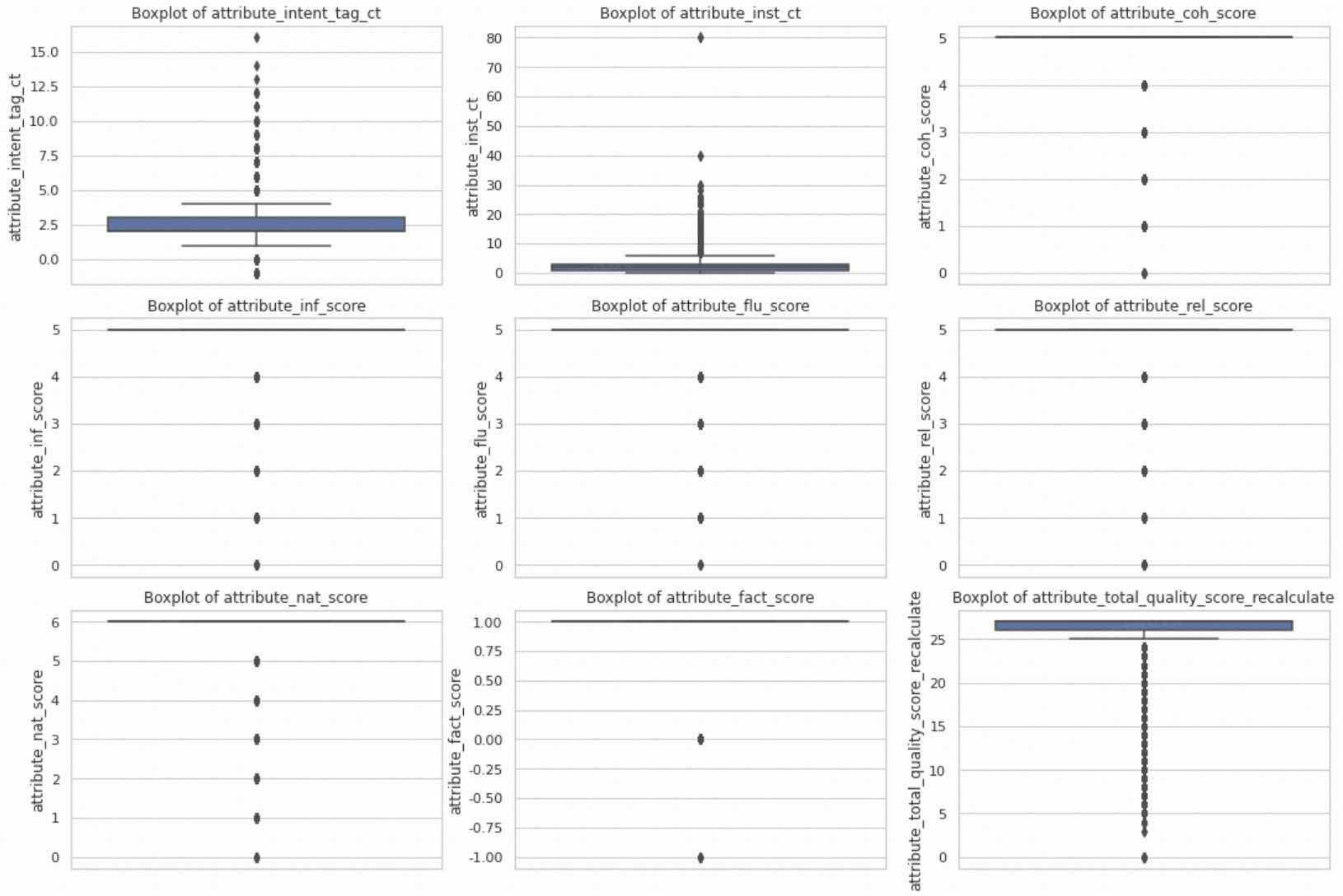
Distributions
Based on the distribution below, we filter the data accordingly.
Covariance:
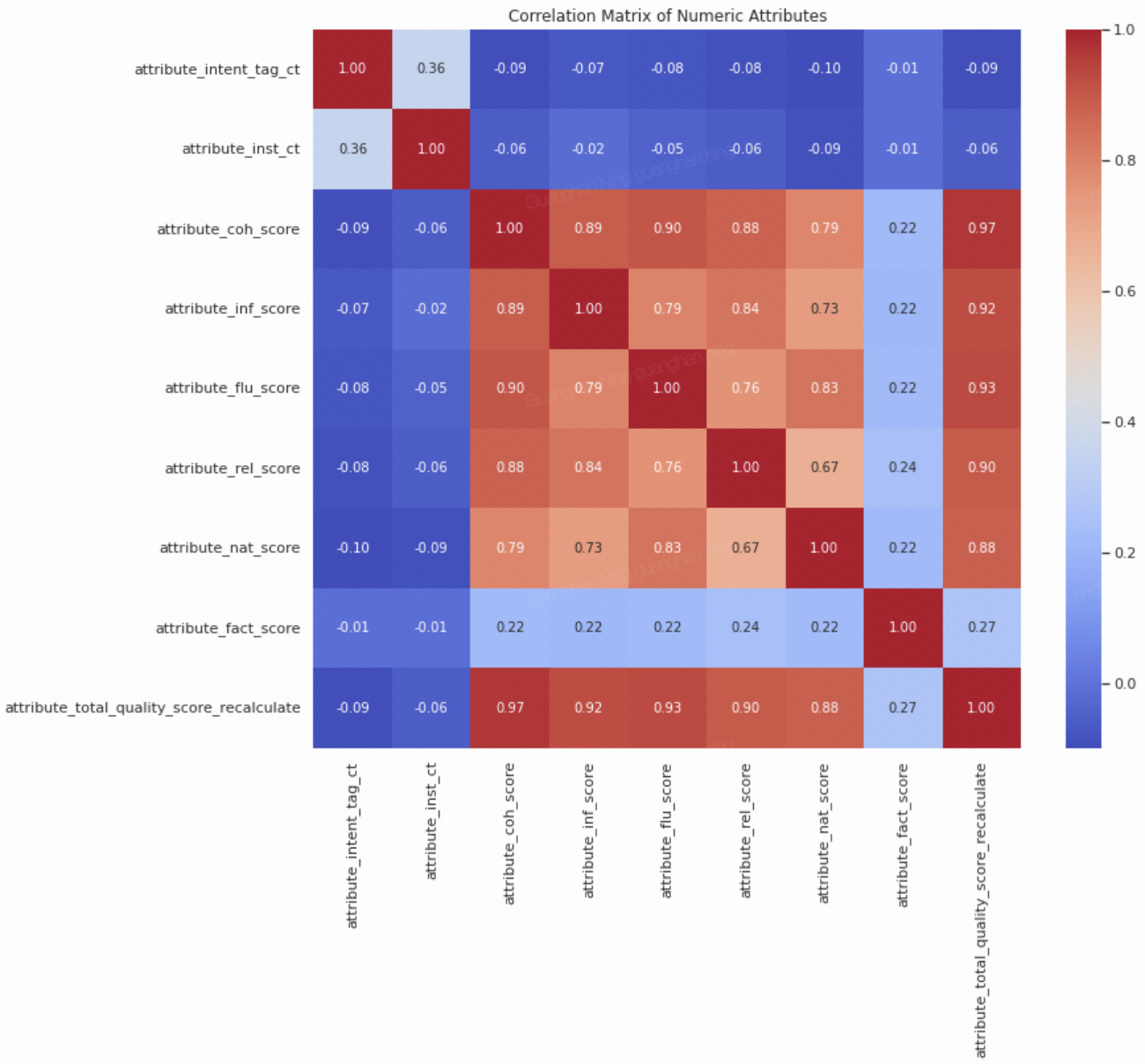
- High Correlations: attribute_total_quality_score_recalculate has a very high correlation with attribute_coh_score (0.97), attribute_inf_score (0.92), attribute_flu_score (0.93), and attribute_rel_score (0.90). This suggests that these four attributes heavily influence the overall quality score.
- Moderate Correlations: attribute_rel_score shows a decent correlation with attribute_inf_score (0.84) and attribute_flu_score (0.76).
- Low Correlations: attribute_fact_score has relatively low correlations with most other attributes.
- Insignificant Correlations: Attributes like attribute_intent_tag_ct and attribute_inst_ct have very low correlations with others.
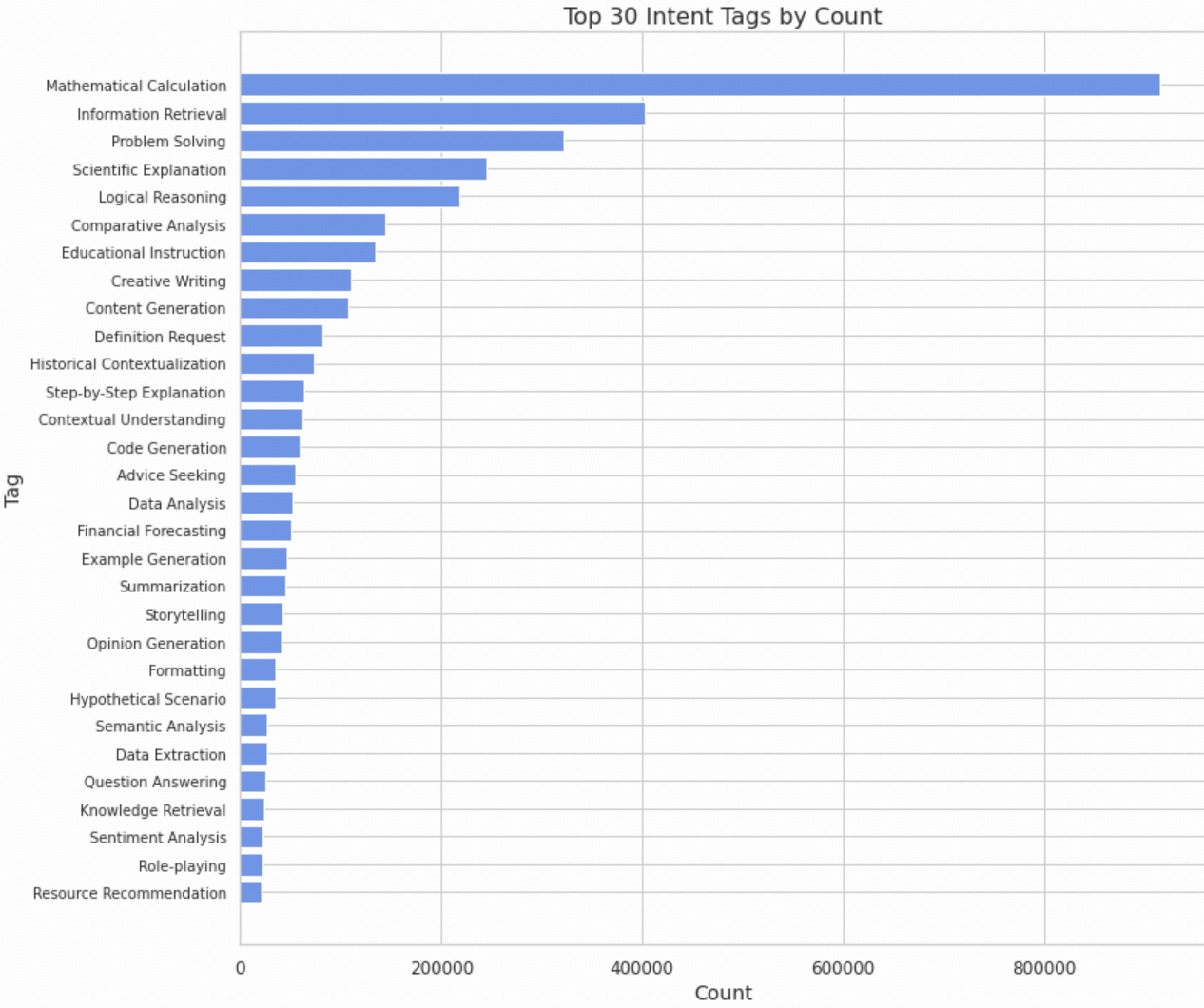
Intention Analysis
Understanding the intention behind each instruction helps us better categorize and balance the dataset. We use the InsTag algorithm to automatically assign intention tags to each instruction, enabling fine-grained analysis of what users are trying to accomplish. Some examples of intention tags are listed below:
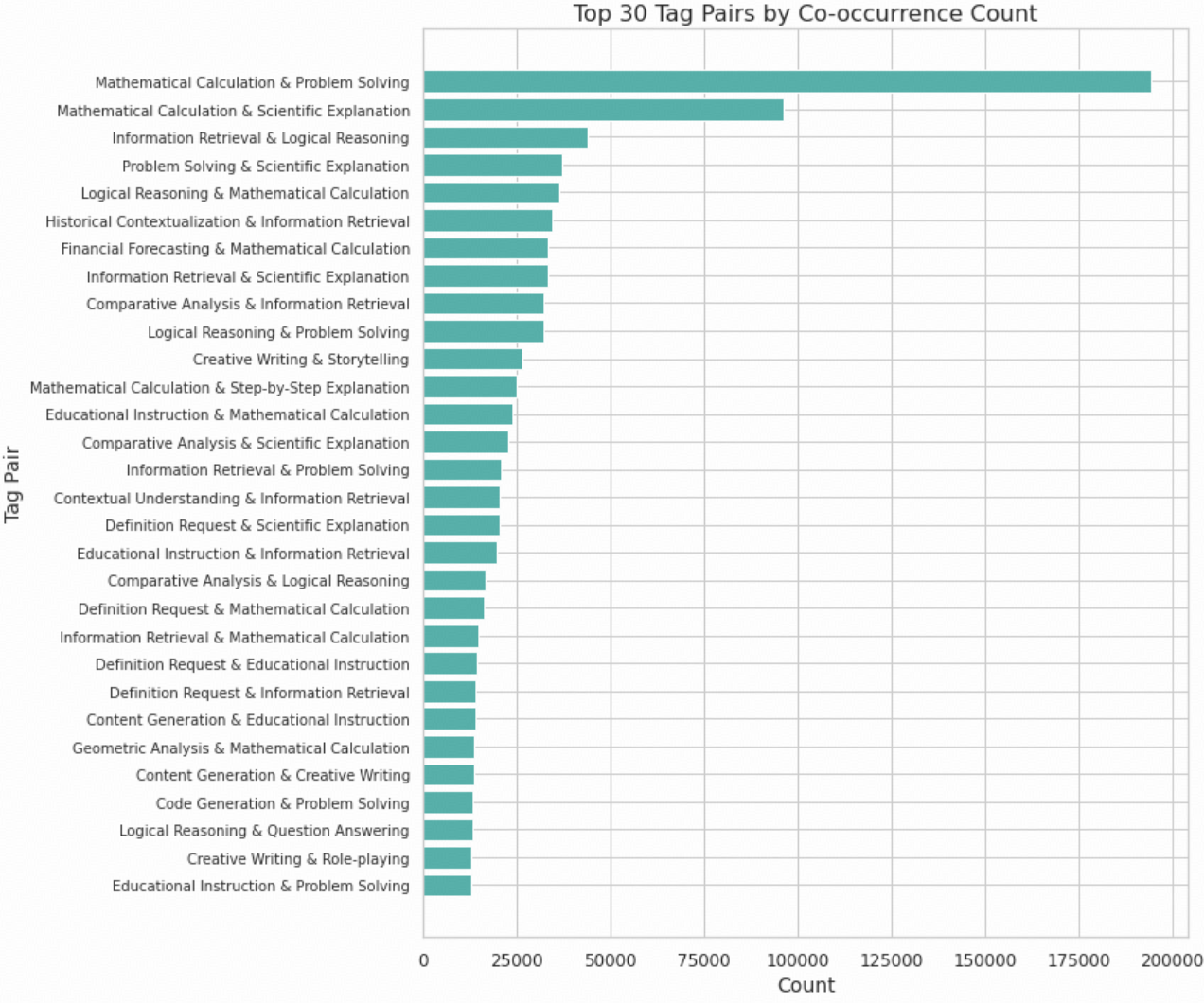
Common Tag Combinations:
Quality Analysis
We analyze the quality scores across different data sources to understand which datasets contribute higher-quality instructions. This helps inform our sampling strategy and identify potential areas for improvement.
Group analysis on Source:


We can see that on average, the instructions from WebInstructFull have the highest overall quality score. Instructions from lmsys-chat-1m have the lowest overall quality score, which is reasonable because these instructions are casual human inputs to LLMs.
Diversity Analysis
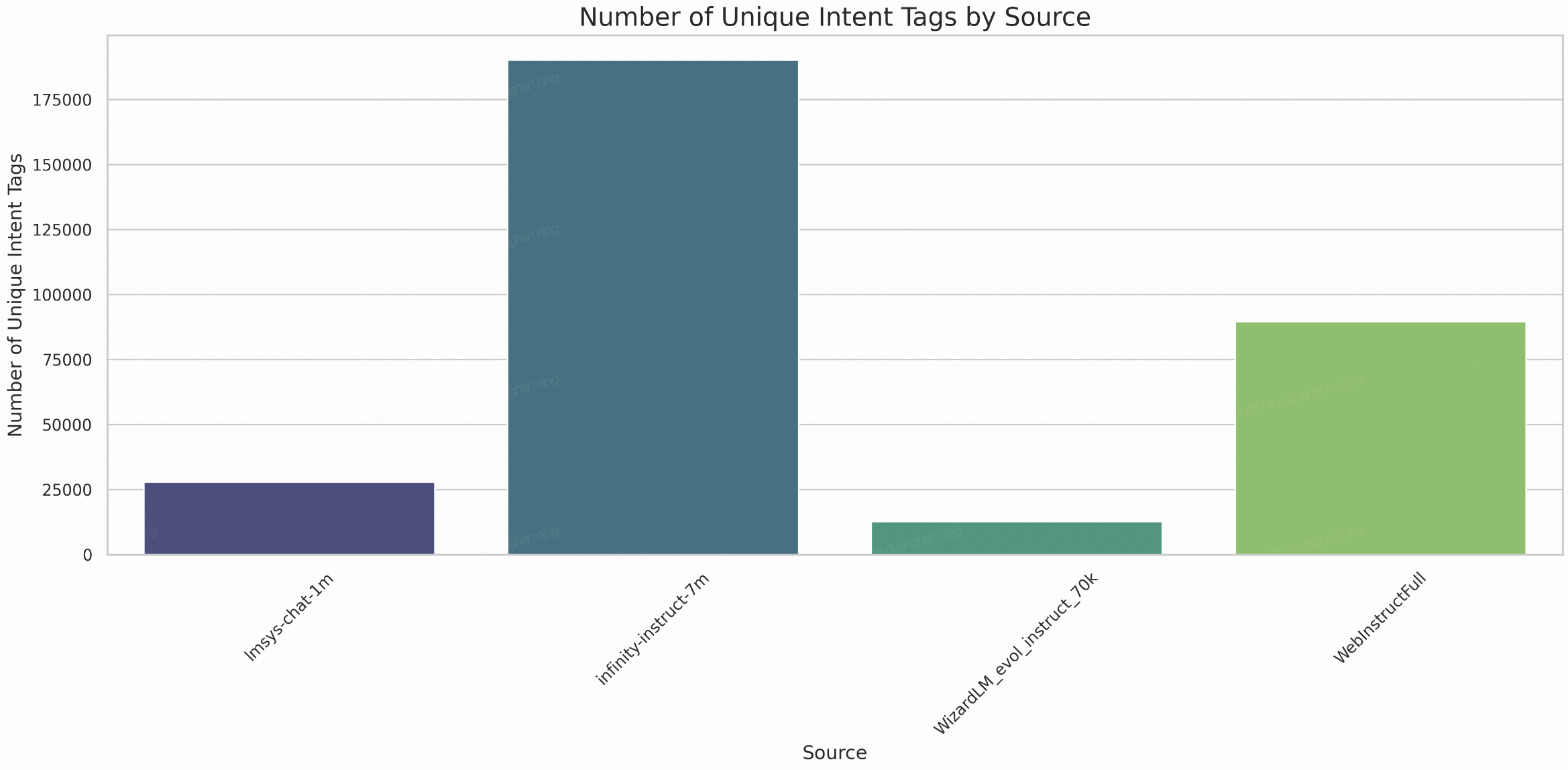
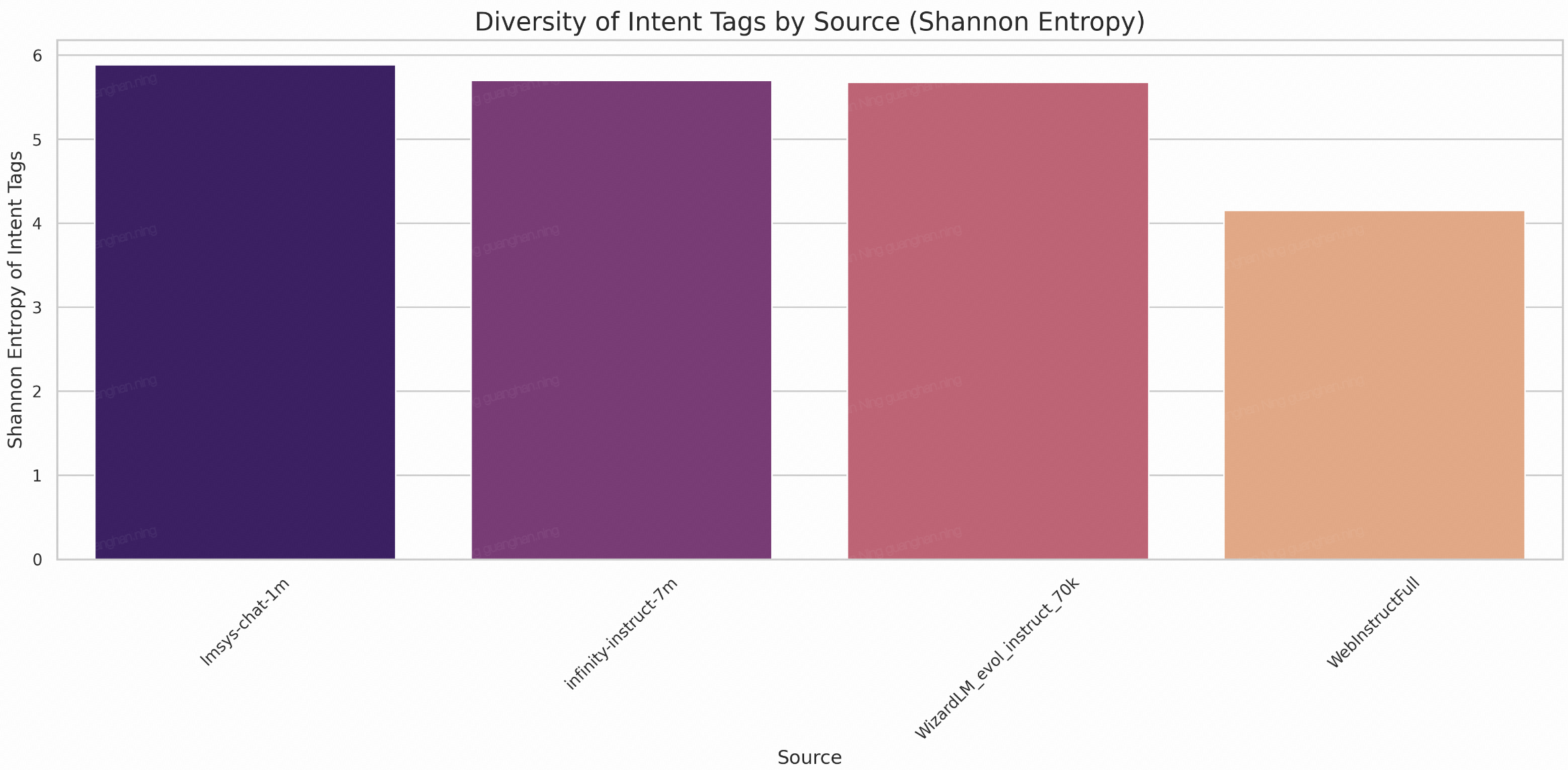
Diversity in the training data is crucial for building robust models that can handle a wide range of tasks. We measure diversity using two metrics: the number of unique intention tags and Shannon Entropy (which accounts for the balance of tag distribution).
Interestingly, although lmsys-chat-1m has a much lower number of unique intent tags than Infinity-instruct-7m, its tags are quite balanced (as we can see from the word clouds). Therefore, the diversity of tags measured by Shannon Entropy has Lmsys-chat-1m ranking first.
Word Clouds by Source:




2. Experiments
We perform SFT experiments and evaluate models with OpenBenchmarks. Based on the open-sourced Qwen2.5-Coder-7B-Base model, we train a baseline instruct model with a pre-released collection of opensourced SFT data. We then aim at beating the baseline with an in-house curated version of SFT data. Ultimately, we aim to beat Qwen2.5-Coder-7B-Instruct.
2-1. Baseline Setup
We choose Qwen2.5-Coder-7B-Base as our foundation model due to its strong coding capabilities and open-source availability. This section describes the base model’s characteristics and establishes baseline performance metrics.
2-1-1. Base Model
Based on the open-sourced Qwen2.5-Coder-7B-Base model, we train a baseline instruct model.
💻 Code More: Qwen2.5-Coder builds on the strong Qwen2.5 and continues training on a larger scale of code data, including source code, text-code grounding data, and synthetic data, totaling 5.5 trillion tokens.
📚 Learn More: While enhancing coding abilities, we aimed to retain strengths in math and general capabilities from the base model. Therefore, Qwen2.5-Coder incorporates additional data on mathematics and general abilities.
- ✨ Supporting long context understanding and generation with the context length of 128K tokens
- ✨ Supporting 92 coding languages
- ✨ Retain strengths in math and general capabilities from base model
Special tokens:
{
"<|fim_prefix|>": 151659,
"<|fim_middle|>": 151660,
"<|fim_suffix|>": 151661,
"<|fim_pad|>": 151662,
"<|repo_name|>": 151663,
"<|file_sep|>": 151664,
"<|im_start|>": 151644,
"<|im_end|>": 151645
}
If we want to compare our model against Qwen2.5-Coder-instruct on popular benchmarks, we mainly focus on these benchmarks: MMLU, ARC-Challenge, TruthfulQA, WinoGrande, HellaSwag.

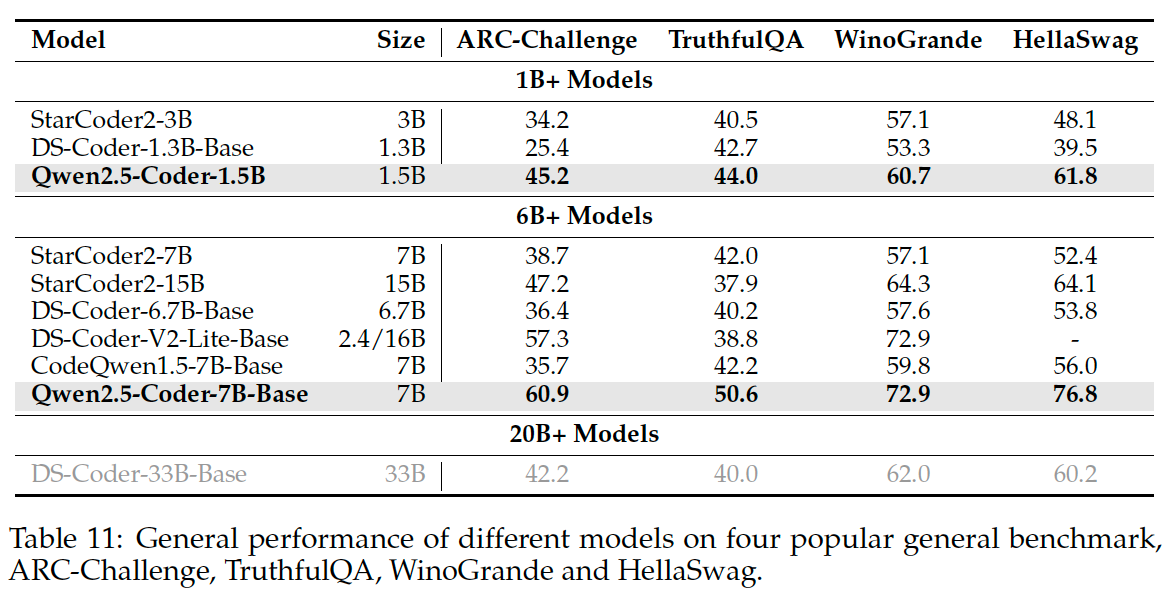
Additionally, if we want to compare general language abilities, including English, Chinese and Multilingual, we may want to compare with the Qwen 7B non-coder instruct model as well.
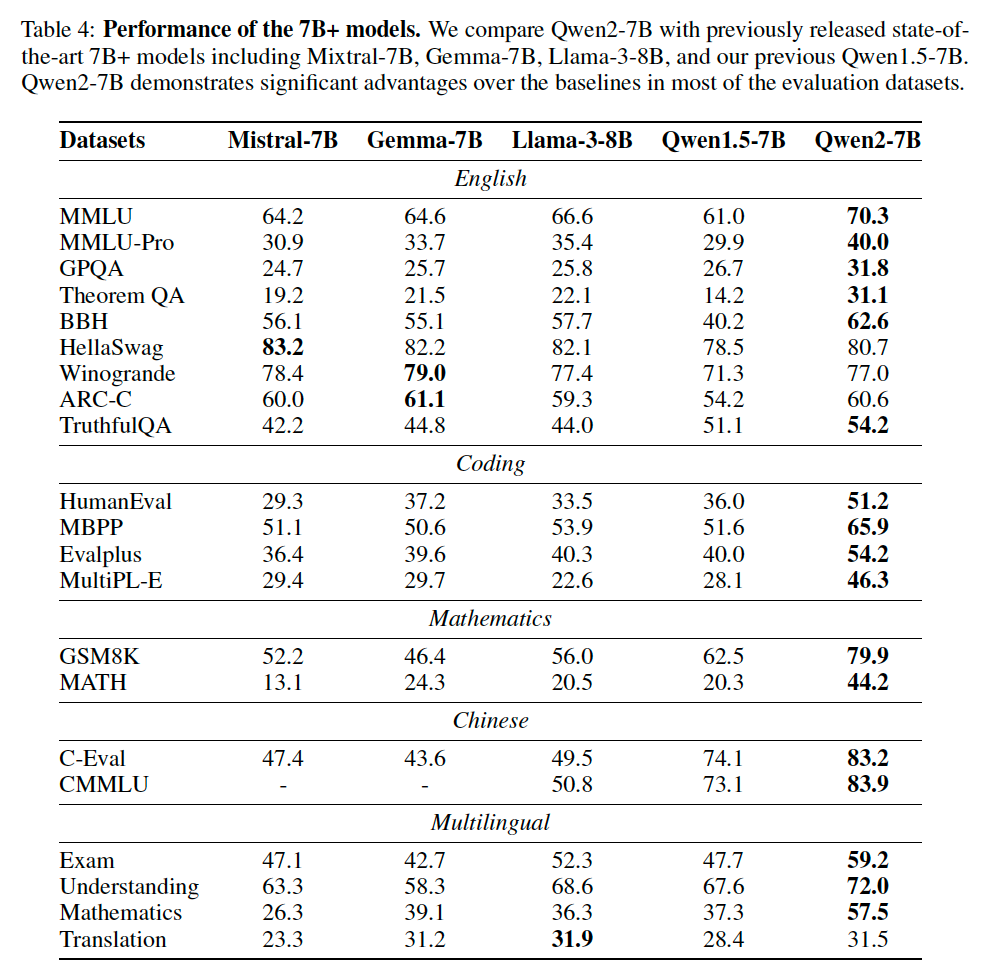
2-1-2. Data Candidates
For the baseline instruct model, we look for the best pre-released collection of opensourced SFT data.
WebInstructFull dataset helps build a baseline with strong reasoning capabilities, which is suitable for our coding LLM model. Consisting of 10 million instruction-response pairs, this dataset helps LLM improve 10%+ on MBPP and ArenaHard, 20%+ on MATH and GSM8K, respectively.
Recommended finetuning hyper-parameters for Qwen2-7B on InfinityInstruct & WebInstruct:
epoch: 3
lr: 1e-5
min_lr: 0
lr_warmup_steps: 40
lr_decay_style: cosine
weight_decay: 0.0
adam_beta1: 0.9
adam_beta2: 0.95
global_batch_size: 528
clip_grad: 1.0Benchmark Descriptions:
Natural Language, Knowledge & Reasoning
- MMLU: massive multitask language understanding. Performance has begun to plateau.
- MMLU-Pro: includes more complex and challenging reasoning questions.
- C-Eval: knowledge and reasoning in a Chinese context.
Commonsense:
- HellaSwag: commonsense natural language inference.
Instruction Following:
- IFEval: focuses on a set of “verifiable instructions” such as “write in more than 400 words” and “mention the keyword of AI at least 3 times”.
Science Knowledge:
- GPQA: PhDs with 65% accuracy; highly skilled non-expert validators with only 34% even spending 30 mins searching answers online (called “Google-Proof”).
Baseline Results:
| Model | MMLU | MMLU-Pro | IFEval | C-Eval | GPQA | HellaSwag |
|---|---|---|---|---|---|---|
Qwen2.5-Coder-7B-Base (official): Our Eval | 63.75 | 22.95 | 34.2 | 70.36 | 25.25 | 21.72 |
Qwen2.5-Coder-7B-Instruct (official): Paper | 68.7 | 45.6 | 58.6 | 61.4 | 35.6 | - |
Qwen2.5-Coder-7B-Instruct (official): Our Eval | 65.15 | 47.75 | 60.81 | 61.59 | 32.78 | 78.07 |
Qwen2.5-Coder-7B-Base-SFT-baseline (LIMA) | 63.1 | 35.4 | 29.76 | 62.85 | 29.8 | 62.07 |
Qwen2.5-Coder-7B-Base-SFT-baseline (WebInsFull) | 5.15 | 25.75 | 39.93 | 56.91 | 4.04 | 38.97 |
Qwen2.5-Coder-7B-Base-SFT-baseline (Infinity-Gen) | 65.3 | 45.1 | 63.03 | 61.66 | 31.82 | 70.31 |
Qwen2.5-Coder-7B-Base-SFT-baseline (MergeAll_sampled_2.5m) | 36 | 34.55 | 40.48 | 60.55 | 16.16 | 78.89 |
2-2. Curation Ablation
To understand the contribution of each component in our data curation pipeline, we conduct systematic ablation studies. We compare models trained on data processed through different stages of our pipeline to quantify the impact of each filtering and enhancement step.
Based on the open-sourced Qwen2.5-Coder-7B-Base model, and our curated SFT data, we aim to train a SOTA instruct model.
Ablation with Original Responses:
First, we test our curation pipeline while keeping the original responses from the source datasets:
| Procedure | Data Quantity | MMLU | MMLU-Pro | IFEval | C-Eval | GPQA | HellaSwag |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-7B-Base (official) | N/A | 63.75 | 22.95 | 34.2 | 70.36 | 25.25 | 21.72 |
| Qwen2.5-Coder-7B-Instruct (official) | N/A | 65.15 | 47.75 | 60.81 | 61.59 | 32.78 | 78.07 |
| 0. dedup+decontam+sample | 2.5m | 36 | 34.55 | 40.48 | 60.55 | 16.16 | 78.89 |
| 1. instruction quality filter | 1.7m | 29.75 | 33.45 | 39.56 | 61.96 | 20.2 | 67.94 |
Ablation with GPT-4o Responses:
Next, we replace the original responses with GPT-4o generated responses, which significantly improves model performance across all metrics:
| Procedure | Data Quantity | MMLU | MMLU-Pro | IFEval | C-Eval | GPQA | HellaSwag |
|---|---|---|---|---|---|---|---|
| 2.2m | 67.95 | 51.75 | 58.6 | 67.98 | 30.81 | 82.16 |
| 1.7m | 67.5 | 50.5 | 54.71 | 68.57 | 28.28 | 81.05 |
2.1 complexity-only filter (gpt4o response) | 152K | 55.15 | 45.85 | 48.8 | 63.22 | 30.3 | 74.74 |
| 2.2 complexity-first diversity filter (gpt4o response) | 152K | 60.95 | 44.65 | 49.72 | 63.74 | 34.34 | 79.57 |
Comparison at Same Data Size (152K):
To isolate the effect of our sampling strategy, we compare different sampling methods using the same data budget of 152K samples:
| Procedure | Data Quantity | MMLU | MMLU-Pro | IFEval | C-Eval | GPQA | HellaSwag |
|---|---|---|---|---|---|---|---|
| 2.0 random sampling (gpt4o response) | 152K | 54.4 | 43.5 | 50.46 | 64.93 | 25.25 | 78.5 |
2.1 complexity-only filter (gpt4o response) | 152K | 55.15 | 45.85 | 48.8 | 63.22 | 30.3 | 74.74 |
| 2.2 complexity-first diversity filter (gpt4o response) | 152K | 60.95 | 44.65 | 49.72 | 63.74 | 34.34 | 79.57 |
Final Results with Scaled Data:
Finally, we scale up our best sampling strategy (complexity-first diversity) to larger data sizes and compare against baselines:
| Procedure / Dataset | Data Quantity | MMLU | MMLU-Pro | IFEval | C-Eval | GPQA | HellaSwag |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-7B-Base (official) | N/A | 63.75 | 22.95 | 34.2 | 70.36 | 25.25 | 21.72 |
Qwen2.5-Coder-7B-Instruct (official): Paper | N/A | 68.7 | 45.6 | 58.6 | 61.4 | 35.6 | - |
Qwen2.5-Coder-7B-Instruct (official): Our Eval | N/A | 65.15 | 47.75 | 60.81 | 61.59 | 32.78 | 78.07 |
| complexity-first diversity (v1, k=1) | 389k | 65.3 | 49.8 | 53.23 | 67.9 | 26.77 | 79.97 |
| complexity-first diversity (v1, k=5) | 703k | 68.15 | 50.85 | 56.01 | 67.53 | 29.29 | 80.47 |
| complexity-first diversity (v2, k=1) | 1.8m | 69.45 | 52.1 | 56.93 | 65.75 | 31.31 | 81.11 |
| complexity-first diversity (v2, k=5) | 2m | 69.05 | 52.6 | 60.07 | 67.83 | 31.82 | 82.25 |
| Baseline: Infinity-Gen | 1.4m | 65.3 | 45.1 | 63.03 | 61.66 | 31.82 | 70.31 |
2-3. Full Benchmark Comparison
Our best model (General-Only) vs Qwen2.5-Coder-7B-Instruct (official)
Generic Benchmarks
| Benchmark | Qwen2.5-Coder-7B-Instruct | Ours (General-Only) | Delta |
|---|---|---|---|
| MMLU | 65.15 | 68.75 | +3.60 |
| MMLU-Pro | 47.75 | 52.05 | +4.30 |
| C-Eval | 61.59 | 66.12 | +4.53 |
| HellaSwag | 78.07 | 81.16 | +3.09 |
| IFEval | 60.81 | 61.18 | +0.37 |
| GPQA | 32.78 | 36.87 | +4.09 |
Coding Benchmarks
| Benchmark | Qwen2.5-Coder-7B-Instruct | Ours (General-Only) | Delta |
|---|---|---|---|
| AutoEval v7 | 43.77 | 46.96 | +3.19 |
| Arena Hard | 36.47 | 50.49 | +14.02 🔥 |
| HumanEval | 85.37 | 85.37 | 0 |
| MBPP | 80.40 | 75.80 | -4.60 |
| BigCode Bench | 46.32 | 48.25 | +1.93 |
| Aider Bench | 49.62 | 42.11 | -7.51 |
| LiveCode Bench | 34.50 | 39.13 | +4.63 |
Math Benchmarks
| Benchmark | Qwen2.5-Coder-7B-Instruct | Ours (General-Only) | Delta |
|---|---|---|---|
| MATH | 68.28 | 70.90 | +2.62 |
| GSM8K | 88.17 | 90.90 | +2.73 |
| Olympiad Bench | 32.89 | 39.11 | +6.22 |
| AMC 2023 | 41.75 | 52.50 | +10.75 🔥 |
| AIME 2024 | 7.33 | 6.67 | -0.66 |
Summary: Our model outperforms the official Qwen2.5-Coder-7B-Instruct on 15 out of 18 benchmarks, with particularly strong gains on Arena Hard (+14.02) and AMC 2023 (+10.75).
2-4. Analysis
In this section, we analyze the key factors contributing to our model’s performance improvements and derive insights that can guide future data curation efforts.
Diversity matters
Our experiments reveal a clear hierarchy in sampling strategies. Given the same sampling budget (a fixed number of sampled prompt-response pairs), Complexity-first diverse sampling > complexity-first sampling > random sampling.
| Procedure / Dataset | Data Quantity | MMLU | MMLU-Pro | C-Eval | HellaSwag | IFEval | GPQA |
|---|---|---|---|---|---|---|---|
| 2.0 random sampling (qsh5s response) | 150K | 54.4 | 43.5 | 64.93 | 78.5 | 50.46 | 25.25 |
| 2.1 complexity-only filter | 150K | 55.15 | 45.85 | 63.22 | 74.74 | 48.8 | 30.3 |
| 2.2 complexity-first diversity | 150K | 62.91 | 46.66 | 63.74 | 73.57 | 49.72 | 34.34 |
Scaling with complexity-first diverse sampling
We also investigate how performance scales with data quantity under our complexity-first diverse sampling strategy. The results show that more sampling budget generally leads to better performance, but not necessarily on all metrics:
Data Quantity (sampled from 9.8m) | MMLU | MMLU-Pro | C-Eval | HellaSwag | IFEval | GPQA |
|---|---|---|---|---|---|---|
| 380k (v1, k=5) | 65.3 | 48.67 | 67.89 | 78.87 | 53.23 | 26.77 |
| 700k (v1, k=20) | 68.15 | 50.85 | 67.53 | 80.47 | 56.01 | 29.29 |
| 1.8m (v2, k=1) | 69.45 | 52.1 | 65.75 | 81.11 | 56.93 | 31.82 |
| 2m (v2, k=5, bound=2m) | 69.05 | 52.6 | 67.83 | 82.25 | 60.07 | 31.82 |
| Model | Data Quantity | MMLU | MMLU-Pro | C-Eval | HellaSwag | IFEval | GPQA |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-7B-Instruct | N/A | 65.15 | 47.75 | 61.59 | 78.07 | 50.27 | 32.67 |
Ours (complexity-first diversity) | 380k (v1, k=5) | 68.15 | 50.85 | 67.53 | 80.47 | 56.01 | 29.29 |
| 700k (v1, k=20) | 68.75 | 51.58 | 66.12 | 81.16 | 61.18 | 36.87 | |
| 2m (v2, k=5, bound=2m) | 69.05 | 52.6 | 67.83 | 82.25 | 60.07 | 31.82 |
Furthermore, we discover a sampling scaling law: given the same sampling budget, the larger the source pool we sample from, the better performance we generally can achieve (though not necessarily on all metrics):
complexity-first diversity | Sampled Quantity | MMLU | MMLU-Pro | C-Eval | HellaSwag | IFEval | GPQA |
|---|---|---|---|---|---|---|---|
| sample from 2.5m | 150K (v2, k=5) | 60.86 | 44.05 | 66.74 | 79.55 | 49.72 | 34.34 |
| sample from 9.8m | 380K (v1, k=5) | 65.3 | 48.67 | 67.89 | 78.87 | 53.23 | 26.77 |
| sample from 9.8m | 1md (v1, k=5, bound = 2m) | 68.55 | 52.67 | 68.2 | 82.07 | 65.06 | 32.32 |
| sample from 18m | 1md (v1, k=5, bound = 2m) | 69.05 | 52.6 | 67.83 | 82.25 | 60.07 | 31.82 |
Stable Tag Frequency Matters
An important finding is that directly mixing data obtained through diverse sampling with other datasets (regardless of their origin) tends to result in incompatibilities. This often leads to some metrics showing improvement while others decrease—likely due to a significant shift in the frequency distribution of certain tags. The table below illustrates this phenomenon:
| Generic | MMLU | MMLU-Pro | C-Eval | HellaSwag | IFEval | GPQA |
|---|---|---|---|---|---|---|
| Qwen-2.5-coder | 65.15 | 47.75 | 61.59 | 78.07 | 50.27 | 32.67 |
| Our-SFT-Curation-1.8m | 68.75 | 51.58 | 66.12 | 81.16 | 61.18 | 36.87 |
| +inst_follow_2k(yi) | 68.8 | 53.4 | 65.70 | 63.27 | 63.32 | 41.85 |
| +inst_follow_23k | 69.55 | 53.05 | 65.9 | 81.42 | 52.5 | 36.87 |
| +inst_follow_5k | 68.95 | 51.86 | 65.82 | 81.52 | 62.66 | 36.36 |
| +inst_follow_0.5k/qa1 | 68.55 | 52.15 | 65.82 | 81.27 | 60.07 | 33.84 |
| infinity-Gen (qpt4 response) | 65.45 | 51.66 | 70.31 | 83.01 | 31.82 | - |
What tags help with GPQA and IFEval?
We further analyze which intention tags contribute to improvements on specific benchmarks. By comparing models trained on data from different source pools, we can identify the tags that are responsible for performance gains:
| Sample from | Sampled | MMLU | MMLU-Pro | C-Eval | HellaSwag | IFEval | GPQA |
|---|---|---|---|---|---|---|---|
| 9.8m | 2m (v2, k=5) | 69.05 | 52.6 | 67.83 | 82.25 | 60.07 | 31.82 |
| 18.5m | 1.8m* (v2, k=5) | 68.75 | 52.05 | 66.12 | 81.16 | 61.18 | 36.87 |
1.8m: The data was originally capped at 2m as well, but after filtering out multi-round conversations, only 1.8m was left. The other 2m was sampled from the 9.8m, which already has multi-round pruned out, so it did not suffer a quantity reduction.
Analysis: Depending on the analysis, the improvement of the GPQA metric is mainly due to the frequency uplift of science-related tags, including the following:
Tags contributing to GPQA improvement: Geographical Location, Result Rounding, Financial Data Analysis, Word Limit Specification, Kinematics Problem, Interpretation of Results, Literary Explanation, Chemical Reaction Explanation, Game Theory, Matrix Analysis, Psychological Explanation, Physical Science Problem, Entity Relationship Analysis, Electrostatics Problem, Polynomial Root Finding, Production Analysis, Graphical Illustration, Vector-Valued Function
The newly-added tags, however, are fairly low in value, not the main factor in contributing to performance improvement.
3. Conclusions
Based on our extensive experiments, we summarize the key findings from this SFT data curation study:
- The effectiveness of complexity-first diverse sampling has been validated.
- A diversified sampling method based on a fine-grained open-label system (rather than a top-down, comprehensive label system built on prior knowledge) can also achieve good results.
- Properly sampled data is superior to using the full dataset.
- Complexity-first diverse sampling > complexity-first sampling > random sampling.
- Through ablation experiments, a sampling scaling law was discovered: under the settings of this method, the larger the total source dataset, the better the performance of the sampled data of the same size.
- Under the premise of ensuring diversity, the complexity-first method inherently prioritizes code and mathematical elements (sampling results: code of any form/mathematical calculations/others = 26.74%/35.23%/38.03%).